
最近,你可能听说过一则让技术圈议论纷纷的消息。
那就是DeepSeek的新推理系统每天能赚取56万美金,利润率甚至高达545%。
这听起来有点像天方夜谭,毕竟之前还有不少人坚信DeepSeek是在赔本赚吆喝。
争论四起,也让这家公司再次成为大家茶余饭后的话题。
为了更好地理解这个现象,我们一起来看看整个事件是如何发生的。
上周五,DeepSeek宣布他们的开源周收官,很多人以为这就是结尾了。
没想到,周六一早,DeepSeek团队又放出一个重磅消息:他们全新的推理系统——DeepSeek-V3/R1,居然能够实现令人瞠目结舌的性能和利润。
这突如其来的发布会像是一颗重磅炸弹,让科技圈的人们都议论纷纷。
很多人开始讨论,这一切究竟是如何做到的?
为了解答这些疑问,我们需要深入了解这套系统背后的技术秘密。
DeepSeek的推理系统之所以如此强大,与他们最新采用的跨节点专家并行(EP)技术密不可分。

简单来说,通过将专家分布在不同的GPU节点上,DeepSeek大大提升了系统的处理效率和吞吐量。
举个例子,想象你在一个大型超市购物,每个货架上都摆满了商品。
如果只有一个收银台,你肯定会排上长长的队伍。
而DeepSeek的EP技术,就像在超市的每个出口都布置了一个收银台,让购物变得迅速而高效。
这种技术显著减少了每个GPU的负担,避免了长时间的计算和等待。
对于用户来说,这意味着他们的请求能够更快地得到响应。
EP技术的引入,不仅提高了吞吐量,还有效降低了延迟。
有了优秀的硬件配置和并行计算能力,DeepSeek并没有止步于此。
他们还特别注重通信重叠与负载均衡的问题。
你可以将通信重叠看作是在排队的过程中,同时进行多项任务,以提高整体效率。
例如,当你在咖啡店排队时,同时可以查看新闻或回复邮件,这样即使排队时间长了,你也不会觉得浪费时间。

DeepSeek的系统设计也是同样的道理。
通过将通信和计算重叠进行,他们显著减少了GPU之间的通信开销。
此外,针对不同的工作负载,他们还设计了专门的负载均衡机制,确保每个GPU节点都能发挥最大效能,不至于让某些节点过载,而其他节点则处于空闲状态。
负载均衡就像是在球赛中,每个球员都能适时地接到球,不会因为某个球员过于疲惫而影响整体表现。
让我们看看财务数据是怎么回事。
DeepSeek能实现如此高的利润率,关键在于他们的成本控制和高效的计费模式。
我们以实际数据为例,在过去24小时内,DeepSeek的推理系统共处理了约6080亿个输入token和1680亿个输出token。
每个H800 GPU节点的租赁成本是每小时2美元,而DeepSeek的收入却远远超过了这个成本。
按照DeepSeek-R1的定价,每百万个缓存命中的输入token收费0.14美元,而缓存未命中的则收费0.55美元,输出token则高达2.19美元每百万个。
通过这种精细化的计费方式,DeepSeek不仅覆盖了成本,还获得了可观的利润。
即便如此,实际收入可能还会低于理论值,这是因为DeepSeek对用户友好,某些服务仍然是免费的。
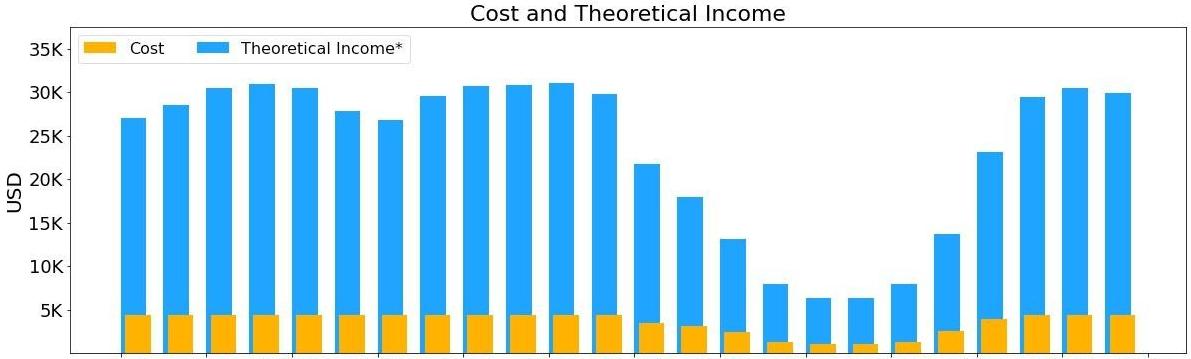
即便在夜间低负载时段,他们也会实施自动应用夜间折扣。
这种灵活的计费机制,不禁让人感慨其高效和人性化。
DeepSeek这次的成功并非偶然,他们的每一步策略和技术选择都经过了深思熟虑。
这不仅使得他们能够在激烈的技术竞争中脱颖而出,还为其他公司树立了一个新的标杆。
通过精准的负载均衡、创新的跨节点专家并行技术以及合理的计费体系,DeepSeek交出了一份令人惊叹的答卷。
从最初的争议到最终的事实胜于雄辩,DeepSeek用数据和技术证明了自己的实力。
对于每一个关心技术进步和商业发展的读者来说,DeepSeek的故事无疑是一次深刻的启发:当技术与市场精准对接时,往往能够创造超意想不到的价值。
所以,当下次你听到有人讨论DeepSeek是赔本赚吆喝时,不妨分享一下这个故事。
或许,只有深入了解,才能真正体会科技进步背后的力量和魅力。
