
国内掀起了智算中心建设潮,但在建设中,人们发现智能算力有典型的“木桶效应”。光有GPU还远远不够。
文|牛慧
编|赵艳秋
从去年到今年,业界正进入大模型2.0时代。它意味着,无论是追逐更大参数的大语言模型,还是业界投入重兵的多模态模型,大模型训练的数据集已从TB级迈向了PB级,也对算力提出十倍甚至百倍的增长需求。业界出现了万卡甚至十万卡集群,并拉动了新一代智算中心的建设。
为应对暴涨的算力需求,国内掀起了智算中心建设潮,建设方来自地方政府、云计算大厂、央国企、数据中心服务商,以及一些跨界企业,呈现出百花齐放的状态。
但在建设中,人们发现“智能算力有典型的木桶效应”。光有GPU就够了吗?根据实际案例,组建算力集群不是简单的“盖楼”,算力并不会随着卡的数量线性增长。从多元芯片,到服务器集群,再到整个数据中心的网络、存储......如果其中有一块短板,昂贵的GPU算力都会大打折扣。
针对这些现象,不久前腾讯云与智慧产业事业群CEO汤道生也提到对AI的认知和投入不能“狭隘”,称人工智能有很多其他的技术路线,也很值得关注,要搭建一套有用的智能系统。AI不止于大模型。
01
智算中心建设热,光有GPU不行?
大模型越来越火,业界为算力资源伤透了脑筋。为了打消客户对缺卡的顾虑,如腾讯云一众云计算大厂,提供了“一云多芯”大规模AI异构算力。
与此同时,不少建设方已在启动自身智算中心的建设。比如在地方政府侧,自2017年国家发布人工智能发展规划之后,智算中心就被提到战略高度。2023年,工信部等六部委印发了《算力基础设施高质量发展行动计划》,明确提出到2025年我国算力规模超过300EFLOPS,其中智能算力占比达到35%。在国家倡导下,各地政府热情高涨,政策覆盖的20多个省市,将建设40多个智算中心。
与此同时,在智能算力中,仍有70%~80%由企业唱主角。除了云计算大厂外,央国企也是一股关键力量。根据数智前线的统计,仅今年前五个半月,国内大模型中标项目已超过230个。运营商、金融、教育、能源、政务、汽车等领域,涌现出大量招标项目。在主要大项目中,有超六成来自于央国企。不少央国企也提出自建智能算力的需求,支撑自身人工智能平台建设,并满足数据安全需求。
此外,数据中心服务商、传统解决方案提供商,也纷纷布局智算中心。
上述很多建设方的一个特点是,手里有卡和硬件资源。他们的需求是,用自己的卡能不能组建大模型算力集群,从而在自己的专属算力环境下训练大模型?
实际上,有GPU卡或者GPU集群,离一个高效运转的私有化智算中心,还相差甚远。腾讯云专有云研发副总经理王旻说,大集群并不等于大算力!算力不是靠简单地“堆”GPU服务器堆出来的。
“智能算力存在比较典型的木桶短板效应。”腾讯专有云研发负责人王旻进一步解释,大模型训练过程中,集群通信时间最高占比可达50%。这意味着,网络不给力,GPU只能闲着。再如,RDMA网络0.1%的丢包率就会造成将近50%的算力损失。因此,客户需要一套没有短板的全栈方案,才能构建一个高效实用的私有智算中心。
针对木桶短板效应,腾讯云最新推出了专有云智算套件。“在过去的发展中,我们服务了大量的公有云客户和自研业务。这次将公有云积攒的技术能力向外输出,支持私有化部署。”腾讯云副总裁沙开波说。
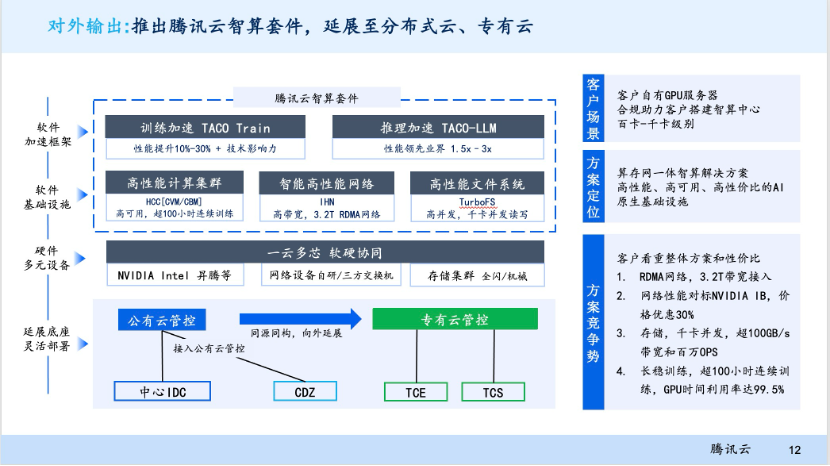
在客户的GPU硬件服务器基础之上,智算套件集合了高性能计算集群HCC软件能力、RDMA智能高性能网络IHN(星脉网络)、高并发文件存储系统TurboFS、算力软件加速框架Taco-LLM,实现万亿参数大模型训练时间缩短 80%。
利用腾讯云智算套件,客户现在可以开始搭建自己的计算集群了 ,而套件的亮点也解决了行业突出的共性问题:
稳定的HCC高性能计算集群:支持超过100小时的连续稳态训练。通过自研服务器、自研网络、存储架构等软硬件设施,让万亿参数大模型的训练时间,从50天缩短至4天。
智能高性能网络IHN(星脉网络):它应验了那句话,要想富先修路。智算中心已从CPU时代进入GPU时代,如果把GPU比作F1跑车,要让跑车的性能发挥到极致,就要给它建立专业赛道。不久前,腾讯自研星脉网络全面升级为2.0,目标是在工程上支持10万卡规模。在性能上,它相比上一代网络通信效率提升了60%,让大模型训练效率提升20%。
极速存储高性能文件系统TurboFS:在大模型训练时,数据存储约占整体工程量的30%。随着模型参数和计算集群越来越大,不同存储技术,可能造成数十倍的性能差距。TurboFS的高并发千卡级别并发读写能力,在私有算力环境下,可以支撑4000卡在一分钟内完成TB级CheckPoint(工作日志检查点),对于处理大模型训练、故障检查都非常关键。
高效加速框架TACO-LLM:训练框架可以指导GPU更高效完成任务,加速框架为不同场景的训练和推理设计了不同方案。在突破GPU自回归限制和连续显存瓶颈后,让模型推理速度提升了2倍。采用模型压缩、量化、混和序列并行模式等后,模型训练速度提升30%。
这一智算套件中的产品技术,已经过大规模实践验证。沙开波说,在公有云上,它们服务了百万客户,并在腾讯内部服务了混元大模型,而混元已接入腾讯广告、腾讯会议、微信读书在内的超600款场景。
02
自身没有卡,怎么建专属智算中心?
除了上述客户的需求外,很多客户手里没有GPU卡和硬件资源,但也需要构建自己的智算中心。
“大模型产业还处于很早期。”汤道生曾分析当下的市场状况,“大家都在跑马圈地,尝试着不同的商业模式。有的在追 Scaling Law(规模效应),有的在打造 to C 市场新入口,有的在做产业落地,非常热闹。”因此,这些企业对智能算力提出多样化需求,也并不奇怪。
针对这样的需求,腾讯云提出了分布式云产品,来帮助没有GPU和硬件资源的伙伴,从零到一打造自己专属的智算中心。
什么是分布式云?简单来说,就是腾讯云在客户本地提供公有云服务。此前,公有云的算力资源、业务数据和管控系统“三大件”,都在云厂商的IDC里,并由云厂商运维,客户只需要使用。
现在,分布式云复用了公有云的“管控系统”,而客户核心的“算力资源”、“业务数据”则部署在自己指定的数据中心提供服务。为此,腾讯云提供了专属可用区CDZ和本地专用集群CDC两种形式,由公有云运维团队进行运维。
分布式云有什么优势,尤其是在大模型快速迭代和应用部署的当下?腾讯云计算产品高级产品经理张祥春说,使用传统方案建设,客户建设、运维的门槛都很高,并且在建成之后,整个环境不太可能做版本升级,服务能力被固化了,而分布式云与公有云是同步升级的。
这意味着,客户不仅能在自己需要的地点便捷搭建专属的智算云,更能不断使用到腾讯云最新的智算技术。这对客户快速推进人工智能业务极为关键。毕竟最新的技术,让客户能跑的更快。
值得关注的是,分布式云也打包了腾讯云最新的智算套件、大模型部署与精调的AI平台层能力、数据管理平台层的能力,以及代码助手等开发层能力,这样,客户就有了完整的AIGC训练和应用能力。
这恰好符合一部分当下客户的需求。根据专业机构的调研,68%的企业需要混合多云架构基础设施,70%的企业希望构建大模型之后,实现每周甚至更频繁的更新,57%的企业期望基于现有大模型,进行模型定制化或微调,另外77%的企业希望第三方帮助其做大量非结构化数据的处理和分析。
当通过分布式云的方案搭建起平台,客户就能一步触达这些需求,分布式云因而受到欢迎,已有不少落地案例。张祥春介绍了三类典型场景。
在大型智算中心场景下,国内一家大型智能化解决方案服务商,使用本地专用集群CDC,组建了自己的大型智算中心。国内某大型二手交易平台,使用专属可用区CDZ,搭建大型本地云,既满足数据安全要求,又享受到与公有云一致的体验。
在企业边缘算力需求场景下,智算服务与各行业结合越来越深,智能驾驶、智能制造对于边缘区域的低延迟算力、数据不离场、可靠性高的要求越来越多。某国内大型工业制造企业,使用本地专用集群CDC,实现了工厂智能制造方案底座,IT团队管理效率提升4倍。某Top级车企,使用本地专用集群CDC,支撑智能制造、车联网大数据业务。
此外,在企业出海场景下,企业的业务系统需要在当地部署,并且要符合海外的数据合规策略。企业将内部云拓展到海外,是一项耗时耗力的工程,还可能经历数年的稳定期。而腾讯云可基于在海外可用区建设、运维的经验,向客户交付分布式云。某国内Top级消费电子企业,已使用本地专用集群CDC,满足南美工厂本地云需求。
03
AI原生云将主导智算未来
在快速构建智能算力、满足大模型训练和推理大爆发的算力诉求之外,实际上,这轮生成式AI,对整体云计算提出了更高的要求。在这一过程中,腾讯云在不断自我革新与升级,演进到为生成式AI而生的AI原生云。
日前,腾讯云和Gartner联合发布的首个《AI原生云建设与加速指南》白皮书中提到,我们将见到从Cloud for AI向AI原生云的转变,这一转变标志着云平台能力的全面革新。AI原生云平台是AI原生时代发展的重要基石,将全方位、更高效、便捷地支撑AI原生应用的创新。

腾讯云为用户提供生成式AI驱动的新一代AI原生云平台架构,除了在基础设施层(Allnfra)上的升级和革新外,也在模型层(Models&Frameworks)、工程工程层(Al Engineering)、应用层(AI Apps)、全栈安全防护(Security)上构建了核心能力,助力大模型训练、推理,到应用,全面加速,释放产业各类MaaS生产力,加速AI原生应用落地。
其中,为了让更多人能够快速部署AI服务,在工程平台层面,该解决方案提供了基于腾讯云高性能服务HAI与云端开发工具CloudStudio的GPU开发空间;腾讯云向量数据库提供了数据检索增强套件能力;腾讯云机器学习平台TI提供了从数据标注到模型推理的工具链。在此之上,腾讯云OrcaTerm AI助手、AI代码助手可以提供智能运维、技术问答、代码补全等AI辅助能力。
在模型层,腾讯自研的大模型混元最大参数量级已过万亿,在国内率先采用混合专家模型 (MoE) 结构,部分中文能力已追平GPT-4,在“时新”问题的回答表现上,数学、推理等能力上均有较大提升。同时,腾讯会议等腾讯SaaS产品已经全面接入腾讯混元大模型。
在安全方面,腾讯全栈安全产品已深度融合AI技术,并在实际攻防场景与内容安全中守护安全防线,实现AI信任。
在应用层,腾讯云不仅直接提供腾讯会议、腾讯文档、企业微信、腾讯乐享、腾讯企点等智能应用APP,还提供智能应用增强软件,如数智人、知识引擎、智能客服等,同时提供基于这些智能应用APP孵化出来的各种生成式AI助手与引擎等技术产品能力,帮助用户全面实现应用智能增强。
在以生成式AI为代表的人工智能的发展中,AI原生云将是一个比传统云计算更为巨大的市场,产业升级给云大厂带来了巨大机遇。而腾讯云平台基于生成式AI的全面升级,目前已成为AI原生时代的领航者。基于逐步构建和完善的五大核心能力,帮助企业在AI时代实现快速发展和创新,抢占AGI风口。
