我们可以通过多种方式来扩展计算引擎的内存容量和内存带宽,从而更好地驱动 AI 和 HPC 工作负载,而目前我们能够做到的还远远不够。但是,我们可能做的任何事情(目前有许多有趣的光学 I/O 选项可供选择)都必须具有可制造性和成本效益,才能采用新的内存方法。
否则,它就不会被采纳,也不可能被采纳。
这就是我们现在遇到的 HBM 瓶颈的原因。一小部分非常昂贵的 HPC 和 AI 工作负载受限于内存带宽,它们将大量并行 HBM 内存堆栈放置在非常靠近计算引擎的位置。HBM 无法同时提高内存容量和内存带宽——只能拥有其中一种。
HBM很好,很缺
HBM 内存比使用常规 DRAM 好得多,对于带宽是关键的计算引擎来说,HBM 内存也比 GDDR 好,但即使美光科技与 SK 海力士和三星一起加入 HBM 阵营,世界也无法生产足够的这种产品来满足需求。这反过来又导致高端计算引擎(以及 HBM 所需的中介层封装)短缺,这反过来又使市场向不自然的方向扭曲,导致原始计算和内存容量与带宽之间效率低下和不平衡。
之前已经在许多文章中详细讨论过这个问题,我们不再重复这些冗长的内容,只想说,按照我们的想法,现在和不久的将来推出的 GPU 和定制 AI 处理器可以轻松拥有 2 倍、3 倍甚至 4 倍的 HBM 内存容量和带宽,以更好地平衡其巨大的计算量。当在同一 GPU 上将内存翻倍时,AI 工作负载的性能几乎提高了 2 倍,内存就是问题所在,也许你不需要更快的 GPU,而是需要更多的内存来满足它的需求。
正是考虑到这一点,我们查阅了 SK 海力士最近发布的两份公告,SK 海力士是全球 HBM 出货量的领先者,也是 Nvidia 和 AMD 数据中心计算引擎的主要供应商。本周,SK 海力士首席执行官 Kwak Noh-Jung 在韩国首尔举行的 SK AI 峰会上展示了即将推出的 HBM3E 内存的一种,该内存在过去一年中已在各种产品中批量生产。
但这款新推出的 HBM3E 内存却有一个令人兴奋的地方——内存堆栈有 16 个芯片高。这意味着每个存储体的 DRAM 芯片堆栈高度是许多设备中使用的当前 HBM3E 堆栈的两倍,24 Gbit 内存芯片可提供每个堆栈 48 GB 的容量。
与使用 16 Gbit 内存芯片的八高 HBM3 和 HBM3E 堆栈(最高容量为每堆栈 24 GB)和使用 24 Gbit 内存芯片的十二高堆栈(最高容量为 36 GB)相比,这在容量上有了很大的提升。
在您兴奋之前,16 位高堆栈正在使用 HBM3E 内存进行送样,但 Kwak 表示,16 位高内存将“从 HBM 4 代开始开放”,并且正在创建更高的 HBM3E 堆栈“以确保技术稳定性”,并将于明年初向客户提供样品。
可以肯定的是,Nvidia、AMD 和其他加速器制造商都希望尽快将这种技术添加到他们的路线图中。我们拭目以待。
SK 海力士表示,它正在使用同样先进的大规模回流成型底部填充 (MR-MUF) 技术,该技术可以熔化 DRAM 芯片之间的凸块,并用粘性物质填充它们之间的空间,以更好地为芯片堆栈散热的方式将它们连接在一起。
自 2019 年随 HBM2E 推出以来,MR-MUF 一直是 SK 海力士 HBM 设计的标志。2013 年的 HBM1 内存和 2016 年的 HBM2 内存使用了一种称为非导电薄膜热压缩或 TC-NCF 的技术,三星当时也使用过这种技术,并且仍然是其首选的堆栈胶水。三星认为,TC-NCF 混合键合对于 16 高堆栈是必要的。
HBM 路线图回顾和展望
考虑到所有这些,以及几周前 SK 海力士在 OCP 峰会上的演讲,我们认为现在是时候看看 HBM 内存的发展路线图以及 SK 海力士及其竞争对手在试图将这项技术推向极限时面临的挑战了,这样计算引擎制造商就可以避免使用光学 I/O 将 HBM连接到电机,就像我们十年来一直在做的那样。
目前有一系列 SK Hynix HBM 路线图流传,每张路线图都有不同的内容。以下是其中一张:

这是另一个:

让我们回顾一下。HBM1 于 2014 年推出,并于 2015 年小批量生产,大概产量很低,因为它是一种用于提升计算引擎主内存带宽的非常新的技术。SK Hynix 最初的 HBM1 内存基于 2 Gb 内存芯片,堆叠了四层,容量为 1 GB 内存,带宽为 128 GB/秒,使用 1 Gb/秒 I/O 通道。
HBM2 于 2016 年推出,并于 2018 年投入商业化,此时设备的线速提升至 2.4 Gb/秒,比 HBM1 提高了 2.4 倍,每个堆栈可提供 307 GB/秒的带宽。HBM2 堆栈最初有四个 DRAM 芯片高,但后来增加到八个芯片堆栈。HBM2 中使用的 DRAM 芯片容量为 8 Gb,因此四高堆栈最高可达 4 GB,八高堆栈则是其两倍,为 8 GB。
这开始变得有趣起来,而当 2020 年 HBM2E 发布时,情况变得更加有趣。DRAM 芯片密度翻倍至 16 Gbit,主内存容量翻倍至 4 层塔式机箱的 8 GB 和 8 层塔式机箱的 16 GB。DRAM 的线速提高了 50%,达到 3.6 Gb/秒,每堆栈带宽高达 460 GB/秒。有了四个堆栈,现在一台设备的总内存带宽可以达到 1.8 TB/秒,这比传统 CPU 的四或六个 DDR4 通道所能提供的带宽要高得多。
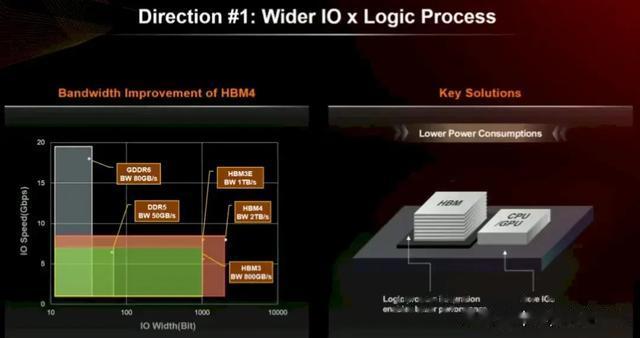
随着 2022 年 HBM3E 的发布,以及 Nvidia 推出“Hopper” H100 GPU 加速器和商业 GenAI 热潮的开始,一切都变得疯狂起来。连接 DRAM 和 CPU 或 GPU 的线路速度提高了 1.8 倍,达到 6.4 Gb/秒,每个堆栈可提供 819 GB/秒的带宽,堆栈以八高为基础,十二高选项使用 16 Gbit DRAM。八高堆栈为 16 GB,十二高堆栈为 24 GB。令人深感不满意的是,HBM3 没有实现十六高堆栈。但每次增加新的高度都不仅仅是难度的增加。
因此,我们今天推出了 HBM3E:

HBM3E 于 2023 年 5 月由 SK Hynix 推出,DRAM 上的引脚速度提升至 8 Gb/秒,比 HBM3 内存提高了 25%,使其每堆栈高达 1 TB/秒。HBM3E 的 DRAM 芯片为 24 Gbit,八高堆栈容量为 24 GB,十二高堆栈容量为 36 GB。由于其更快的 9.2 Gb/秒信号传输速率,美光科技的 HBM3E 被选为 Hopper H200 GPU 加速器(每堆栈 1.2 TB/秒),而速度较慢的 SK Hynix 芯片则被选为 Grace-Hopper 超级芯片中使用的 H100 和 Nvidia 的 H100-NVL2 推理引擎的第二次更新。
SK Hynix DRAM 技术规划负责人 Younsoo Kim 介绍了公司的 HBM 路线图,并讨论了转向 HBM4 内存所需的具体挑战,HBM4 内存仍是一个不断发展的标准,预计将于 2026 年在 Nvidia 的下一代“Rubin”R100 和 R200 GPU 中首次亮相,采用八高堆栈,并于 2027 年在 R300 中首次亮相,采用十二高堆栈。
“Blackwell” B100 和 B200 GPU 预计将使用 8 层 HBM3E 高堆栈,最大容量为 192 GB,而明年即将推出的后续产品“Blackwell Ultra” (如果传言属实,可能会被称为 B300) 将使用 12 层 HBM3E 高堆栈,最大容量为 288 GB。(据我们所知,Nvidia 一直在尝试产品名称。)
我们一直在猜测 HBM4 会采用 16 个高堆栈,而令人惊喜的是,SK Hynix 实际上正在为 HBM3E 构建如此高的 DRAM 堆栈以供测试。只要良率OK,AI 计算引擎肯定可以提前利用内存容量和带宽提升。
理想美好,现实残酷
正如 Kim 在 OCP 演讲中所解释的那样,在实现这一目标之前,我们还有很多问题需要解决。一方面,计算引擎制造商正在敦促所有三家 HBM 内存制造商将带宽提高到高于他们最初同意的规格,同时要求降低功耗:

我们也想要一辆小红马车、一艘帆船、一只小狗和一匹小马作为圣诞礼物,但是你把某样东西列在清单上并不意味着你就会得到它。
随着计算引擎制造商将设备外壳打开,让其升温速度快于性能提升速度,以获得更高的性能,更低功耗的需求变得更加困难。这就是我们如何将 2013 年末 Nvidia 的“Kepler”K40 GPU 加速器的功耗从 240 瓦提高到全口径 Blackwell B200 加速器的预期 1,200 瓦。B100 和 B200 由两个 Blackwell 芯片组成,每个芯片有四个 HBM3E 堆栈,总共八个堆栈,每个堆栈有八个内存芯片高。192 GB 的内存可提供 8 TB/秒的总带宽。我们还记得,整个拥有数千个节点的超级计算机集群拥有惊人的 8 TB/秒的总内存带宽。
顺便说一句,我们认为,如果实现的话,使用 B300 中的 Micron HBM3E 内存可以将带宽提高到 9.6 TB/秒。
遗憾的是,由于内存堆栈也增长到 16 层高,HBM4 内存密度在 2026 年不会增加。也许内存制造商会给我们带来惊喜,推出容量更大的 32 Gbit 的 HBM4E 内存,而不是坚持使用 Kim 演示文稿中的这张图表所示的 24 Gbit 芯片:

HBM 内存中使用的薄晶圆的处理会影响良率,将 DRAM 粘合成堆栈的 MR-MUF 工艺也是如此。(稍后会详细介绍。)
散热问题也是一大挑战。内存对热量非常敏感,尤其是当你将一大堆内存堆得像摩天大楼一样,旁边是一个又大又胖又热的 GPU 计算引擎时,该引擎必须与内存保持不到 2 毫米的距离,才能保证信号传输正常。

因此,这些就是推进计算引擎 HBM 内存所面临的挑战。SK Hynix 能做些什么来应对这一切?做我们一直在做的事情:让东西更宽,并更好地将它们结合在一起。
HBM3 E 具有 1,024 位宽的通道,而 HBM4 将使其加倍至 2,048 位。看起来 24 Gbit 和 32 Gbit DRAM 芯片都将支持 HBM4(可能后者用于 HBM4E,但我们不确定)。带有 32 Gbit 芯片的 16 高堆栈将产生每堆栈 64 GB 的内存,对于 Blackwell 封装上的每个 Nvidia 芯片来说将是 256 GB,或每个插槽 512 GB。如果 Rubin 保持两个芯片并且只是架构增强,那就很酷了。但 Rubin 可能是三个甚至四个 GPU 互连,HBM 沿着侧面运行。
想象一下,一个 Nvidia R300 套件包含四个 GPU,以及十六个堆栈,每个堆栈包含十六个高 32 Gbit 内存,每个计算引擎总共 1 TB。将一些 RISC-V 核心放在上面以运行 Linux,添加 NVLink 端口和一个以 1.6 Tb/秒的速度运行的 UEC 以太网端口,然后将其称为服务器,然后就大功告成了。...
除了更宽的总线之外,Kim 还建议将内存寻址逻辑集成到 HBM 堆栈的基础芯片中,而不是集成到 HBM 控制器中介层中的单独芯片中,这也是一种可能性,从而降低在计算和内存之间的链路上进行内存控制所需的功率。

这种方法还可以独立于完成的 AI 计算引擎对 HBM 堆栈进行完整测试。您可以获取已知良好的堆叠芯片,并在确定之后(而不是 之前)将其焊接到计算引擎插槽上。
对HBM 4的展望
总而言之,HBM 4 预计将提供超过 1.4 倍的带宽、1.3 倍的每个内存芯片的容量、1.3 倍的更高堆栈容量(16 对 12,未在下图中显示,因为它可能会被保存起来用于 HBM4E,除非 Nvidia 和 AMD 可以说服 SK Hynix 放弃这笔交易,并且产量足够好,不会因使用最先进的更密集、更快的内存而损失一大笔钱),并且功耗仅为 HBM3/HBM3E 的 70%。

虽然这一切都很好,但对我们来说,显而易见的是,我们现在需要承诺在 2026 年和 2027 年实现的内存。由于内存计算不平衡,客户在设备上花费了一大笔钱,但由于 HBM 内存的带宽和容量瓶颈,该设备无法接近其峰值性能。我们要么尽早需要 HBM4E 内存,要么像我们今年 3 月在介绍 Eliyan 的同步双向 NuLink PHY 时所写的那样,我们需要一种方法将更多的 HBM3E 内存连接到当前设备上。
更好的是,让我们将堆栈数量增加一倍,并为 Nvidia Blackwell 和 AMD Antares GPU 获取 HBM4E。
请注意,我们并没有要求 24 个高堆栈......那样就太贪婪了。
