

近日,在北京大学校友创业联合会2024创新论坛上,北京大学王选计算机研究所书记&研究员赵东岩带来《预训练语言模型应用前景分析》的分享。
头部科技长期深度聚焦人工智能产业技术革新与应用深化,我们将持续整理头部专家观点进行发布,以飨读者。我们也将陆续推出头部对话、头部探访、头部案例等专栏,请大家持续关注。

赵东岩,北京大学王选计算机研究所书记&研究员,博士生导师,国务院特殊津贴获得者。
主要研究方向为自然语言处理、语义数据管理、智能服务技术。
近年来承担国家自然科学基金、AI 2030和重点研发计划等国家级项目17项、主持8项,担任2030新一代人工智能重大项目负责人(首席专家);发表学术论文200余篇(包括ACL、ICML、AAAI,AI Journal等CCF A类会议和期刊80余篇);授权发明专利23项;先后七次获得国家和省部级奖励,包括 2006年度国家科技进步二等奖(排名第一);个人获第十届中国青年科技奖(2007年)等荣誉。
中国计算机学会(CCF)杰出会员。

以下为本次演讲实录


尊敬的各位嘉宾、校友们,大家好!
今天,我将从三个方面展开讨论:大模型的基本情况、发展前景以及未来可能的创新和突破方向。
首先,我们明确一下「大模型」这个概念。
大规模预训练语言模型(Pre-trained Language Model, PLM),是一种用于处理文本的自然语言处理技术。
在今天的讨论中,我们将涉及三个核心概念:PLM、LLM(Large Language Model)和LMM(Multimodal Large Model)。
语言模型(LM)是提高机器语言智能的主要方法之一,语言建模的研究此前最受关注的是预训练语言模型(PLM)。
然而随着2022年11月ChatGPT的发布,大语言模型(LLM),简称大模型开始进入公众视野,成为研究热点。简单来说,大模型就是扩展的PLM,扩展的是模型大小以及数据大小。
LLM主要依赖文本数据进行训练,通常采用Transformer等深度学习结构,专注于处理和理解自然语言文本。相比之下,大型多模态语言模型(LMM)则是一种更为复杂和全面的模型,它不仅处理文本数据,还融合了图像、音频、视频等多种模态的数据进行训练,可以用于处理更为复杂和多样化的任务,如图像标注、视频描述、音频识别等。(编者按)
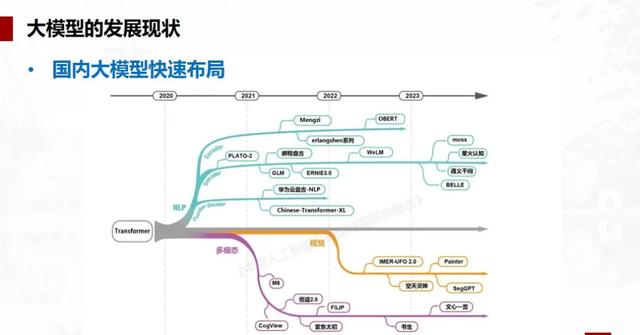
大模型之所以被称为「大」,是因为其规模之大。从Google的BERT和OpenAI的GPT开始,模型的参数量已从最初的1亿增长到现在的千亿甚至万亿级别,发展速度惊人。
这一增长得益于所谓的「Scaling laws」,即模型的效果会随着参数量、数据集和计算量的指数级增加而线性提高。然而,这种增长并非无止境,面临数据获取的天花板,以及能耗的现实约束。
值得注意的是,GPT系列的发展显示,模型的训练方法创新比单纯增加参数量更能带来突破,如ChatGPT的火爆正是得益于训练方式的变革。
尽管如此,大模型在多个方面取得了显著的进步。例如,对话能力的提升,特别是在多轮对话中,回复的质量和逻辑一致性得到了加强;知识问答能力的普遍提升,使得大模型能够回答包括复杂专业数学问题在内的各种问题;文本生成能力的提升,尤其是长文本生成的流畅度方面。
然而,大模型也面临着一系列挑战。它们在特定的自然语言处理任务上往往不如专门训练的小模型表现优异。
此外,大模型也暴露了一些问题,如缺乏特定知识、知识更新滞后、幻觉现象、高成本等。这些问题凸显了大模型作为黑盒模型的不可解释性。
为了克服这些障碍,我们需要在知识注入方面作出努力,解决专业领域的知识不足、知识更新慢、臆想答案幻觉以及知识来源引用等问题。我们探索了如RAG(Retrieval-Augmented Generation)这样的技术,通过增强模型的知识检索能力来提高答案的准确性和可靠性。然而,RAG也存在其局限性,如检索不到信息、信息提取难等问题。
未来,大模型不会取代人类,而是成为人类的助手。在应用方面,大模型将主要服务于个人服务和行业领域。然而,运行成本、领域和业务数据、知识注入以及应用生态和商业模式是当前的主要障碍。

接下来,我谈到了几个未来趋势。
首要的是领域落地,行业应用是大模型能否持续发展的关键,这需要知识的精准注入。
开源模型生态的建立对于构建健康的大模型生态至关重要,它允许不同规模的企业和个人参与到AI的创新中,打破垄断,促进技术普及,有助于形成一个健康的AI生态系统。开源模型如Llama 3为中小企业提供了行业应用的底座模型,性能也越来越接近同期的闭源模型。
我们期待头部公司提供基座模型,中小企业专注领域模型,开发者贡献定制化方案,形成千行百业的AI生态。
「以小为美」是另一个趋势,随着资源消耗和效率考虑,开发高效、高质量的小模型变得尤为重要。
令人鼓舞的是,现有的一些小模型已经展示出接近或超越大模型的性能,同时具有更好的可控性,减轻了幻觉问题。多模态大模型的探索也是未来的重要方向,尤其是如何更好地实现模态间语义对齐。
至于创新和突破方向,我们需要建立一套全面的大模型评测体系,确保模型不仅会「刷题」,而且真正智能。基于知识的归纳、推理和融合是关键,能够推动大模型从数据驱动向知识加数据驱动转变。
此外,我们需要建立完善的模型能力评测体系优化,模型结构、计算的轻量化,以及多源实体数据的增强,都是未来研究的热点。
我们期望通过可解释AI、交互式学习和具身智能的研究,使通用人工智能迈向质的飞跃。
最后,我们在现有技术基础上进行着不断地创新,如知识融合和轻量化模型结构改进的探索,推动AI技术边界等。大模型的发展虽面临挑战,但前景光明,未来值得期待。
感谢大家的聆听,我相信大模型的发展将为我们带来更多的可能性和挑战。让我们一起期待并参与这一激动人心的旅程。
如果您有什么想说的,欢迎在评论区留言讨论!如果您有新鲜观点或者观察,也欢迎私信“投稿”,进行投稿。
如果您想要获取最新的科技趋势分析、行业内部的独家见解、定期的互动讨论和知识分享、与行业专家的直接面对面交流的机会!
欢迎扫描下方二维码,加头部科技创始人、AI头号玩家俱乐部主理人张晶晶微信!

头部视野3
