OpenAI o1大火之后,国内外上演的AI推理能力竞赛可以说是2024下半年AI领域最大看点了。
甚至前阵子,还有一个很火的开源项目试图通过prompt工程来让Claude 3.5具备类o1的推理能力。
显然,如果你是技术出身,一眼就会知道这种方法是不可能work的,它只会获得“表演性推理”的能力。
而OpenAI o1的推理能力是什么特点呢?
根据官方的说法&case验证:
通过强化学习,o1 学会磨练其思维链并改进它使用的策略。它学会识别和纠正错误。它学会了将棘手的步骤分解为更简单的步骤。它学会了在当前方法不起作用时尝试不同的方法。此过程显著提高了模型的推理能力。
显然,要实现这样复杂的类人推理能力,纯靠暴力的互联网语料统计训练是一定做不到的。因为——
互联网上的数据,承载的是“人类思考过程后的结果”,它是个产物,而不是过程本身。
而思维推理,则是过程。
这个“过程数据”,都不用说互联网了,甚至在o1之前,任何企业内部都不可能有这个数据——毕竟谁会闲的把自己脑子里过掉的东西原封不动写下来发到互联网上呢。
但有一个领域例外,那就是数学。
数学的推理过程,你能在互联网上找到大量推导过程。
这也是为什么,很多类o1模型,会非常强调“数学”能力。因为这个领域的过程数据最容易得到。
而像OpenAI o1表现非常惊艳的编程能力,字谜甚至医学问题,这些领域的过程数据在互联网上是不存在的。在笔者看来,能否真的把数学之外的过程推理能力大幅提升上来,才更能考验一个类o1模型是否“硬核”。
我这两天就恰好遇到一个编程问题,硬核到主流AI大模型全崩:
我想要python实现一段代码支持一个操作,就是将我在命令行里输入过的query按照时间顺序cache到本地的一个文件里和内存里,如果我在命令行里按方向键上或方向键下,就能切换到上一个输入的query或者下一个输入的query(像使用bash那样)。如果按方向键左或右,则能够移动光标来编辑文字(而不是输入一个方向字符);移动光标或删除的时候,需要支持中文汉字删除,不能把汉字拆分成多个char去分别删除不要在命令行里出现这种把方向键当做查询输入的情况,而是去解析方向键:请输入搜索查询: ^[[A^[[A^[[B^[[B^[[A^[[B
如果你是程序员,那你肯定知道我在讲什么。如果不是,不妨转给你的程序员朋友为难他一下。

还是漏个题吧:python自带的input函数,从命令行里接收输入,默认不支持中文,并且方向键不能控制,这里我想实现一个“智能输入框”,像bash命令行一样,还能通过方向键查看历史输入并持久化记忆。
我首先把问题抛给了GPT-4o和Claude 3.5 Sonnet(New),这两个“老一代”大模型中曾经的编程王者。

来,运行一下GPT-4o生成的这个代码。
结果,当我输入了几个汉字后就:

好家伙,你是把中文给我转火星文了吗。
再来看看Claude 3.5 Sonnet交的卷子,这个曾经的编程强者。

运行一下,发现没有中文乱码问题,但方向键移动光标却玩两下就失灵了——

算了,老一代的编程模型肯定不指望了。必须要上先进的类o1范式模型了。
我还测试了前阵子国内发布的某个类o1模型,
,时长00:12
输出是非常的长,但我一跑代码,中文输入不了,也没解决。
,时长00:06
难道除了o1,真的地球上就没一个模型能解决这个问题了吗!
等等,我突然想到,上海 AI Lab前两天也悄悄上线了一个类o1强推理模型,叫「书生InternThinker」。
来,试一下吧!
ps:长图预警

有了前述国内外模型的一连串翻车,我本来没抱啥希望。但,运行了一下它生成的代码后:

卧*,中文支持&光标移动这么丝滑的吗。
好,关掉重运行,试试query记忆功能,看能不能通过上下方向键,还原出我们的两次历史输入——

完美,全部需求都支持到位了。

对此我来了兴趣,准备再测测InternThinker的其他推理能力,是否也这么稳。
等不及的小伙伴,可以去这里测试 https://internlm-chat.intern-ai.org.cn
我先找了道今年难倒不少考生的高考数学题,测一把:

三个问题都答对了。还是稳(正确答案截图列在这儿)

复杂数学可以,难倒一众博士生的“小学奥数题”我也准备为难它一下。
26-63=1,移动哪个数字能让等式成立
别小看这道题,我亲测过,GPT-4o和最新版Claude 3.5 Sonnet是集体阵亡的——
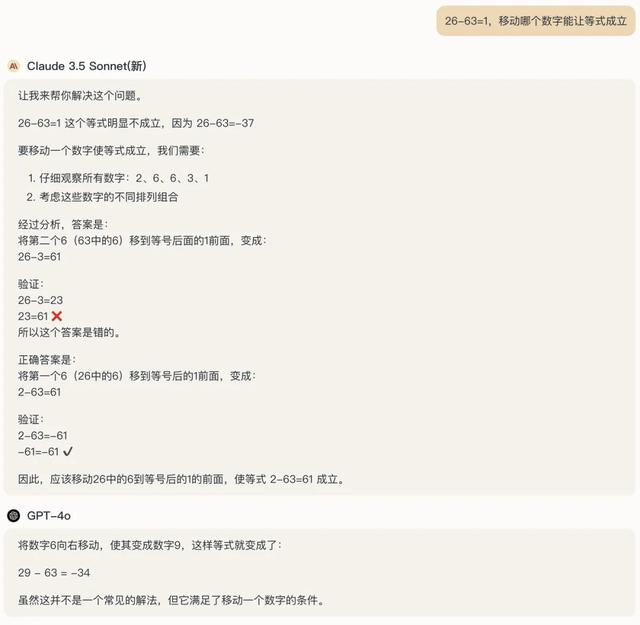
来,我不信InternThinker你能再次吊打gpt-4o和claude3.5sonnet。

卧*,竟然真的做对了。
这道题跟本文开头的编程题一样,据笔者所知,目前为止就只有OpenAI o1模型和书生InternThinker模型解对了。
而且不知道你们有没有注意到,书生InternThinker模型丝毫没有像o1那样掩饰自己的思维链过程,不怕被别人蒸馏。从这个open程度来说,真的值得推给OpenAI让其羞愧一下。
我仔细研究了下它的思维链,我发现它确实不是表演式思考。以第一个编程case为例,从下图可以看出,它是实实在在的在调试代码、反思总结:

从思维链内部来看,中间过程中写过有bug的代码,但从它命名为“Review”的思考部分,说明它具备自我反思的能力,发现了bug并进行代码修正,直到完成一个推理逻辑自洽的代码版本。
o1强推理的体现,就是学会识别和纠正错误并改进它使用的策略。
这个过程,确实非常符合一个程序员编程过程。
拆解到这里,我几乎可以100%的猜测,它一定是想办法合成了大量的“编程过程数据”加入到了模型的训练过程。
于是,我深扒了一下这个书生模型。
果然,我从官方的公众号文章报道里,发现了关键。

来源:强推理模型书生InternThinker开放体验:自主生成高智力密度数据、具备元动作思考能力
这个「通专协作」的合成数据构造方法怎么理解呢?
根据笔者的理解,要合成InternThinker的思维过程数据,首先是通过基座能力足够强的专家模型,来为手上的复杂推理任务采样出足够多的“思维链”。在这个思维链的候选集中,很可能就包含了一条“完美思维链”或一些“比较不错的思维链”。而另一个通用模型,则主打“监督陪伴”,负责观察、分析和改进思维链的质量和可读性。这两个过程交代迭代,最终产出一条正确的思维链,即最终的“过程”训练数据。
看到这里,你可能很快就发现了问题的关键——我怎么能知道大量采样的思维链候选中,哪一条是正确或比较不错的呢?
人工标注可能是最容易想到的。但上海AI Lab团队还为此构建了大规模沙盒环境,来批量解决掉那些可以良好形式化定义的推理任务。

根据官方的报道,上海AI Lab团队,为这个模型的训练和推理,特意构造了一个大规模沙盒环境来拿到思维过程的反馈信号。这里面也包括了“编程沙盒”。
根据笔者的理解,像“代码写的对不对”,“数学公式的计算结果对不对”,都可以通过推理任务沙盒来辅助验证当下计算/中间结果的正确性,从而为思维过程提供反馈信号,进而验证某条思维链是否合理、正确。
ps:显然,这个推理任务的沙盒工程量相当大。比如编程沙盒中,就包含了C++、python、java等几十种编程语言的运行编译环境。而代码之外的通用推理任务沙盒就更不知道有多少了。
当然,还有代码以外的通用推理任务沙盒,来获取反馈信号。
这些过程数据虽然在互联网上不存在,但上海AI Lab通过“通、专模型协作+大规模推理沙盒”的方式,确实能为编程、谜题等推理任务大量获取到珍贵的过程数据,包括了50多种不同思维方式的推理任务的思考过程。
这个沙盒的概念,就像强化学习中的环境的概念。大模型能通过这个环境,来为编程这种可以形式化验证的任务,检验其所构想的“过程结果”是否真的达到了“验收标准”,从而拿到明确的reward信号,进而优化模型的参数。
此外,官方还提到了“人机协同策略生成”,盲猜也为高质量的思维链生成或标注引入了人工数据,进一步解决掉其他难以建模或基座模型难以采样出良好思维链的场景。
模型基于这些珍贵的过程数据用RL范式加以训练,便可以学会像人一样求解那些需要大量复杂推理的任务。这也难怪,InternThinker的强大推理能力,远不止解数学题这么简单。
除此之外,我还发现,背后独创了一套有意思的模型范式——元动作思考范式。

这个范式,很像大名鼎鼎ReAct[1]范式的豪华升级版。
这个元动作思考范式,包含了“理解、知识回忆、规划、执行、反思、总结”等一系列类人的思考步骤。仔细观察一下前面InternThinker解编程题和数学题的思维链,你会发现其跟这个元动作推理范式能非常好的吻合上。
例如,对于数学case来说。
先是审题,即理解题目的意思,求解啥问题。这步对应就是理解任务和理解需求。关联已经习得的知识,比如条件概率、线性变换,这步对应的是知识回忆、经验关联。分析解题的步骤,这里本质是拆解和规划解决步骤。以上都搞清楚后,就可以开始动手解题了,这步其实就是在执行。最后就是检查,也就是反思和调整的过程。从第一性原理出发,传统的链式思维,比较像暴力枚举,而让大模型显式的罗列所有可能性,这无疑非常的不像一个“优等生”的脑袋;InternThinker的这套启发式的思维范式,无疑更像一个经过良好思维培训的“优等生”的解题习惯,效率要高得多。
最后,不得不强调一下,这个书生InternThinker的模型,来自上海人工智能实验室,这也是书生系列模型首次面向公众开放试用。
近期如果再有人问我国内推理能力最接近OpenAI o1模型的是谁,我会毫不犹豫的甩他一个链接:
https://internlm-chat.intern-ai.org.cn
