在CES 2025上,NVIDIA正式发布了让人期待已久的,基于新一代Blackwell架构打造的GeForce RTX 50系列显卡。时隔两年,游戏在变,游戏之外的科技浪潮也在变,但不管这话题是元宇宙还是AI,GPU从不缺席,而作为GPU的发明者,NVIDIA始终站在舞台的Position Zero,为大家献上像素和向量的歌剧。今天,就让我们一起来看看GeForce RTX 50系列里面的带头大哥——GeForce RTX 5090 D的性能表现究竟如何。这次RTX 5090 D是没有Founders Edition的,NVIDIA选择交给AIC们自由发挥。我们这次拿到的是iGame RTX 5090 D Advanced。

由于众所周知的原因,和RTX 4090 D一样,这次大家买到的是RTX 5090 D——D是Dragon的意思。说起来,今年是蛇年,作为小岛监督的粉丝,我还挺希望这张显卡叫RTX 5090 S(Snake)啥的,但这绝对会引起认知上的麻烦。
规格表




说到iGame Advanced系列那就不得不说到它的标志性设计:中间风扇的红环,它从RTX初代Advanced系列出现并延续至今,令人印象深刻。而从整体设计上看,新一代的iGame RTX 5090 D Advanced显然融合了NVIDIA本家Founders Edition的一些设计元素,这里看导风罩就知道了,包围两边风扇的银灰色组件刚好能凑成一个无限标志∞。同时,导风罩的正面是稍微向内凹的,也有点Founders Edition的风格。







三把环形风扇也延续了“两大一小”的经典配置,当然就具体数据而非相对关系而言,它们都很大,两边是107mm的,中间是101mm,而扇叶均为9片,形状也一样。容易注意到中间风扇的转动方向和其他两把不一样的。

金属只是构成了导风罩的外框,而对于其他部分,iGame在这里所用的配方比较新颖,是黑色半透明的塑料,表面经过了磨砂处理。这跟现在操作系统爱用的毛玻璃效果不谋而合,颇具现代感。你还能透过外壳隐约看到埋藏于下方的规则红色框架,神秘又霸气。

作为点睛之笔,中间的圆环自然是重点。从左右风扇侧往里面看可以看到圆环也是红色金属框架的一部分,它的表面处理是很精致的。再里面那一圈透明组件就是灯带了。熟悉iGame系列的玩家大概已经能想象到它亮机时的样子了。

虽然开头的规格表已经披露了它是一张3槽显卡,但是来到侧面,你才能直观地感受到iGame RTX 5090 D Advanced的分量感。这张显卡还是采用常规的散热方式,也就是正面入风,两侧和背板末端出风的形式,因此对于机箱的唯一要求便只剩下空间了。

iGame在外观上一直都挺用心的,尤其是在不放过细节这一点上。在侧面的金属框架上,我们能看见每一颗螺丝位都刻有铭文,iGame还做了药丸状和圆形的下沉。配合这个半透明导风罩,很像科幻作品里面宇宙飞船的舰桥。另外,GEFORCE RTX的logo在透明壳体上,而Advanced的logo则在金属框架上,着实是相映成趣。

RTX 50系列这次沿用了RTX 40系列的16-pin接口,从它的位置可以看出整块PCB约占显卡全长的2/3。用于RTX 5090 D的转接线仍然是四口PCIe 8-pin转16-pin的,它是有点巨大——如果想让装机时线头少点的话,不妨来看看我们的ATX 3.0电源评测,给新显卡找个好的“变电站”。

PCIe 5.0接口在RTX 50系列上首次现身,可见金手指的形状和上一代的显卡有些微的变化。

令我们比较惊讶的是,iGame RTX 5090 D Advanced的末端并没有固定螺丝位,只有右上角的一个铭牌,可能是设计师们优先考虑外观了。不过这不是一个需要担心的问题,iGame是必送金属显卡支架的。

显卡背面的设计和其他区域高度统一,都是走的科幻工业风。从螺丝孔位、核心支架再到电源接口,iGame都在这些位置的边上印着型号说明,为外观增添了不少细节,特别是电源接口这里,除了“Power Connector”外还在下面补了一行小字。



在CES 2025上,NVIDIA正式发布了让人期待已久的,基于新一代Blackwell架构打造的GeForce RTX 50系列显卡。时隔两年,游戏在变,游戏之外的科技浪潮也在变,但不管这话题是元宇宙还是AI,GPU从不缺席,而作为GPU的发明者,NVIDIA始终站在舞台的Position Zero,为大家献上像素和向量的歌剧。今天,就让我们一起来看看GeForce RTX 50系列里面的带头大哥——GeForce RTX 5090 D的性能表现究竟如何。这次RTX 5090 D是没有Founders Edition的,NVIDIA选择交给AIC们自由发挥。我们这次拿到的是iGame RTX 5090 D Advanced。
由于众所周知的原因,和RTX 4090 D一样,这次大家买到的是RTX 5090 D——D是Dragon的意思。说起来,今年是蛇年,作为小岛监督的粉丝,我还挺希望这张显卡叫RTX 5090 S(Snake)啥的,但这绝对会引起认知上的麻烦。
规格表
这一代的核心还是GPC-TPC-SM层级设计,完全体的GB202核心如下图所示,共有12组GPC,24576个CUDA核心。以CUDA核心为基准来说,RTX 5090 D上的GB202-250用到了完整版中CUDA核心的88.5%。从整体结构图上还能看到老熟人GigaThread Engine调度器隔壁多了一个叫做AI-Management Processor(AI管理处理器)的组件,这个我们会在下面聊到。

下一级来到GPC段,可见它包含的TPC从Ada Lovelace的6组扩展到了8组。不过布局上还是一样的,一个独立的光栅引擎,两个ROP分区(每个包含8个ROP单元),而每组TPC包含两组SM。
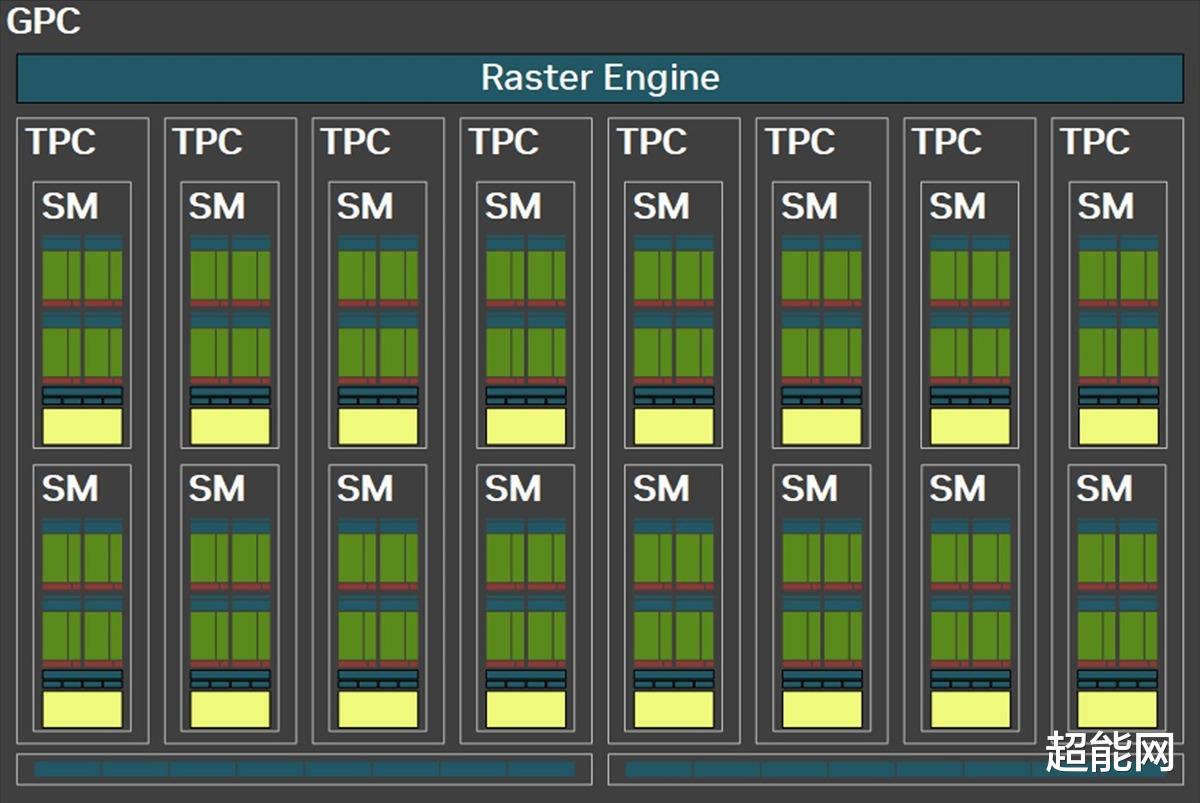
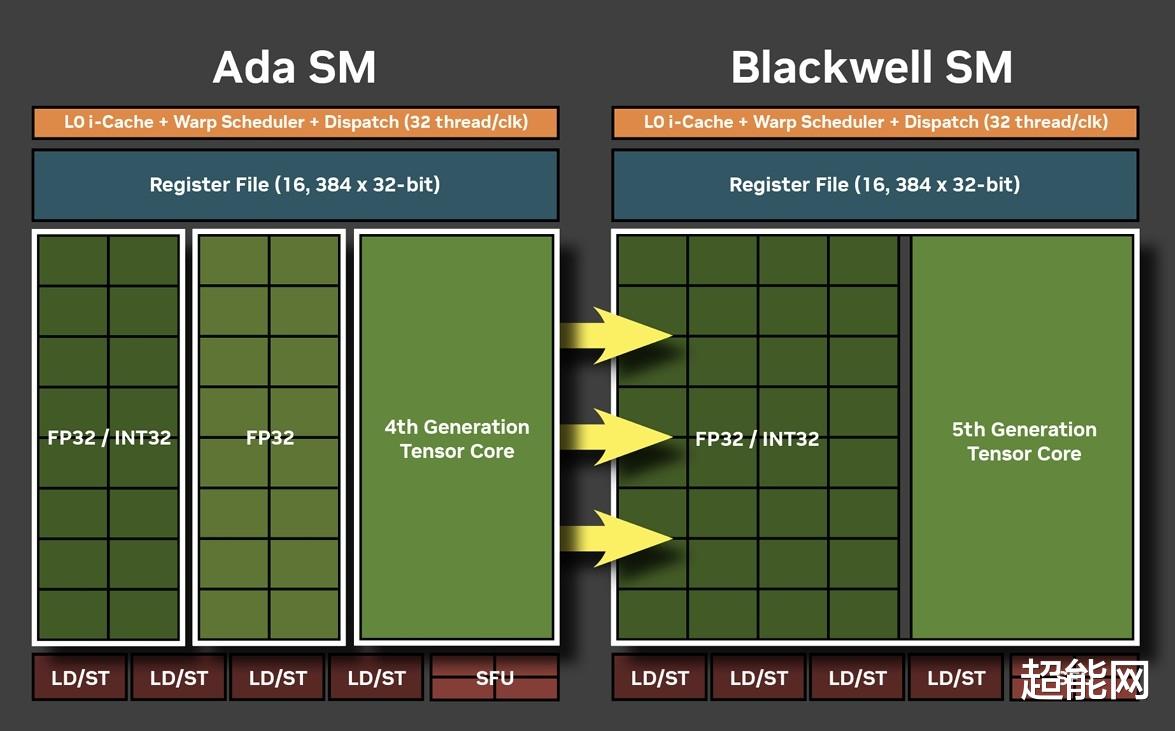
到达SM段,这里的变化是比较大的。首先,现在所有的32个CUDA核心都能执行FP32/INT32运算了,因此INT32的算力可以说是增加了一倍。不过在一个时钟周期里面,核心只能二选一运算,要不FP32,要不INT32。NVIDIA表示这种设计是为神经网络着色器优化的。Tensor Core和RT Core自然也有升级,不过让我们先说完新的显存。
RTX 40系上的GDDR6X是NVIDIA和美光合作打造的,因此你就只能在NVIDIA的产品上看到GDDR6X,而且部件号无一例外全是D8BZC,别无二家了属于是。在RTX 50系列这一代上,NVIDIA是和标准制定者JEDEC固态技术协会合作,推出了全新的GDDR7显存。
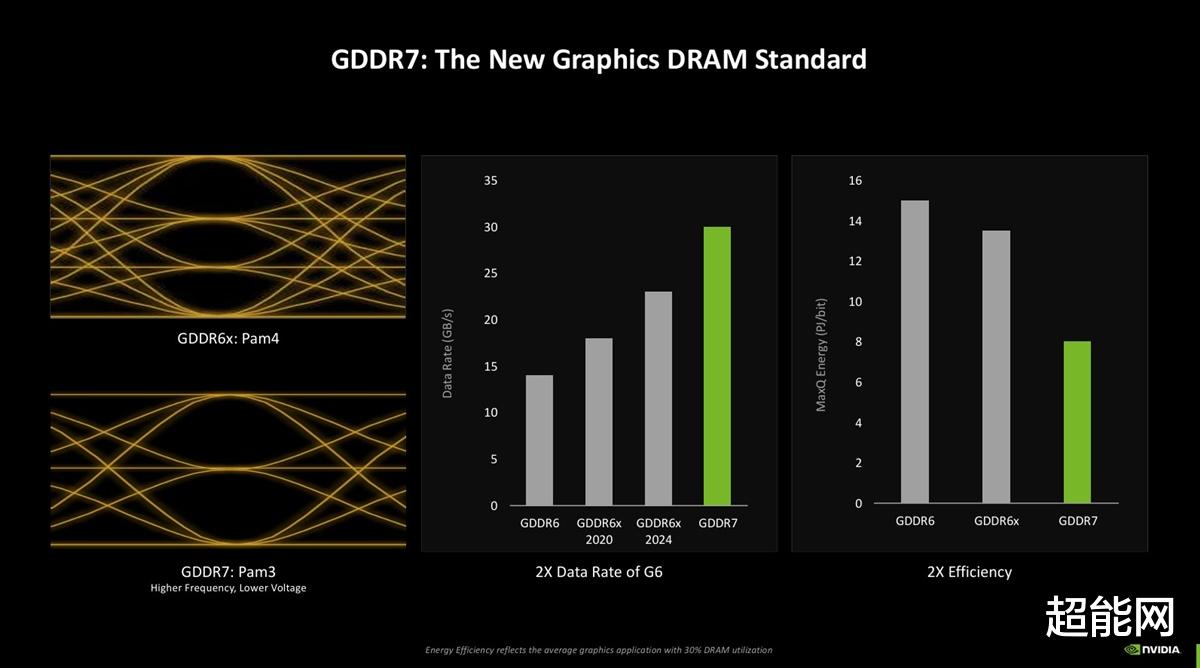
NVIDIA表示,GDDR7显存选择了PAM3调制,这能让它在信噪比方面有所提升,通道的密度也增加了。性能方面,GDDR7能带来更高的带宽,同时比GDDR6X/GDDR6要节能得多。
附带一提,PAM3调制也被用在USB4 v2上。
第5代Tensor Core:新增FP4支持第5代Tensor Core继承了上一代架构的特性,并新增了FP4、FP6的支持,还把FP8 Transformer Engine更新到了第二代。
FP4支持显然是大家比较关心的。NVIDIA对此的解释是,随着生成式AI模型能力的提升,常规的FP16模型对硬件特别是显存的要求与日俱增,在单张显卡上运行这些模型会变得非常困难。而FP4模型需要的显存更小,在TensorRT模型优化器(Model Optimizer)的支持下还能做到几乎没有质量损失,对于整个RTX 50系列来说是很友好的,毕竟不是每张卡都有RTX 5090 D那么大显存。
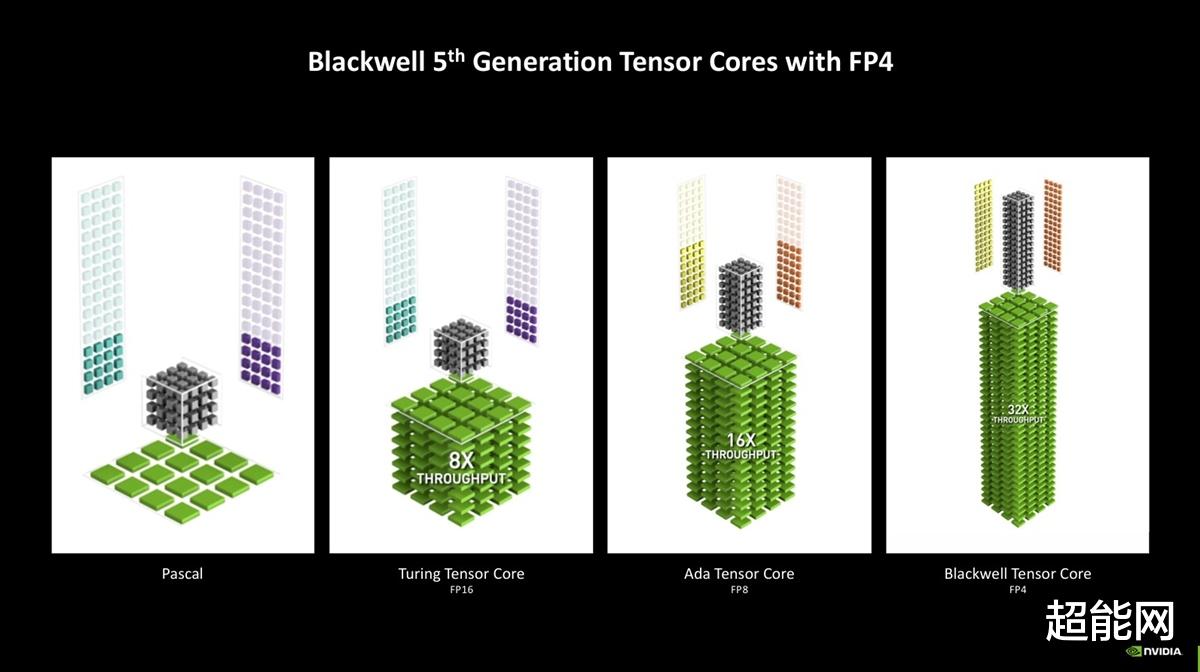
为什么要强调单张卡也可以运行呢?这其实跟游戏也有关系,在我们之前的报道里说过,NVIDIA一直在捣鼓NVIDIA ACE这个AI NPC技术,再加上别的基于AI的游戏技术也要用到Tensor Core,因此提高模型的运行效率很有必要。
第4代RT Core:为RTX Mega Geometry准备在第4代RT Core上面我们仍然能见到一些熟悉的组件,比如Box Intersection Engine和Opacity Micromap Engine这两个加速引擎,它们分别针对BVH树遍历和透明物体进行加速。而新增的组件包括Triangle Cluster Intersection Engine和Triangle Cluster Compression Engine,以及Linear Swept Spheres。
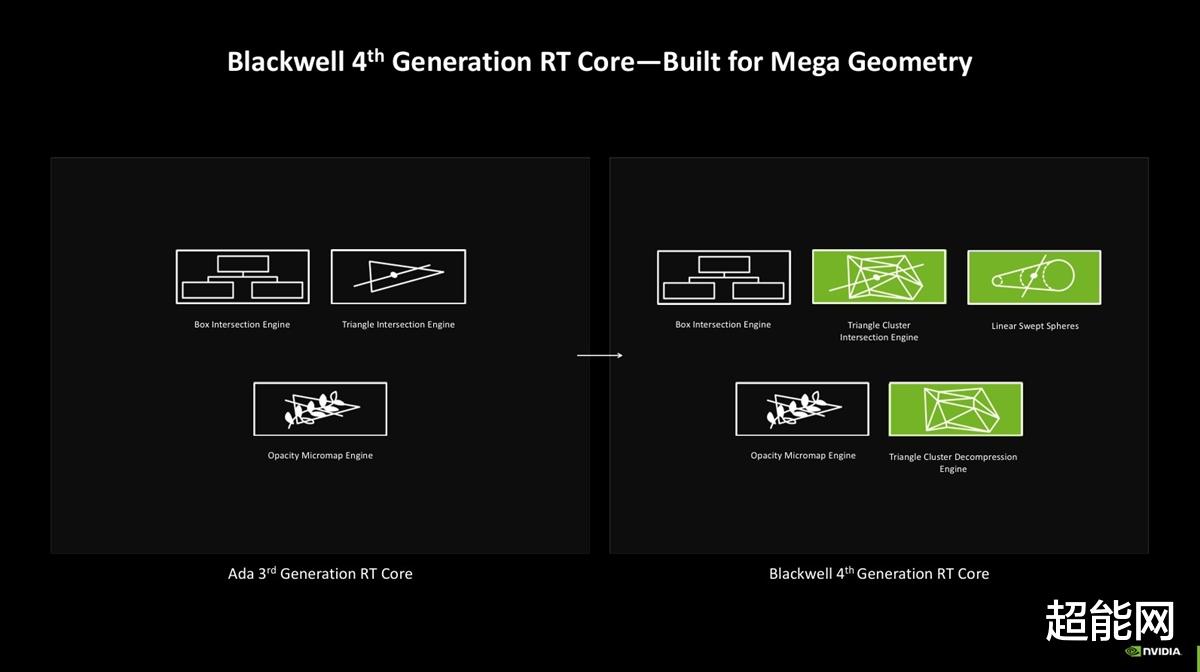
可见Triangle(三角形)、Cluster(簇)两个名词的出现频率很高。不过这些新出来的组件有什么用,还得结合后面的RTX Mega Geometry技术一起讲。现在只需要记住Blackwell提供了两倍于Ada Lovelace的Ray-Triangle交叉检测吞吐量就好。
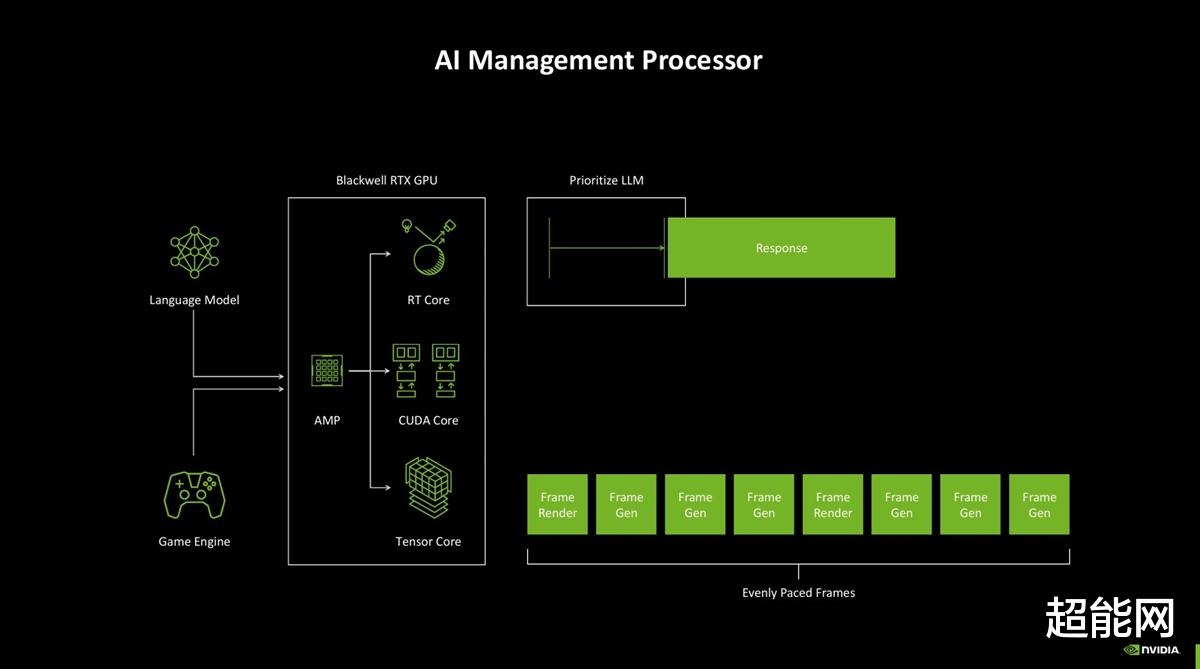
AI-Management Processor和着色器执行重排序2.0AI-Management Process(AMP)在架构图上和GigaThread Engine并列,可见它也是个调度器。AMP的本质是一个位于管线前端的RISC-V处理器,它支持Windows硬件加速GPU计划,能够更自由地管理GPU。
AMP同样跟AI游戏有关。这里举个例子,本地运行LLM的话,它们首次响应的时间一般是比较慢的,这放在知识库聊天机器人里还好,大家可能都习惯了,但是对于游戏来说,这就是另一种情景了:试想一下你打开游戏加载存档,刚想找npc接个任务,结果npc憋了半天才冒出一句“你好”,这确实很破坏游戏体验。
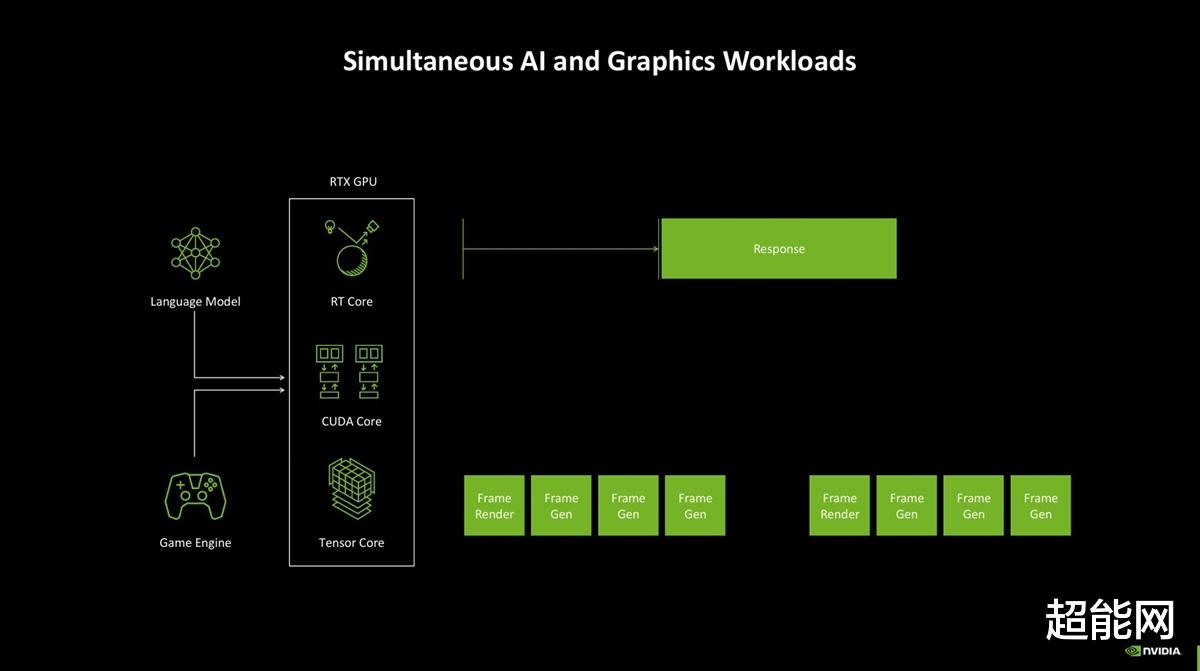
同时运作的话,LLM的响应时间变慢,游戏帧率也会受影响
而在AMP的支持下,CUDA、RT Core和Tensor Core三大部分可以协调工作。如图所示,AMP提高了LLM的优先级,令其更早启动,做到在游戏中及时响应,并同时让游戏引擎、DLSS 4保持稳定的帧率输出。
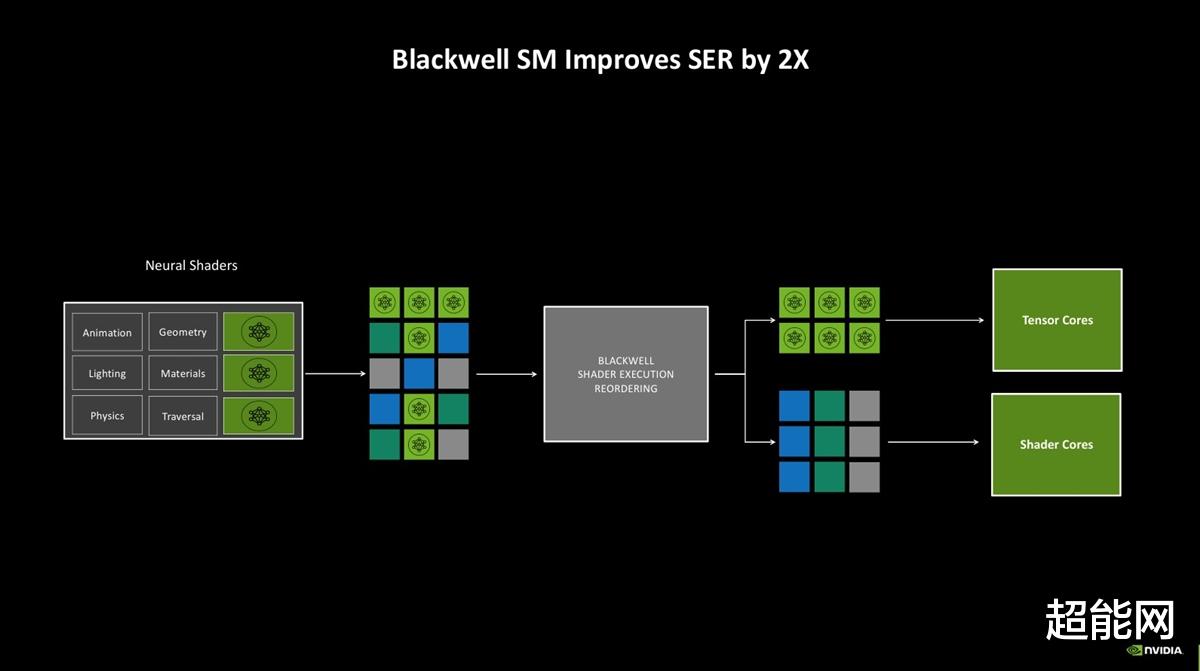
在Ada Lovelace上的着色器执行重排序(SER)主要是针对光线追踪而设计的。通过对光线追踪任务的动态重排序,该功能可充分提高硬件使用率。而Blackwell上的SER 2.0还可以将神经网络的负载直接发送至Tensor Core处理,加速神经网络渲染。NVIDIA表示,Blackwell上的SER重排序逻辑效率达到了前代的2倍,降低开销之余还能提高精准度。
前面的都是硬件基础,接下来说说构筑在其上的技术。
神经网络渲染是NVIDIA这次重点宣传的技术,说起来它里面的一些组件也不是突然就蹦出来的,比如说神经网络材质这些,估计一些玩家以前也听说过。而在详细介绍之前,我们必须开宗明义地讲,这是一项为未来游戏而准备的技术。虽然目前确实没有太多游戏采用了下面的功能,但是正如RTX初代一样,只有在技术Demo展示了硬件的可能性后,为游戏加入光追的游戏才会雨后春笋般出现。
神经网络渲染的核心是神经网络着色器。NVIDIA希望利用AI去实现以往需要复杂代码才能达成的图形效果。在NVIDIA的构想中,借助全新的Cooperative Vectors API,Tensor Core可以访问任何类型的着色器,开发者则可以通过Slang着色器语言去为自己的项目带来以下的神经网络渲染功能。
神经网络材质首先,现实世界的物体非常复杂,就算是一把小刀也会具有丰富的细节。一般在3D创作软件中,除了精确的建模和雕刻外,我们会用复杂的函数来模拟真实世界物理材质的光学属性。就像下图一样,各个节点(它们背后都是大量的代码)互相连接,最后呈现出一把样子还过得去的小刀。如果要让它变得更真实,或者把它变成一把冒火的直剑,那这个节点图还要变得庞大很多。

我并非Blender糕手,但是这图大概也能说明一二了
对于3D创作软件来说,花很长时间渲染一帧当然不是什么问题。然而对于游戏来说,帧率非常重要!为了让这些精致的材质在游戏里面完整呈现,NVIDIA的做法是,使用AI替换掉传统的着色器流程。神经网络着色器会根据屏幕中物体表面的信息到潜空间寻找相应的特征并将其提交给解码器,最后生成和传统着色流程接近的材质(当然,两者都是对现实的近似,只是传统方式是基于复杂的数学计算,而AI是根据训练数据生成的)。这样一来,渲染速度就可以满足游戏的帧率需求。神经网络,很神奇吧?

想了解更多的朋友可以到NVIDIA 研究中心阅读这篇论文:《Real-Time Neural Appearance Models》
RTX Neural Texture Compression(神经网络纹理压缩)纹理对于游戏的影响我想不用我多说,不过分辨率高了图片体积就会变大,这也是个很易懂的道理。神经网络纹理压缩技术通过神经网络着色器利用神经网络压缩和解压纹理,相比起传统方式更高效,在占用更少显存的同时保持纹理的清晰度。以上图的demo为例,在应用该技术后,所占的显存降低了66%。
想了解更多的朋友可以到NVIDIA 研究中心阅读这篇论文:《Random-Access Neural Compression of Material Textures》
RTX Neural Radiance Cache(神经网络辐射度缓存)之前在DLSS光线重建里面就说过,往屏幕里面投射太多光线对显卡的压力是超乎想象的,如果反弹次数多的话就更是如此了。而神经辐射度缓存有一个实时运行的小型神经网络,光线只需要反弹一次,它就能预测光线反弹多次后的情况,减少GPU光追单元的压力。同时,又因为这个神经网络能推理出多次反弹,也能提升间接照明质量——直白点说就是不通过硬算而提高了游戏画面真实感。

这个神经网络是实时运行的,意味着它能根据游戏场景变化而不断训练自己,从而在每一个关卡都能提供准确的间接照明体验。
RTX Skin(RTX皮肤)和RTX Neural Faces(RTX神经网络面孔)还是先扯回现实世界:人的皮肤也好,动物的皮肤也罢,它们都是半透明物体,而这就意味着光会穿过它们,并在里面产生散射和反射,所谓白里透红,就很好地形容了这种现象。然而在现实的大部分游戏里面,人类角色或者具有相同特性的生物却很难表现出这种效果,他们可能拥有细致的皮肤(材质),但是难以和光线产生足够真实的交互,某些情况下,他们看起来就像手办。
因此NVIDIA将源自电影渲染技术的次表面散射带入了实时路径追踪领域,这就是RTX Skin。借助这项技术,光线能够射入皮肤内,并还会在里面进行反射和折射。如图所示,RTX Skin能够让猎头蟹的身体显得更透亮,四条腿也有光线进入。

RTX神经网络面孔则是解决了另一个问题——恐怖谷效应。为了满足游戏的帧率要求,RTX神经网络面孔采用了一个捷径:首先,开发者只需要准备渲染好的人脸和姿势,然后将其交给AI模型让其生成更真实的面部和表情即可。这个AI模型是由数以千计的多角度、多表情的人脸图像作为数据集,在NVIDIA的超算上训练而成。这有点像DLSS超分辨率,只是针对的对象不同。

在说RTX Mega Geometry之前,我们先来说说虚幻引擎5的Nanite。当然,这只是个例子,我记得目前有一些厂商和引擎也在试图实现类似Nanite的LOD系统,不过我们还是拿最有名的来举例好了。
Nanite可以提供非常高的物体精细度,这点在《黑神话:悟空》等游戏里面可以很好地体现出来。不过,虽然Nanite呈现的雕塑和建筑非常精致,但是光影很多时候却没有达到相对应的水平,这主要跟BVH的构建有关——Nanite会根据屏幕距离自动调整物体三角形的数量,而光线追踪需要基于三角形构建BVH用于检测光线碰撞。正因为三角形数量变化频繁,一旦要如实为其构建BVH,那这个算法得反复跑。再说了,为数不清的三角形构建BVH也确实是件难事。毕竟,游戏需要帧率,我们之前说过了。
而NVIDIA RTX Mega Geometry则是在TLAS(顶层加速结构)和BLAS(底层加速结构)两个层级的架构上做改进。

首先是BLAS一侧的Cluster-level Acceleration Structures(CLAS,簇级加速结构)。它最多能把256个三角形打包好(为了大家理解容易点就不叫簇了),并将其作为BVH的基础部分输入,最后组成BVH树。同时,CLAS不仅能在游戏里面按需创建,还能缓存到硬盘里面,后面的帧要用的话直接从硬盘加载。这样一来,系统要处理的事情就少很多,如图所示,不用每个三角形都算一遍,只需要关注色块部分就好。

接下来是Partitioned Top-Level Acceleration Structure(PTLAS,分区顶层加速架构),这是针对复杂场景设计的。NVIDIA表示,在很多游戏里面,场景内有不少物品比如建筑都是固定不变的,但是如果每一帧都要给它们构建一次TLAS,那肯定是不划算的。而正如名称中的Partitioned\分区所示,PTLAS把场景内的物体分成了多个区域,一些用来放置静态的物品,然后一个全局分区用于处理动态的物品,从而减轻了系统的压力,提高了效率。

现在再回头去看第4代RT Core内的各个新增组件,大家就能明白它们是RTX Mega Geometry的坚实基础,新增的三个引擎里面,有两个的设计目的就是为了加速以簇为单位的操作。不过NVIDIA表示所有RTX显卡都能支持RTX Mega Geometry,只是跟所有新技术一样,Blackwell是目前支持最好的。附带一提,如果你觉得RTX Mega Geometry的设计思路很耳熟的话,还记得DirectX 12 Ultimate的VRS(可变速率着色)等特性吗?可以试着这样理解。
DLSS 4:多帧生成还有模型升级我们终于说到DLSS 4了!说实话DLSS 3引入的帧生成功能已经挺让我满意的了,而DLSS 4则是更进一步,带来了多帧生成功能。这个我想应该不用过多解释,就是渲染1帧最高生成3帧。另外,我在最近的Editor's Day上问过NVIDIA关于多帧生成极限的问题,他们表示这AI模型是可以生成更多帧的,但是3帧是一个比较合理的值,因为DLSS 4是多个AI模型一起工作的,所以工程师在设计时不单单要考虑帧生成的问题,再说了,生成3帧带来的提升已经足够强力了。
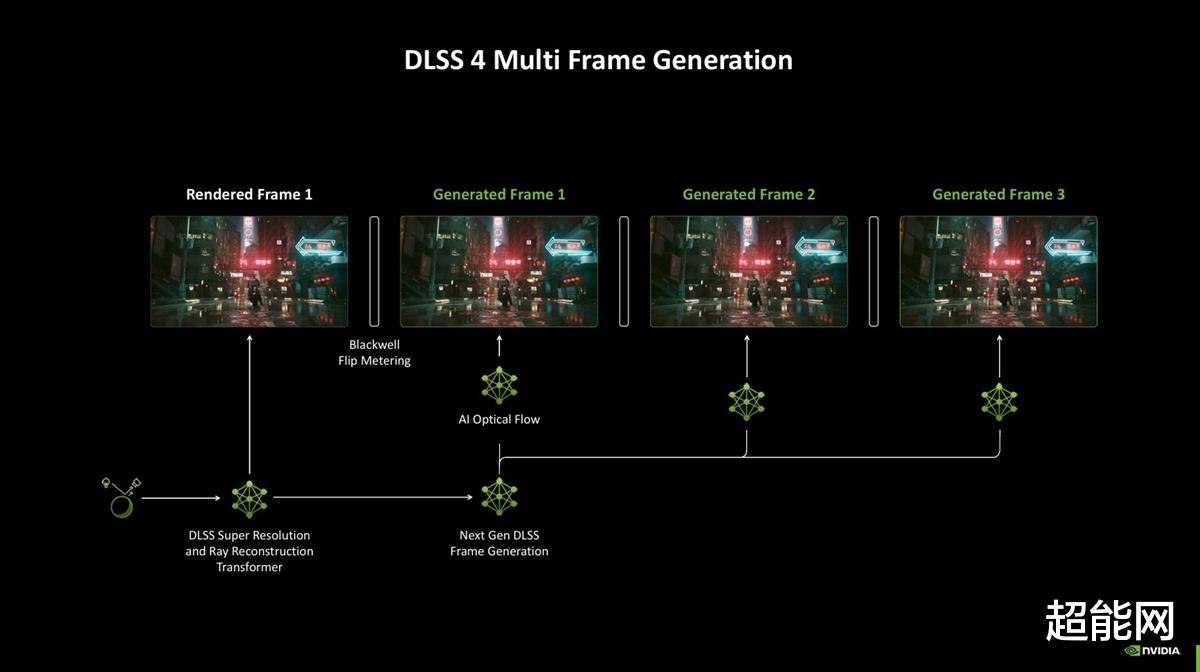
接下来我们就逐一拆分DLSS 4的各项组件,看看它们有什么更新,又是如何协同工作。
首先是大家都关注的帧生成,NVIDIA Blackwell的帧生成模型比上一代快了40%,同时显存占用降低30%。同时,用于提供光流场信息的不再是RTX 40系列上的光流加速器,而是一个更高效的AI模型。

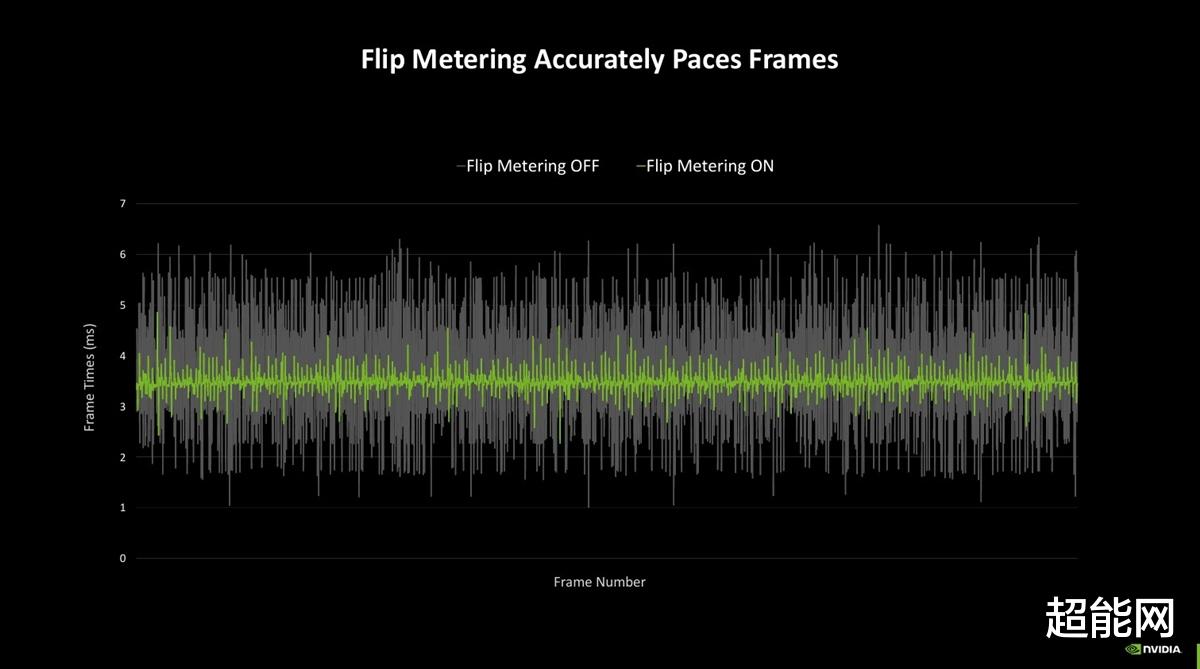
不过如此一来新的问题就产生了:在Ada Lovelace上,DLSS 3是渲染一帧生成新的一帧,就是帧1,1.1,2,2.1...这种,把控每帧的输出顺序还是比较容易的,因为生成的帧1.1总在渲染的帧1后面,如果来不及输出帧1.1,那就把它丢掉,直接输出帧2就好。而RTX 40系上的DLSS 4是1,1.1,1.2,1.3,2,2.1,2.2,2.3,3...,中间整整隔了生成的3帧,怎么不让输出顺序乱套就是新的问题。为此,Blackwell引入了硬件级Flip Metering(这个名词确实很难描述,直译是翻转测量),这个组件将帧平滑逻辑从CPU转移到GPU的显示引擎上,让GPU更精确地掌控显示每一帧的节奏,降低帧与帧之间的时间波动。开启后NVIDIA表示,Blackwell的显示引擎获得了两倍像素处理能力,这样就可以支持高分辨率、高刷新率下的Flip Metering。
由于DLSS 4多帧生成需要用到第5代Tensor Core的强劲算力去计算光流场和生成多帧,因此这个功能目前是Blackwell独占的。
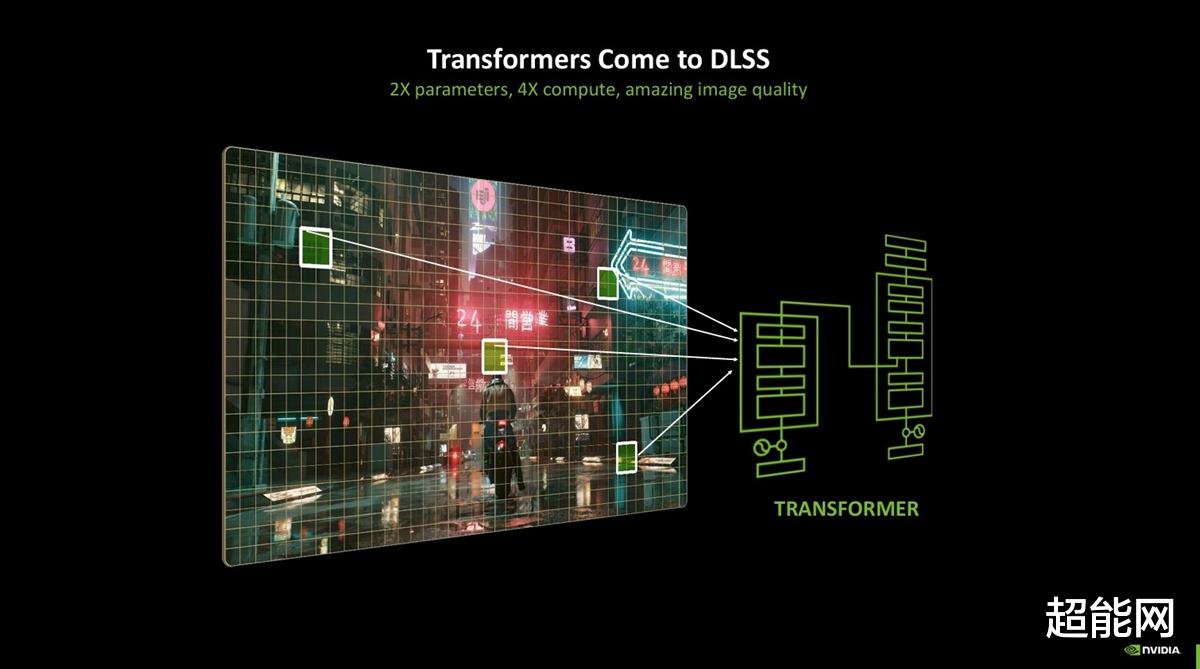
然后比较让人惊喜的是,超分辨率、光线重建、DLAA也获得了更新,它们的模型从CNN换成了Transformer,一个采用自注意力机制的神经网络,适用于从RTX 20-50的全线RTX GPU。不过我想在这里说明CNN和Transformer两个神经网络有什么区别绝对会喧宾夺主,光是编码器和解码器就够喝一壶的了。因此只需要知道新的模型能够提高画面的稳定性,提升光照细节,给予动态物体更多细节即可。大伙可以在下面的DLSS 4测试中非常直观地看到这两个模型的画面差别。
至于DLSS 3三板斧之一的NVIDIA Reflex也迎来了更新,现在是NVIDIA Reflex 2了。相比于DLSS这种原理较为直观的技术,Reflex 2其实有点难懂,在刚公布时,甚至有一些玩家觉得这是AI自瞄了(笑)。
还是先从Reflex 1开始说起吧,首先要知道,键鼠这些外设不归GPU管,而是CPU的职责。CPU会收集键鼠的数据,然后和其他渲染要用的东西发送给GPU,GPU会输出画面到显示器上。这是一条队列,如果CPU和GPU协调工作的话那自然是没问题,但有些时候如果CPU太快或者太慢了,那就会连带着GPU渲染也出问题,结果延迟就提升了。因此,Reflex 1的做法是清除积压的CPU渲染队列,让CPU可将最新的一帧提交给GPU渲染,这样从玩家实际操作到屏幕出现相应变化的时间,也就是延迟,会降低不少。

到了Reflex 2,NVIDIA引入了Frame Warp(帧扭曲)这个技术。直白来说,就是在这个队列中,GPU会“抢跑”了:如果玩家做出了操作,Frame Warp会直接从CPU获得最新的鼠标位移信息,然后让GPU无视队列里等待渲染的帧,直接将鼠标位移和最新一帧同步。这也是名字中Warp(扭曲)的含义,把帧扭转到最新操作上来,很形象。

问题在于,虽然玩家的操作第一时间同步到屏幕上,但这时候屏幕会出现一些空白像素——毕竟队列里面还有帧等待渲染呢。为此,NVIDIA会利用之前的数据修复这些空白的地方,从而让画面保持完整。从《The Finals》的演示来看,其实要修补的地方并不多,而且也是局限一些画面边缘处,影响不会很大。

目前NVIDIA Reflex 2还未实装,《The Finals》和《无畏契约》将是未来首批支持NVIDIA Reflex 2的游戏。
NVENC和NVDEC新增Y′CbCr 4:2:2支持目前很多摄像机都支持录制4:2:2格式的视频,这是有原因的:4:2:2相比起4:4:4更节省储存空间,但是比起4:2:0能保存更多的颜色,这样一来就给后期调色留下了充足的空间。Blackwell这次新增了4:2:2的编解码支持,可提高创作者的效率,比如说导出时间减少,更流畅的多路回放等。NVIDIA表示,第6代NVDEC可同步解码和播放多达8个4K60 4:2:2视频流。

而第9代NVENC则提升了HEVC和AV1的编码质量,为4:2:2 H.264和HVEC编码提供了支持。另外,还有一个全新的AV1 Ultra High Quality(UHQ)模式,它可以用更多的时间去获得额外5%的质量提升。NVIDIA还表示,这个模式在RTX 40系列上也可用,不过Blackwell的质量是更好的。
外观设计说到iGame Advanced系列那就不得不说到它的标志性设计:中间风扇的红环,它从RTX初代Advanced系列出现并延续至今,令人印象深刻。而从整体设计上看,新一代的iGame RTX 5090 D Advanced显然融合了NVIDIA本家Founders Edition的一些设计元素,这里看导风罩就知道了,包围两边风扇的银灰色组件刚好能凑成一个无限标志∞。同时,导风罩的正面是稍微向内凹的,也有点Founders Edition的风格。
三把环形风扇也延续了“两大一小”的经典配置,当然就具体数据而非相对关系而言,它们都很大,两边是107mm的,中间是101mm,而扇叶均为9片,形状也一样。容易注意到中间风扇的转动方向和其他两把不一样的。
金属只是构成了导风罩的外框,而对于其他部分,iGame在这里所用的配方比较新颖,是黑色半透明的塑料,表面经过了磨砂处理。这跟现在操作系统爱用的毛玻璃效果不谋而合,颇具现代感。你还能透过外壳隐约看到埋藏于下方的规则红色框架,神秘又霸气。
作为点睛之笔,中间的圆环自然是重点。从左右风扇侧往里面看可以看到圆环也是红色金属框架的一部分,它的表面处理是很精致的。再里面那一圈透明组件就是灯带了。熟悉iGame系列的玩家大概已经能想象到它亮机时的样子了。
虽然开头的规格表已经披露了它是一张3槽显卡,但是来到侧面,你才能直观地感受到iGame RTX 5090 D Advanced的分量感。这张显卡还是采用常规的散热方式,也就是正面入风,两侧和背板末端出风的形式,因此对于机箱的唯一要求便只剩下空间了。
iGame在外观上一直都挺用心的,尤其是在不放过细节这一点上。在侧面的金属框架上,我们能看见每一颗螺丝位都刻有铭文,iGame还做了药丸状和圆形的下沉。配合这个半透明导风罩,很像科幻作品里面宇宙飞船的舰桥。另外,GEFORCE RTX的logo在透明壳体上,而Advanced的logo则在金属框架上,着实是相映成趣。
RTX 50系列这次沿用了RTX 40系列的16-pin接口,从它的位置可以看出整块PCB约占显卡全长的2/3。用于RTX 5090 D的转接线仍然是四口PCIe 8-pin转16-pin的,它是有点巨大——如果想让装机时线头少点的话,不妨来看看我们的ATX 3.0电源评测,给新显卡找个好的“变电站”。
PCIe 5.0接口在RTX 50系列上首次现身,可见金手指的形状和上一代的显卡有些微的变化。
令我们比较惊讶的是,iGame RTX 5090 D Advanced的末端并没有固定螺丝位,只有右上角的一个铭牌,可能是设计师们优先考虑外观了。不过这不是一个需要担心的问题,iGame是必送金属显卡支架的。
显卡背面的设计和其他区域高度统一,都是走的科幻工业风。从螺丝孔位、核心支架再到电源接口,iGame都在这些位置的边上印着型号说明,为外观增添了不少细节,特别是电源接口这里,除了“Power Connector”外还在下面补了一行小字。




右侧的镂空区域并没有很粗暴地露出内在的鳍片,而是在上面覆盖了格栅,材质和导风罩的一样,是黑色半透明的塑料。像上面图片那样直直地看下去,你可能会觉得这个格栅太过单调,你得斜着看才能看出门道——当它装机时,你就能看出iGame的logo。

最后是视频输出接口一侧,接口外形上当然没有变化,都是3个DP加1个HDMI。而RTX 50这次终于升级到了DP 2.1a和HDMI 2.1b,可支持更高的分辨率和刷新率。

旗舰,往往就是和堆料划等号的。iGame RTX 5090 D Advanced是一张重达2.6Kg的显卡,这个数字比不少游戏本都要大了,而这种重量又忠实地反映在它的散热模块上。

从这个凸起来的小圆角方块上不难看出是和核心接触的是均热板,这是iGame在高端显卡上爱用的设计。而两侧供电区域则是由铝合金框架传递热量的。热管配置方面,iGame RTX 5090 D Advanced是7x 8mm + 2x 6mm热管的设计,单从数字上来看就非常强力。

显卡PCB的布局是非常紧凑的,而这种紧凑又很大一部分来源于它的核心区域:巨大的Blackwell GB202-250核心,以及周边的16颗三星GDDR7显存。单颗显存的容量为2GB,位宽为32bit。







供电方面,iGame RTX 5090 D Advanced采用的是16 + 7 + 6的配置,所用的MOSFET全部是来自MPS的MP97993,可输出电流为50A。电源管理芯片也是MPS的MP29816-A,应该是RTX 50系列这一代的电源管理集成度提高了,我并没有在PCB上找到类似显存电源管理芯片的IC。


本次的测试平台以AMD 锐龙7 9800X3D和X870E主板为核心,可确保显卡性能的全力发挥。为了能给这张显卡提供充足的电量,我们选择了航嘉 MVP P1600X电源。至于对比显卡的话,就只有RTX 4090 D了,说实话在这篇评测里面加红队的卡确实没有必要,毕竟过去两年的各种游戏需求评测里面大家都能看到RTX 4090/4090 D是怎么压着RX 7900 XTX来打的,等RTX 5080评测我们再邀请红队参战吧。
本次测试的驱动是Beta版的Game Ready驱动,RTX 4090 D和RTX 5090 D都可以使用。系统则是最新版的Windows 11 24H2。在游戏记录数据这块,如果游戏自带Benchmark的话,我们会优先选择Benchmark提供的成绩;如果游戏需要手动测试,我们会用NVIDIA Frameview去记录成绩。由于RTX 5090 D的旗舰定位,游戏的设置都是预设的最高了,光线追踪也是,只要游戏支持我们都会直接开全景光线追踪/路径追踪。
基准测试
首先还是3DMark的基准测试,得益于规模的增加,RTX 5090 D在这块的成绩可以说是暴打RTX 4090 D了。除了分辨率定在1080P的Fire Strike外,RTX 5090 D在其他测试中都比RTX 4090 D保底好45%,一些涉及到光追的测试如Port Royal和Speed Way,RTX 5090 D更是有着50%的升幅。规模的增大确实令RTX 5090 D傲视群雄。
游戏测试DLSS 4性能测试先来看看备受关注的DLSS 4。我们这次一共会测试4款支持DLSS 4的游戏,其中3款是游戏内就支持DLSS 4的,还有《漫威争锋》则是通过NVIDIA App的DLSS优设功能支持——这个功能可以理解为是在游戏和渲染API中间插入一个新的框架,玩家可以利用这个它为一些游戏添加更丰富的DLSS选项,比如说给原本不支持多帧生成的游戏加入多帧生成,毕竟不是所有游戏都是完整集成DLSS的。虽然我们目前测试的DLSS 4游戏数量是有限的,但当你们收到RTX 50系显卡的时候,应该就会有很多游戏获得原生DLSS 4或通过NVIDIA App的DLSS优设支持了,NVIDIA表示首日支持的游戏和应用数量会多达75款。
下面我们就细致到游戏和NVIDIA App设置界面说说DLSS 4在设置上跟以前相比有什么变化。
还是拿《赛博朋克2077》这游戏做例子吧,现在DLSS一栏新增了超分辨率模型选择,玩家可以选择全新的Transformer或以前的CNN模型,虽然说是超分辨率,但其实光线重建的模型也会被一并切换。

接着是帧生成,RTX 50系显卡现在可以支持在2x,3x和4x三挡之间切换。2x就是DLSS 3,渲染1帧生成1帧,3x和4x依此类推,就不累述了。附带一提,RTX 40系显卡是只能选择开关,不能选择增幅的。
NVIDIA App的设置跟游戏中的类似,也是分成模型选择、帧生成倍数和超分辨率三个选项。一般来说因为是非游戏引擎集成的设置,所以过程可能比游戏内设置要略微多花一点时间,比如我们这次测试的《漫威争锋》,就需要先设置好再开游戏,而不能在游戏里实时设置。

至于帧率这块,DLSS 4确实强到让人无话可说,毕竟DLSS 3的单帧生成已经是帧率翻倍了,最高能生成3帧的DLSS 4可以说让不少连4K原生分辨率60fps都达不到的全景光线追踪游戏达到电竞游戏一般的帧率,不会让你的4K@360Hz旗舰显示器白买。至于延迟方面,随着生成帧率的增加,延迟固然是相应上升的,不过4x帧生成下的40ms对于3A游戏来说其实完全可以接受。像《漫威争锋》这种纯多人游戏甚至只有20ms,和单开超分辨率时的延迟持平,考虑到这款游戏是通过DLSS优设而非游戏内集成启动多帧生成的,这种延迟表现就更值得表扬了。当然,你也可以选择3x帧生成来降低延迟,反正这种设置下帧率已经足够高了。而CNN和Transformer两个模型似乎对游戏帧率没什么影响,因为被测游戏里面只有两款是原生支持模型切换的,所以这个结论其实不太好下,还得看以后的表现。




因为游戏提供了丰富的设置选项,我们同时也以《赛博朋克2077》为例测试了一下DLSS 4 4x帧生成下,不同超分辨率模式对于帧率和延迟的影响。综合看来,帧生成的倍数对帧率来说只有流畅和更流畅的区别,而它对于延迟的影响其实是小于超分辨率挡位的,如果开着质量挡,延迟可能就到40ms以上了。

最后来看一下Transformer和CNN两个新旧模型的对比,值得注意的是,这是所有RTX显卡都有的福利。就算你暂时不想升级到RTX 50系列,也很值得看看新模型的变化。需要强调的是,下面所有的对比截图均是在性能挡获取的,屏幕分辨率为4K。
首先是细节处理的问题,Transformer模型在这方面是更胜一筹的,这里可以关注出口的门。换用新模型后,金属门板上的格栅更干净,映射在上面的灯光更显柔和,门打开时,可以看到夹层的金属部件被描绘得更加细致。很难想象它们的渲染分辨率其实都是一样的1920 x 1080。




因为光线重建模型也换用了Transformer,可见水面反射的画面质量也有所提升。


室内场景因其复杂程度很适合展示新模型的能力。来看看这个快餐摊位上的调料瓶和托盘,Transformer模型很好地强化了瓶盖和托盘外沿的纹理,而CNN模型还是比较模糊。


同时在画面稳定性这块,从视频中可以看到新模型显著减少了物体边缘处的闪烁现象,之前我们在DLSS 3.5测试的时候就表扬过光线重建对铁丝网这类物体的质量提升,现在Transformer模型让它们变得更好了。而从酒保身体边缘和快速滚动屏幕这两个场景来看,新模型也减少了伪影等现象。
4K分辨率
接下来是常规测试。在4K光栅化成绩里面,比起RTX 4090 D,RTX 5090 D有着相当大的提升。像《赛博朋克2077》和《心灵杀手2》这些RTX 4090 D跑得够呛的游戏,RTX 5090 D可以轻松在4K下获得一个流畅的帧率。而搁倒一大片显卡的《黑神话:悟空》,RTX 5090 D在4K原生分辨率下也接近60fps,真的非常优秀。至于像《刺客信条:幻景》这些RTX 4090 D本来就跑得很好的游戏,RTX 5090 D确实跑得更好了。不过需要注意的是,这种设置下的RTX 5090 D做到了帧率和功耗一同起飞(请回看上方DLSS 4测试中原生分辨率部分的截图),动辄500W以上的表现也是很惊人。

至于4K光追游戏这块,毫无疑问RTX 5090 D的提升幅度也是很大的。不过就具体帧率来说,想让新一代显卡在这些游戏里面以原生分辨率60fps运行似乎还是难了点。因此也很容易理解为什么NVIDIA要在多年前就着手开发DLSS,并且持续为其增加新特性,毕竟从RTX 20系列到现在,晶体管密度确实提升不少,但是光线追踪画质的进步实在过于迅速了。而接下来,就该是神经网络渲染提升光追画面效率的时代了。
2K分辨率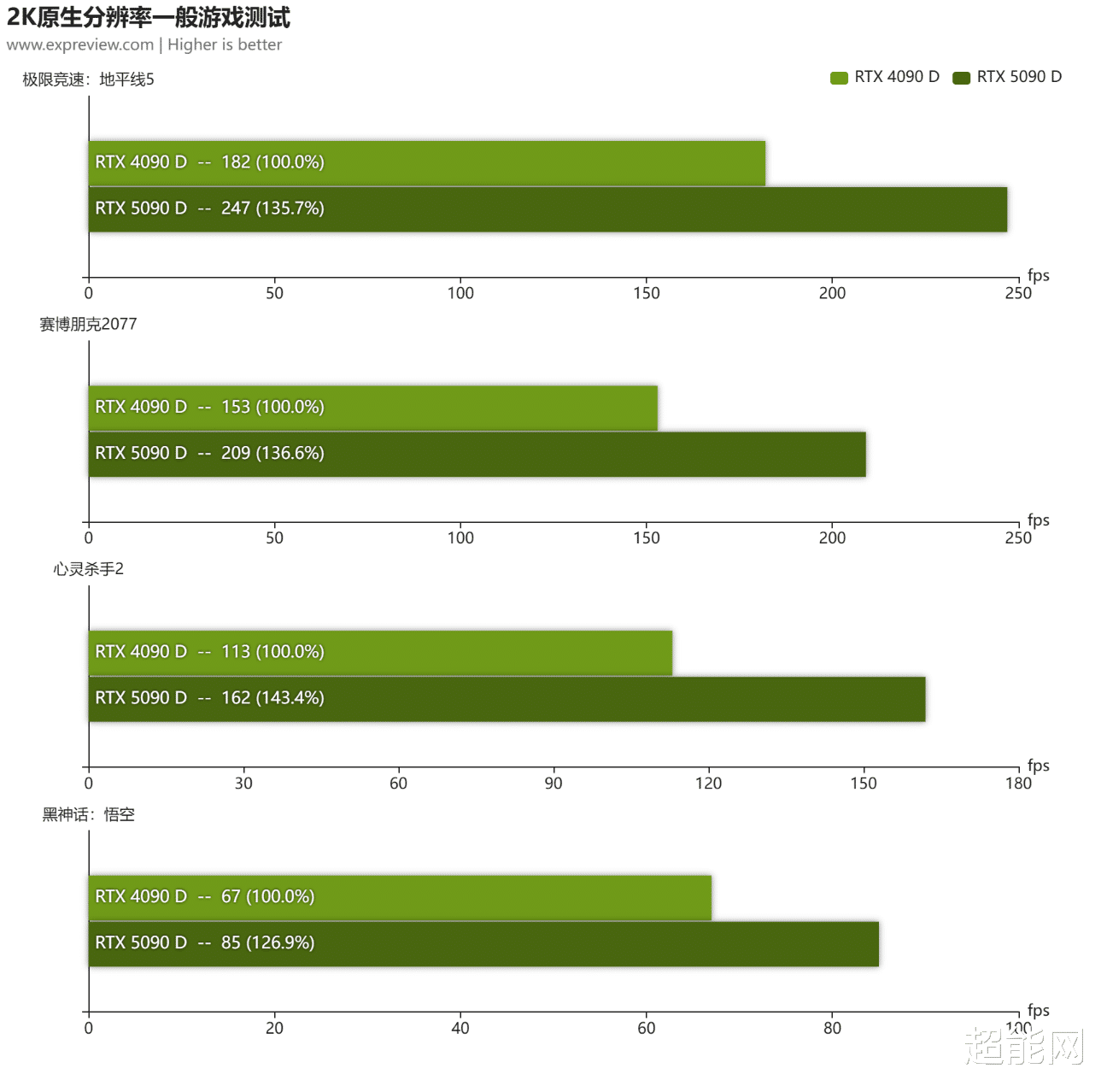

其实2K游戏不算是RTX 5090 D的主场,因为这一张基于GB202核心打造的,具有32GB GDDR7显存的显卡,让它跑2K分辨率多少有点屈尊纡贵了(目前2K分辨率定位的显卡是12GB显存),所以我们就测了几个对显卡压力比较大的游戏。当然,在这个测试环节中,就算因为分辨率降低,两张显卡的差距有所缩小,但RTX 5090 D仍然是把RTX 4090 D抛在比较后面的地方。
AI与生产力测试AI生图与大语言模型

既然RTX 5090 D新增了FP4的支持,那自然是要测试一番的。在UL Procyon FLUX.1 AI生图测试里面,RTX 5090 D在FP4模式下仅用了4秒不到就生成了一张图,而RTX 4090 D花费的时间几乎是它的5倍!在FP8模式里面,RTX 5090 D的速度也要比RTX 4090 D快上不少。


我们知道也有不少玩家会关注常规的FP16性能,因此也做了相应的Stable Diffusion测试。不过测试时,公开的TensorRT加速库还没更新对RTX 50系列的支持,所以我们是用ONNX DirectML运行时进行测试的。在这个测试中,RTX 5090 D仍然领先RTX 4090 D不少。附带一提,其实可以看到即便是ONNX DirectML运行时,RTX 5090 D的生成速度也挺快的了,要是有TensorRT的话,这时间肯定还会更短一点。



接下来是LLM类别的测试,虽然涉及的模型都很多,但在首Token延迟和输出Token速度这些关键指标上,RTX 5090 D在大部分模型里面要比RTX 4090 D好上30%。
生产力创意软件

V-Ray和Blender都是跟3D创作有关的软件,在这里你可以看到RTX 5090 D是如何为创作提速的。相比RTX 4090 D,RTX 5090 D获得了25%以上的增幅。
温度测试我们是在开放平台测试RTX 5090 D的散热。测试分为待机和满载两个场景。待机场景是进入系统后待机5分钟,而满载场景则是3DMark Speed Way运行10分钟。我们用GPU-Z的Log to file功能记录数据,环境温度是22.1摄氏度。得益于分外豪华的散热设计,iGame RTX 5090 D Advanced的满载温度稳定在了65摄氏度上下,延续了上一代的优秀水平。待机温度方面,则是由37.9缓慢上升到42.5摄氏度,和其他带智能启停的显卡一样。

我们通过手中的PCAT套件,分别精确地测量显卡PCIe、外接电源接口的功耗,显卡满载功耗在3DMark Speed Way压力测试中获得,待机功耗则是在进入系统后记录1分钟取平均值。虽然iGame RTX 5090 D Advanced在温度这块表现不错,但毕竟核心规模大了那么多,功耗上升也是可以预料到的事情,测下来显卡的平均满载功耗达到了600W,峰值功耗更能冲上700W。而待机功耗绝大部分时间是在40W以下。电源推荐方面,如果CPU一侧的功耗比较高的话,那1200W及以上的电源大概还是免不了的。

在GPU-Z的Log to File中我们同时记录下了显卡转速情况。由于iGame RTX 5090 D Advanced风扇是独立控制的,我们只标出最速较高的一个,在1900RPM上下。接着我们把显卡放进了环境噪音小于10 dB(A)的消音实验室,把其风扇还原同样转速,然后在30CM的距离上测试其噪音水平,测得的数据是44.6dBA。由于显卡在待机时风扇是停转的,所以就不用测试了。



从规格表上可以看到,Blackwell这一代在制程工艺上不算大改,至少不像从Ampere到Ada Lovelace的变化那么大。RTX 5090 D这一代性能的提升主要来源于规模的扩大,毕竟架构上多了2组TPC,具体到CUDA Core和Tensor Core等组件的数量增长就很可观了。因此在各项涉及硬实力的测试中,我们可以见到RTX 5090 D是领先RTX 4090 D许多的,不管是游戏还是生产力,甚至是AI。再考虑到AMD即将推出的RX 9000系列后缀也只是70顶多再加个XT,我们可以大胆地说,GeForce的纪录只会由GeForce打破,RTX 5090 D就是新一代的地表最强游戏显卡!对于预算不设上限的玩家来说,它的性能是对得起售价的,而它的功耗也注定了需要一个足够强劲的ATX 3.0电源去支撑。
评价完硬件性能,我个人想稍微延伸一点,接着讨论神经网络渲染和DLSS 4这部分。从4K原生分辨率的光追游戏测试结果可以看到,即便Blackwell GB202拥有着如此庞大的规模和新一代的RT Core,也无法在这种设置下有着三位数的帧率。不妨试想一下,要把CUDA Core和RT Core的数量增加到什么程度才能把全景光线追踪游戏的帧率再提升一截?这显然是一个近似不可能的任务。但是通过DLSS 4这条捷径,我们是能够达到这种目标的:同等渲染分辨率下,Transformer模型对细节的修复比起CNN更胜一筹;多帧生成则以倍数级别把帧率提升到喂饱高刷屏的程度;Reflex将延迟控制在50ms以内,这些都是可以测试和实际游玩感受到的东西。当传统方法无力应对的时候,用新生事物另辟蹊径往往带来更好的结果。

不过话又说回来,自从DLSS诞生以来,我看到评论区和别的地方有不少玩家也会坚持一种观点,那就是AI拉伸填补的像素,和AI生成的帧都是“假”的。这种颇为形而上学的意见说实话我也不是不能理解。但是反过来说,什么才是“真”的游戏画面呢?粗糙的模型、坚硬的阴影,无法映出天空的水潭和缺乏合理间接照明的山洞,只是因为它们没有一个像素是由AI填充所以是“真实”的?比路径光线追踪所创造的光影关系更“真实”?这显然不太合理。图形学有一个很重要的定律就是:“如果它看起来是对的,那么它就是对的。(If it looks right,it is right.)”如果DLSS能够让我们的眼睛觉得没问题,玩的时候不感觉到画面的缺陷,那DLSS所创造出来的游戏体验就必然比这些所谓的不经AI的“真实”更加“真实”。而从上面的对照图来看,其实DLSS 4已经有这么一个实力了。
这个观点也可以沿用到同样基于AI的神经网络渲染上,在官方网站和Editor's Day上,NVIDIA已经用多个demo向我们展示了RTX Kit神经网络渲染套件所能创造的华美画质。如果未来应用神经网络着色器的游戏能够如这几年《赛博朋克2077》和《黑神话:悟空》那样带给玩家足够冲击力的画面,那“真”与“假”的争论自然会烟消云散。当然,为了让一些神经网络渲染新功能可以被及时点亮,在此之前你得备好一块Blackwell显卡就是了。
