
阿里妹导读
本文主要讲述了Java字符串拼接技术的演进历程,以及阿里巴巴贡献的最新实现 PR 20273。
0. 写在前面的省流版
下图是Java字符串拼接实现的技术演进路线,最新的实现 PR 20273是来自阿里巴巴的贡献。

1. 关于使用"+"做字符串拼接
一些古老的技术文章中会说,在Java中使用"+"做字符串拼接性能不好,但实际情况是JDK 9+之后的版本,使用"+"做字符串拼接会比StringBuilder快。
如下是一个字符串拼接的的方法,我们基于这个方法来介绍JDK8和JDK9之后版本的性能以及背后的内部细节。
class Demo { public static String concatIndy(int i) { return "value " + i; }}2. JDK 8下的字符串拼接实现
2.1 编译并查看字节码
jdk8/bin/javac Demo.java jdk8/bin/javap -c Demjavap输出的字节码:
class Demo { Demo(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return public static java.lang.String concatIndy(int); Code: 0: new #2 // java/lang/StringBuilder 3: dup 4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V 7: ldc #4 // String value 9: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 12: iload_0 13: invokevirtual #6 // Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder; 16: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 19: areturn}2.2 反编译后的Java代码
public static String concatIndy(int i) { return new StringBuilder("value ") .append(i) .toString();}可以看出,在JDK 8中,在非循环体内使用"+"实现字符串拼接和使用StringBuilder是一样的,用"+"做拼接代码更简洁,推荐使用"+"而不是StringBuilder。
3. JDK 9之后的字符串拼接实现 (JEP 280)
如果我们使用JDK 9之后的版本,比如JDK 11,字符串拼接"+"编译后的字节码会不一样。
3.1. 使用JDK 11编译后并查看字节码
jdk11/bin/javac Demo.java jdk11/bin/javap -c Demo Demo { Demo(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return public static java.lang.String concatIndy(int); Code: 0: iload_0 1: invokedynamic #2, 0 // InvokeDynamic #0:makeConcatWithConstants:(I)Ljava/lang/String; 6: areturn}可以看到,JDK 11中编译后的字节码和JDK 8是不一样的,不再是基于StringBuilder实现,而是基于StringConcatFactory.makeConcatWithConstants动态生成一个方法来实现。这个会比StringBuilder更快,不需要创建StringBuilder对象,也会减少一次数组拷贝。
这里由于是内部使用的数组,所以用了UNSAFE.allocateUninitializedArray的方式更快分配byte[]数组。通过:
StringConcatFactory.makeConcatWithConstants
而不是JavaC生成代码,是因为生成的代码无法使用JDK的内部方法进行优化,还有就是,如果有算法变化,存量的Lib不需要重新编译,升级新版本JDk就能提速。
这个字节码相当如下手工调用:
StringConcatFactory.makeConcatWithConstants
import java.lang.invoke.*; static final MethodHandle STR_INT; static { try { STR_INT = StringConcatFactory.makeConcatWithConstants( MethodHandles.lookup(), "concat_str_int", MethodType.methodType(String.class, int.class), "value \1" ).dynamicInvoker(); } catch (Exception e) { throw new Error("Bootstrap error", e); } } static String concat_str_int(int value) throws Throwable { return (String) STR_INT.invokeExact(value); }StringConcatFactory.makeConcatWithConstants是公开API,可以用来动态生成字符串拼接的方法,除了编译器生成字节码调用,也可以直接调用。调用生成方法一次大约需要1微秒(千分之一毫秒)。
3.2. makeConcatWithConstants动态生成方法的代码makeConcatWithConstants使用recipe ("value \1")动态生成的方法大致如下:
import java.lang.StringConcatHelper;import static java.lang.StringConcatHelper.mix;import static java.lang.StringConcatHelper.newArray;import static java.lang.StringConcatHelper.prepend;import static java.lang.StringConcatHelper.newString;public static String invokeStatic(String str, int value) throws Throwable { long lengthCoder = 0; lengthCoder = mix(lengthCoder, str); lengthCoder = mix(lengthCoder, value); byte[] bytes = newArray(lengthCoder); lengthCoder = prepend(lengthCoder, bytes, value); lengthCoder = prepend(lengthCoder, bytes, str); return newString(bytes, lengthCoder);}StringConcatHelperStringConcatHelper是:
StringConcatFactory.makeConcatWithConstants实现用到的内部类。
package java.lang;class StringConcatHelper { static String newString(byte[] buf, long indexCoder) { // Use the private, non-copying constructor (unsafe!) if (indexCoder == LATIN1) { return new String(buf, String.LATIN1); } else if (indexCoder == UTF16) { return new String(buf, String.UTF16); } }}public String { String(byte[] value, byte coder) { // 无拷贝构造 this.value = value; this.coder = coder; }}可以看出,生成的方法是通过如下步骤来实现:
StringConcatHelper的mix方法计算长度和字符编码 (将长度和coder组合放到一个long中);根据长度和编码构造一个byte[];然后把相关的值写入到byte[]中;使用byte[]无拷贝的方式构造String对象。
上面的火焰图可以看到实现的细节。这样的实现,和使用StringBuilder相比,减少了StringBuilder以及StringBuilder内部byte[]对象的分配,可以减轻GC的负担。也能避免可能产生的StringBuilder在latin1编码到UTF16时的数组拷贝。
-StringBuilder缺省编码是LATIN1(ISO_8859_1),如果append过程中遇到UTF16编码,会有一个将LATIN1转换为UTF16的动作,这个动作实现的方法是inflate。如果拼接的参数如果是带中文的字符串,使用StringBuilder还会多一次数组拷贝。
class AbstractStringBuilder private void inflate() { if (!isLatin1()) { return; } byte[] buf = StringUTF16.newBytesFor(value.length); StringLatin1.inflate(value, 0, buf, 0, count); this.value = buf; this.coder = UTF16; }} 3.3 JMH比较字符串拼接和使用StringBuilder的性能测试代码public ConcatBench { public static String concatIndy(int i) { return "value " + i; } public static String concatSB(int i) { return new StringBuilder("value ") .append(i) .toString(); }}JDK 11下的测试结果Benchmark Mode Cnt Score Error UnitsConcatBench.concatIndy thrpt 5 130.841 ± 1.127 ops/usConcatBench.concatSB thrpt 5 117.897 ± 1.437 ops/us
3.3 JMH比较字符串拼接和使用StringBuilder的性能测试代码public ConcatBench { public static String concatIndy(int i) { return "value " + i; } public static String concatSB(int i) { return new StringBuilder("value ") .append(i) .toString(); }}JDK 11下的测试结果Benchmark Mode Cnt Score Error UnitsConcatBench.concatIndy thrpt 5 130.841 ± 1.127 ops/usConcatBench.concatSB thrpt 5 117.897 ± 1.437 ops/us上面的数据中,concatIndy是使用字符串拼接,concatSB是使用StringBuilder,可以看出在JDK 11下,使用"+"拼接字符串的性能比使用StringBuilder快10.97%。
4. StringConcatFactory的实现细节
以及阿里巴巴的贡献
4.1 基于MethodHandlers API的实现StringConcatFactory.makeConcatWithConstants是MethodHandles实现的。MethodHandle可以是一个方法引用,MethodHandles可以对MethodHandle做各种转换,包括过滤参数[filterAgument]、参数折叠[foldArgument]、添加参数[insertArguments],最终生成的MethodHandle可以被认为是一个语法树。MethodHandles API功能强大,甚至可以认为它是图灵完备的。当然也有缺点,复杂的MethodHandle TreeExpress会生成大量中的中间类,JIT的开销也较大。
StringConcatFactory.makeConcatWithConstants通过MethodHandles动态构建一个MethodHandle调用StringConcatHelper的方法,组装一个MethodHandle实现无拷贝的字符拼接实现。
package java.lang;class StringConcatHelper { static long initialCoder() { ... } // T: boolean, char, int, long, String static long mix(long lengthCoder, T value) { ... } static byte[] newArray(long indexCoder) { ... } static long prepend(long lengthCoder, byte[] buf, T value) { ... } static String newString(byte[] buf, long indexCoder) { ... }}class StringConcatFactory { static MethodHandle generateMHInlineCopy(MethodType mt, String[] constants) { Class<?>[] ptypes = mt.erase().parameterArray(); MethodHandle mh = MethodHandles.dropArgumentsTrusted(newString(), 2, ptypes); .. mh = filterInPrependers(mh, constants, ptypes); .. MethodHandle newArrayCombinator = newArray(); mh = MethodHandles.foldArgumentsWithCombiner(mh, 0, newArrayCombinator, 1 // index ); .. mh = filterAndFoldInMixers(mh, initialLengthCoder, ptypes); if (objFilters != null) { mh = MethodHandles.filterArguments(mh, 0, objFilters); } return mh; }}4.2 基于MethodHandle表达式的问题这种动态生成MethodHandle表达式在参数个数较多时,会遇到问题,它会生成大量中间转换类,并且生成MethodHandle消耗比较大,极端情况下,C2优化器需要高达2G的内存来编译复杂的字符串拼接:
https://github.com/openjdk/jdk/pull/18953
因此JDK 23引入了JVM启动参数java.lang.invoke.StringConcat.highArityThreshold,缺省值为20,当超过这个阈值时,使用StringBuilder实现。
除了参数个数较多时编译消耗资源多之外,MethodHandle表达式还有启动速度比较慢的问题。
4.3 阿里巴巴贡献的改进 (PR 20273)阿里巴巴的工程师温绍锦在2024年7月提交了一个新的方案:
https://github.com/openjdk/jdk/pull/20273
通过动态字节码生成隐藏类来代替基于MethodHandle表达式的实现。它的实现逻辑和MethodHandle表达式类似,但不需要组合coder和length,有相似的运行性能,但它能显著提升启动性能,并且对C2优化器的开销较小。
在8月5日召开的JVM Language Summit 2024,Oracle Java核心类库维护小组负责性能优化的Claes Redestad的Talk:
《Re-thinking String Concatenation》 :
https://www.youtube.com/watch?v=tgX38gvMpjs&list=PLX8CzqL3ArzUEYnTa6KYORRbP3nhsK0L1&index=1
介绍了PR 20273 ,这个将会是JDK 24的缺省实现。

如下是PR 20273前后的代码实现对比:

上图右边的字节码会用下面的代码生成一个Hidden Class来实现字符串拼接。
package java.lang.invoke;class StringConcatFactory { static final InlineHiddenClassStrategy { static MethodHandle generate(Lookup lookup, MethodType args, String[] constants) { byte[]Bytes = ClassFile.of().build(...); var hiddenClass = lookup.makeHiddenClassDefiner(CLASS_NAME,Bytes, Set.of(), DUMPER) .defineClass(true, null); var constructor = lookup.findConstructor(hiddenClass, CONSTRUCTOR_METHOD_TYPE); var concat = lookup.findVirtual(hiddenClass, METHOD_NAME, concatArgs); var instance = hiddenClass.cast(constructor.invoke(constants)); return concat.bindTo(instance); } }}如下图,PR 20273的实现生成的中间类明显减少:
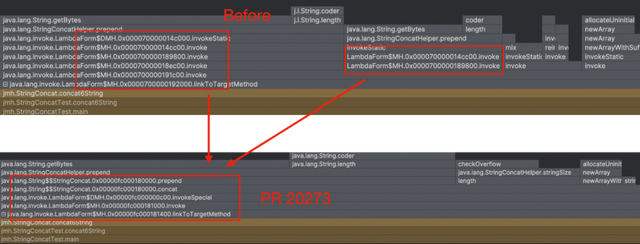
PR 20273生成的ByteCode逻辑大致如下:
java.lang.StringConcatHelper中的基类 StringConcatBase。package java.lang;class StringConcatHelper { static abstract StringConcatBase { @Stable final String[] constants; final int length; final byte coder; StringConcatBase(String[] constants) { int length = 0; byte coder = String.LATIN1; for (String c : constants) { length += c.length(); coder |= c.coder(); } this.constants = constants; this.length = length; this.coder = coder; } }}生成的代码。import static java.lang.StringConcatHelper.newArrayWithSuffix; import static java.lang.StringConcatHelper.prepend; import static java.lang.StringConcatHelper.stringCoder; import static java.lang.StringConcatHelper.stringSize; StringConcat extends java.lang.StringConcatHelper.StringConcatBase { // super defines // String[] constants; // int length; // byte coder; StringConcat(String[] constants) { super(constants); } String concat(int arg0, long arg1, boolean arg2, char arg3, String arg4, float arg5, double arg6, Object arg7 ) { // Types other than byte/short/int/long/boolean/String require a local variable to store String str4 = stringOf(arg4); String str5 = stringOf(arg5); String str6 = stringOf(arg6); String str7 = stringOf(arg7); int coder = coder(this.coder, arg0, arg1, arg2, arg3, str4, str5, str6, str7); int length = length(this.length, arg0, arg1, arg2, arg3, arg4, arg5, arg6, arg7); String[] constants = this.constants; byte[] buf = newArrayWithSuffix(constants[paramCount], length. coder); prepend(length, coder, buf, constants, arg0, arg1, arg2, arg3, str4, str5, str6, str7); return new String(buf, coder); } static int length(int length, int arg0, long arg1, boolean arg2, char arg3, String arg4, String arg5, String arg6, String arg7) { return stringSize(stringSize(stringSize(stringSize(stringSize(stringSize(stringSize(stringSize( length, arg0), arg1), arg2), arg3), arg4), arg5), arg6), arg7); } static int cocder(int coder, char arg3, String str4, String str5, String str6, String str7) { return coder | stringCoder(arg3) | str4.coder() | str5.coder() | str6.coder() | str7.coder(); } static int prepend(int length, int coder, byte[] buf, String[] constants, int arg0, long arg1, boolean arg2, char arg3, String str4, String str5, String str6, String str7) { // StringConcatHelper. prepend return prepend(prepend(prepend(prepend( prepend(apppend(prepend(prepend(length, buf, str7, constant[7]), buf, str6, constant[6]), buf, str5, constant[5]), buf, str4, constant[4]), buf, arg3, constant[3]), buf, arg2, constant[2]), buf, arg1, constant[1]), buf, arg0, constant[0]); }}从这个代码来看,由于采用非静态的字段来保存constants,这使得可以重用。和之前MH实现不同的是,没有将coder和length组合成一个long类型的lengthcoder,这使得C2优化器在内联是可以做优化处理。这样就兼顾了性能和可重用。
4.4 PR 20273带来的启动性能提升显著
(具体细节看 PR 20273的comments)
5. 阿里巴巴对字符串拼接的其他贡献
除了PR 20273这样大的改进之外,阿里巴巴还贡献了其他对字符串连接改进,包括:
5.1 PR 20253 Optimize StringConcatHelper.simpleConcatPR地址:https://github.com/openjdk/jdk/pull/20253
这个PR改进了非简单类型的单参数字符串拼接性能,通过简化计算coder和length的算法提升性能大约8%。
5.2 PR 19730 Reduce object allocation for FloatToDecimal and DoubleToDecimalPR地址:https://github.com/openjdk/jdk/pull/19730
这个PR通过消除过程中的内存分配提升float/double类型:
toString和StringBuilder.append(float/double)的性能。
测试表明性能显著提升:
-Benchmark Mode Cnt Score Error Units base-StringBuilders.appendWithFloat8Latin1 avgt 15 317.144 ? 11.325 ns/op-StringBuilders.appendWithFloat8Utf16 avgt 15 316.980 ? 17.955 ns/op-StringBuilders.appendWithDouble8Latin1 avgt 15 440.853 ? 13.067 ns/op-StringBuilders.appendWithDouble8Utf16 avgt 15 418.896 ? 4.610 ns/op+Benchmark Mode Cnt Score Error Units (Webrevs 00 4c810154)+StringBuilders.appendWithFloat8Latin1 avgt 15 168.231 ? 4.749 ns/op +88.51%+StringBuilders.appendWithFloat8Utf16 avgt 15 213.981 ? 3.274 ns/op +48.13%+StringBuilders.appendWithDouble8Latin1 avgt 15 241.536 ? 0.993 ns/op +82.52%+StringBuilders.appendWithDouble8Utf16 avgt 15 284.863 ? 10.381 ns/op +47.05%5.3 PR 14699 Optimization for Integer.toString
PR地址:https://github.com/openjdk/jdk/pull/14699
这个PR提升Integer/Long.toString以及StringBuilder.append(int/long)的性能,这个PR通过将两次求值和写入合并为一次提升性能,在JDK 22之后的版本被引入。

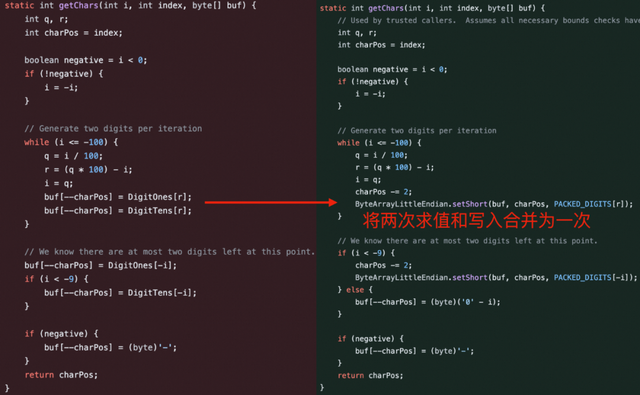
测试表明性能提升显著:
-Benchmark (size) Mode Cnt Score Error Units (baseline)-Integers.toStringBig 500 avgt 15 18.483 ± 2.771 us/op-Integers.toStringSmall 500 avgt 15 4.435 ± 0.067 us/op-Integers.toStringTiny 500 avgt 15 2.382 ± 0.063 us/op+Benchmark (size) Mode Cnt Score Error Units (PR Update 20 c0f42a7c)+Integers.toStringBig 500 avgt 15 5.392 ? 0.016 us/op (+242.78%)+Integers.toStringSmall 500 avgt 15 3.201 ? 0.024 us/op (+38.55%)+Integers.toStringTiny 500 avgt 15 2.141 ? 0.021 us/op (+11.25%)-Benchmark (size) Mode Cnt Score Error Units (baseline)-Longs.toStringBig 500 avgt 15 8.336 ± 0.025 us/op-Longs.toStringSmall 500 avgt 15 4.389 ± 0.018 us/op+Benchmark (size) Mode Cnt Score Error Units (PR Update 20 c0f42a7c)+Longs.toStringBig 500 avgt 15 7.706 ? 0.015 us/op (+8.17%)+Longs.toStringSmall 500 avgt 15 3.094 ? 0.021 us/op (+41.85%)-Benchmark Mode Cnt Score Error Units (baseline)-StringBuilders.toStringCharWithInt8 avgt 15 124.316 ± 61.017 ns/op+Benchmark Mode Cnt Score Error Units (PR Update 20 c0f42a7c)+StringBuilders.toStringCharWithInt8 avgt 15 44.497 ? 29.741 ns/op (+179.38%)5.4 在字符串处理非拼接相关的其他贡献
PR 14578 优化UUID.toString的性能;PR 14751 优化String的UpperLower性能;PR 15768 优化HexFormat.formatHex的性能;PR 15776 优化String.format的性能;PR 19513 优化java.text.Format的性能;还有其他一些较小的改进,就不一一罗列了。
6. 总结
1. 在JDK 8中,使用"+"拼接字符串性能的性能是和直接使用StringBuilder是一样的。
2. 升级JDK 11后,将compiler.target修改为11,使用"+"拼接字符串性能会比StringBuilder更好,耗时和GC都会变少。
3. JDK 11 ~ JDK23版本的字符串拼接,参数个数较多时的字符串拼接,存在启动速度慢和JIT C2消耗资源多的问题。
4. 阿里巴巴提供了新的实现PR 20273,在保证运行性能的同时,解决了启动速度慢和可重用的问题,这个将会在JDK 24中引入,成为Java"+"运算符字符串拼接的缺省实现。
5. 除了PR 20273之外,阿里巴巴还做了大量的OpenJDK其他的贡献,包括对GC、JIT、Runtime、RAS,以及核心类库等的改进,例如RISC-V架构支持、VectorAPI、Primitive Types类型和各种场景字符串处理性能改进等等。
