今天是6月30日,2024年的第26周,恰逢周日。在这个宁静的时刻,我决定对古老师本周的文章进行一次深入的复盘。复盘的目的不仅是为了总结解题思路,回顾关键知识点,更是为了建立一套关键词索引,以便于未来快速检索。过去,由于缺乏这样的整理工作,我常常发现自己难以回忆起曾经写过的案例或某些重要知识点,有时甚至连源文件也无处可寻。通过今天的复盘,我希望能够改变这一状况,让知识的管理变得更加高效和有序。

图 1
星期一 6月24日源文链接
431 智能整理:一键自动化解决 PMC 客户信息混乱难题
设计思路
处理那些包含文本、特殊符号及数字且遵循特定模式的信息时,若要根据明确的规则(如数字或文本类型)进行拆分,分列操作显得极为有效,而TEXTSPLIT函数在此过程中尤为突出。它通过枚举所有指定的特殊符号,成功地将复杂混合内容分解开来。一旦内容被妥善分离,若需对各部分进行有序排列(确保姓名位于首位,手机其次,地址最后),则可利用LENB函数来测定每段信息的字节数,为多条件排序工具SORTBY提供排序标准,最终促成客户信息地址从杂乱无章转变为条理清晰的一维表格格式。

图 2
核心函数
TEXTSPLIT:负责分割混合文本。LENB:用于计算字符串的字节长度。SORTBY:根据多个条件执行排序。创新亮点
利用文本的字节长度作为多条件排序的一个维度,增强了信息整理的逻辑性和高效性。
参考公式
=DROP(REDUCE("",TOCOL(B3:B2000,3),LAMBDA(X,Y,VSTACK(X,LET(x,TEXTSPLIT(Y,{" ",";",",","。"}),SORTBY(x,LENB(x)))))),1)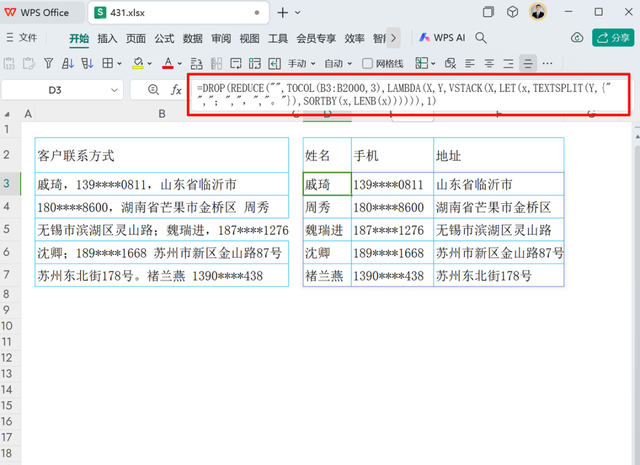
图 3
星期二 6月25日源文链接
432 告别繁琐手工整理:一键重塑采购报价单的自动化攻略
设计思路
面对单元格内含有多种信息的情况,首步是检查数据是否利用换行符进行了分隔。当遇到一系列单元格普遍存在换行数据,需统一整理时,可通过TEXTJOIN函数,采用特殊符号“#”作为连接符,将这些单元格内容合并为单一单元格。接下来,利用TEXTSPLIT按照行列需求进行细致拆分。
为解决拆分后数据维度可能不匹配的问题,采用HSTACK水平拼接原单元格内容(即拆分前状态)。此过程中,若遭遇数组尺寸不一导致的#/NA错误,则利用IFNA函数予以规避。最后,借助REDUCE与LAMBDA的组合,通过迭代堆叠操作,完成数据的系统化整理。
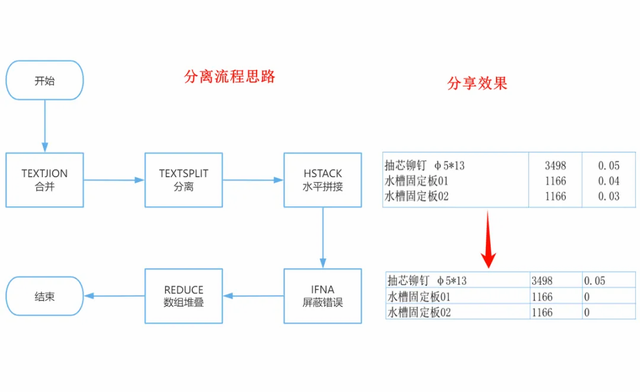
图 4
核心函数
TEXTJION:文本合并函数TEXTSPLIT:文本分离函数IFNA+HSTACK:水平拼接组合REDUCE+LAMBDA:垂直堆叠 组合创新亮点
先合并、再分列,后堆叠
参考公式
=REDUCE(B2:F2,B3:B5,LAMBDA(X,Y,VSTACK(X,LET(A,OFFSET(Y,,,,2),B,OFFSET(Y,,2,,3),IFNA(HSTACK(A,TRANSPOSE(TEXTSPLIT(TEXTJOIN("#",,B),CHAR(10),"#"))),A)))))
效果如下图所示:

图 5
星期三 6月26日源文链接
433 PMC一招搞定任务分配!如何用WPS智能识别多项目负责人?
设计思路
在解决团队成员项目分配辨识问题时,例如快速区分负责单一项目与多个项目的员工,可遵循以下方案:首先,利用COUNTIFS函数统计每位员工参与项目的总次数。若某员工出现次数超过1次,则视其负责多个项目;此时,通过UNIQUE函数剔除重复条目即可识别多项目人员。相反,计数结果为1的员工则负责唯一项目。

图 6
核心函数:
COUNTIFS:实现条件计数UNIQUE:移除重复项FILTER:数据筛选IFNA + HSTACK:处理缺失值并水平合并数组创新亮点:
结合计数结果(大于1或等于1)的逻辑判断,直接产出TRUE或FALSE逻辑值,作为FILTER函数筛选条件,高效区分不同类别员工。
参考公式
=IFNA(LET(C,C3:C16,HSTACK(UNIQUE(FILTER(C,COUNTIF(C,C)>1)),UNIQUE(FILTER(C,COUNTIF(C,C)=1)))),"")
利用计数判断逻辑,借助FILTER筛选出多项目与唯一项目的员工名单,通过UNIQUE去除重复,并利用IFNA搭配HSTACK优雅处理可能的空值情况,最终输出清晰的分类结果。效果如下图所示:

图 7
星期四 6月27日源文链接
434 从新手到高手:小明的职场晋级之路——月销售汇总攻略
设计思路
针对职场新人在处理月销售汇总时,以下是三个实用策略概述:
1.数据透视表:
优点: 操作简便,只需拖放字段。
缺点: 数据更新需手动刷新。
2.辅助列公式:
优点: 能自动实时反映数据变化。
缺点: 需要额外的工作表空间。
3.动态数组方法:
优点: 快速一键生成汇总数据。
缺点: 需要Excel较新版本支持。

图 8
核心函数:
SEQUENCE: 生成连续的月份序号。MONTH: 从日期中提取月份。MAP + LAMBDA: 将传统公式转换为动态数组公式。HSTACK: 实现数据的水平拼接展示。创新亮点:
引入了MAP函数与LAMBDA表达式,巧妙构建动态数组,依据由1至12的序列(代表各月),结合MONTH函数提取的实际销售记录中的月份,通过逻辑比较确定匹配项,并乘以对应销售额,以此高效汇总特定月份的销售总额。
参考公式
=LET(A,SEQUENCE(12),VSTACK({"月份","销售额"},HSTACK(TEXT(A,"#月"),MAP(A,LAMBDA(X,SUM((MONTH(B3:B368)=X)*(C3:C368)))))))
该公式首先定义了一个代表1至12月份的序列,然后构建了一个汇总表,其中包含月份标签及通过动态数组计算得出的每月销售额。利用逻辑判断确保仅汇总指定月份的销售记录,实现了灵活且高效的月度销售汇总功能。

图 9
星期五 6月28日源文链接
435 销售王者速查手册:WPS高级公式助力月末冠军统计
设计思路
对于寻找数据集中的极值问题,核心策略围绕数据排序(借助SORT函数)与定位查询(通过VLOOKUP函数)展开。具体而言,先对数据进行排序操作,使得极值(最大值或最小值)位于列表的首尾位置,随后利用VLOOKUP根据需求找到这些极值。若追求更进一步的自动化,结合使用UNIQUE、筛选函数和LAMBDA,可实现去除重复项并一键生成所需极值信息。

图 10
核心函数:
SORT:实现数据排序,为极值定位奠定基础。VLOOKUP:根据排序后的数据,高效查找出目标极值。LAMBDA:用于创建自定义函数,封装复杂逻辑,提高公式灵活性。VSTACK/HSTACK:用于数组的垂直或水平拼接,便于构造输出结构。UNIQUE:移除重复数据,确保分析结果的唯一性。CHOOSECOLS:灵活选取数据集中的特定列,为SORT提供精确数据范围。创新亮点:
本方案创新性地融合了排序与灵活查询技术,通过先对数据进行智能排序,再运用列选择与自定义函数fx,不仅能够迅速锁定极值所在,还能通过用户自定义的方式,实现高度定制化的极值提取。最终,利用数组拼接函数优雅地组织输出结果,提升了数据处理的效率与直观性。
参考公式
=LET(U,UNIQUE(C3:C13),fx,LAMBDA(x,VLOOKUP(U,SORT(CHOOSECOLS(B3:D13,2,1,3),{1,3},{1,-1}),x,0)),VSTACK({"小组","姓名","销售额"},HSTACK(U,fx(2),fx(3))))

图 11
星期六 6月29日源文链接
436 告别手动盘点:SCAN加REUDCE函数自动化公式精准预测缺货时间
设计思路
在制定生产计划时,为了根据客户需求精准判断潜在的缺货时间,可以采用一种策略:首先利用公式计算库存与预计消耗量之间的差额。具体实施步骤包括筛选出各零件的特定需求,通过FILTER函数实现;接着利用TAKE函数仅保留相关需求量。采用SCAN结合LAMBDA函数逐步累加这些需求,模拟库存随时间的减少情况。随后,借助VLOOKUP或XLOOKUP函数匹配每个零件的当前库存,并从累计需求中减去库存量,进行零值检测,任何结果小于零的指示着库存短缺。此时,返回对应的逻辑标记,代表该零件处于欠料状态。最后,利用XLOOKUP根据欠料状态查找并返回预期的缺货日期。

图 12
核心函数
FILTER:针对性地选取满足条件的数据行,便于后续的针对性分析。TAKE:从筛选出的数据集中提取指定数量的元素,聚焦关键需求量。SCAN + LAMBDA:动态累积需求量,模拟库存随时间递减的过程。VLOOKUP/XLOOKUP:跨表或数组中查找并引用对应零件的库存数值。REDUCE + LAMBDA:将结果进行垂直堆叠,使其公式一键生成。创新亮点:
本方法通过智能化的数据筛选与灵活的计算逻辑整合,有效解决了生产计划中预测缺货时间的挑战。其精髓在于结合现代电子表格的强大函数,特别是SCAN与自定义LAMBDA函数的协同工作,不仅能够精准监控库存消耗趋势,还允许用户根据实际需求调整算法逻辑,实现高度个性化的缺货预警系统。此外,利用一系列数组操作函数的高效拼接,大大增强了数据分析的直观性和时效性,为生产调度提供了有力支持。
参考公式
=DROP(REDUCE("",F3:F10,LAMBDA(m,n,LET(a,FILTER(C3:D19,B3:B19=n),b,SCAN(0,TAKE(a,,-1),SUM),VSTACK(m,XLOOKUP(1=1,VLOOKUP(n,F3:G10,2,)-b<0,TAKE(a,,1),""))))),1)

图 13
最后总结
经过一周文章的深度复盘,我不仅重温了各种复杂数据处理技巧,还构建了一套详尽的关键词索引体系,这无疑为未来的知识检索与应用奠定了坚实基础。从智能整理客户信息的TEXTSPLIT与SORTBY精妙配合,到重塑采购报价单的TEXTJOIN与REDUCE创新串联,每一案例都展示了电子表格函数在提升工作效率上的巨大潜力。通过PMC任务分配的COUNTIFS与UNIQUE逻辑结合,以及月销售汇总中动态数组与MAP+LAMBDA的灵活运用,我们见证了数据处理逻辑从简单到复杂的优雅过渡。销售王者统计中的智能排序与自定义LAMBDA函数,以及自动化预测缺货时间的SCAN与REDUCE策略,更是凸显了现代办公软件在复杂数据分析上的强大能力。

图 14

图 15
