本文由马里兰大学,微软研究院联合完成。作者包括马里兰大学博士生陈玖海,主要研究方向为语言模型,多模态模型。通讯作者为 Bin Xiao, 主要研究方向为计算机视觉,深度学习和多模态模型。其他作者包括马里兰大学助理教授Tianyi Zhou , 微软研究院研究员 Jianwei Yang , Haiping Wu, Jianfeng Gao 。

论文:https://arxiv.org/pdf/2412.04424
开源代码:https://github.com/JiuhaiChen/Florence-VL
项目主页:https://jiuhaichen.github.io/florence-vl.github.io/
在线 Demo:https://huggingface.co/spaces/jiuhai/Florence-VL-8B
模型下载:https://huggingface.co/jiuhai/florence-vl-8b-sft
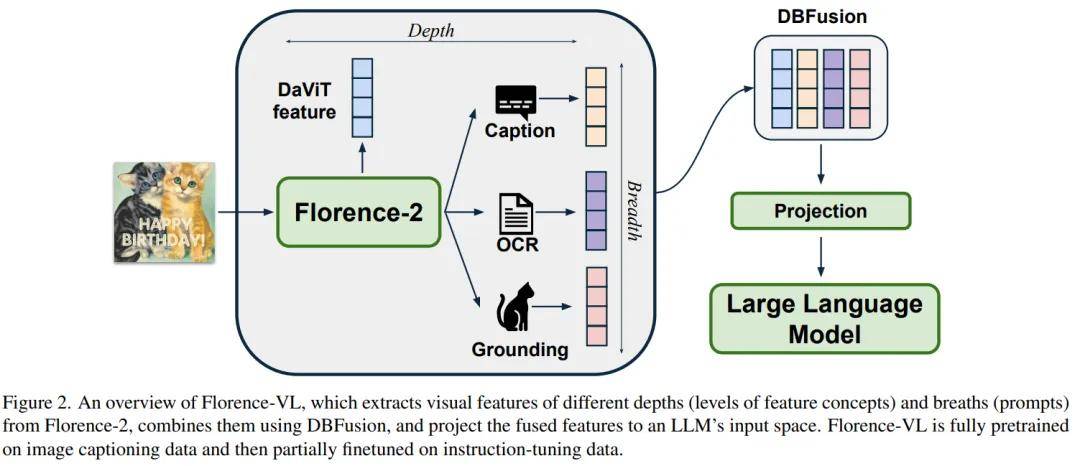
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。 然而 Florence-2 通过生成式预训练,将多种视觉任务(如图像描述、目标检测、文字识别和对象定位)统一为 sequence-to-sequence 结构,并通过 prompt 来完成多样化的视觉任务。在 Florence- VL 中,我们仅使用一个视觉编码器 Florence-2,但采用多个不同的 prompt,分别注重 caption,OCR 和 grounding,来获得不同层次的视觉表征。通过融合这些不同深度的特征,Florence-VL 实现了更全面的视觉理解。


引言
随着大规模语言模型(LLM)的快速发展,多模态大语言模型(MLLMs)成为视觉与语言任务的主流解决方案。然而,现有的视觉编码器(如 CLIP 和 SigLIP)虽然在整体语义提取方面表现出色,但存在明显不足:
缺乏细粒度理解:仅捕获图像的整体语义,忽略像素级和局部区域的细节。
任务泛化能力有限:难以适配 OCR、物体定位等需要特定视觉特征的任务。
Florence-VL 正是针对这一问题提出的解决方案。通过引入生成式视觉基础模型 Florence-2,Florence-VL 在保持高效训练的同时,能够灵活适配不同任务,弥补传统视觉编码器的缺陷。
在接下来的部分,我们将详细介绍 Florence-2 背后的技术原,Florence-VL 如何利用多任务视觉特征,以及我们提出的深度 - 广度融合策略如何实现视觉信息的高效整合。
背景介绍:Florence-2
传统视觉编码器如 CLIP 和 SigLIP 主要依赖对比学习来预训练,虽然能在跨模态任务中取得不错效果,但其输出的图像特征通常是单一的全局语义表示,难以捕获细粒度信息。这一缺陷使得这些模型在 OCR 文本提取、对象定位等任务上表现不佳。
Florence-2 则采用了生成式预训练的方式,将多种视觉任务统一到一个编码 - 解码框架中,能够根据不同任务提示生成多样化的视觉特征。
Florence-2 的主要流程包括:
视觉编码器 DaViT:将输入图像转换为基础视觉特征。
任务提示机制:通过不同的文本提示调整生成目标,从而提取任务特定的视觉信息。
编码 - 解码框架:结合视觉和文本特征,输出满足不同任务需求的结果。
通过这一架构,Florence-2 实现了全局语义到局部细节的视觉特征生成,为多模态任务提供了更全面的视觉表示。接下来我们将介绍如何使用 Florence-2 来构建 Florence-VL。
方法:深度与广度融合 (DBFusion)
Florence-VL 的核心创新在于我们提出的深度 - 广度融合(Depth-Breadth Fusion)策略,它充分挖掘 Florence-2 的生成式特性,将多任务提示和多层级特征有效结合,形成更丰富的视觉表征。
1. 广度:通过任务提示扩展视觉表征
不同的视觉任务需要不同的视觉信息。例如:
Captioning:用于理解图像整体语义,生成描述性文本。
OCR:提取图像中的文本内容,尤其适用于带有文字的图像。
Grounding:用于定位物体,捕捉物体之间的关系。
Florence-2 通过不同的任务提示,生成针对性强的视觉特征,从而实现视觉特征的 “广度” 扩展。
2. 深度:整合多层级的视觉特征
Florence-2 的不同深度层能够捕获从 low- level 到 high-level 的视觉特征,这种多层级特征的结合,保证了视觉编码器既能关注细节,又能捕获整体信息。
3. 融合策略:通道拼接实现高效整合
为了将多任务和多层级的特征高效融合,我们设计了通道拼接(Channel Integration)策略。具体做法是将不同特征按通道维度拼接,并通过 MLP 映射到语言模型的输入空间。这一策略的优势在于:避免了增加训练与推理时的序列长度以及最大程度保留了视觉特征的多样性与完整性。
分析:多种视觉编码器的对比
为探讨不同视觉编码器(如 CLIP、SigLIP、DINOv2 和 Florence-2)和大语言模型的对齐能力,我们采用了实验来定量评估不同视觉编码器与语言模型的跨模态对齐质量。具体方法如下:对于每组图文配对 (image- caption pair),视觉编码器生成视觉特征,语言模型生成文本特征,我们通过可训练投影对视觉特征和文本特征进行维度对齐,并且通过对齐损失函数来评估视觉编码器和语言模型的对齐能力。实验结果表明,Florence-2 相较于其他视觉编码器显示出更优的跨模态对齐能力。

实验验证
为了全面评估 Florence-VL 的性能,我们设计了一系列实验,涵盖通用视觉问答、OCR、知识理解等多模态任务。
1. 实验任务与数据
通用视觉问答:如 VQAv2、GQA 等。
OCR 与图表任务:如 TextVQA 和 ChartQA,侧重文本提取与图表分析。
视觉主导任务:如 CV-bench 和 MMVP, 侧重视觉信息理解。
知识密集型任务:如 AI2D、MathVista 等,测试模型对基本知识的理解能力。
我们使用了经过筛选的 15M 图像描述数据 (detailed caption)与 10M 高质量指令微调数据进行训练,以确保数据的多样性和高质量。

2. 实验结果
在实验结果中,Florence-VL 在多个多模态基准任务上展现出卓越的性能优势。特别是在 TextVQA 和 OCR-Bench 等文本提取任务上,得益于 Florence-2 生成式视觉编码器提供的细粒度 OCR 特征。此外,在通用视觉问答任务,视觉主导任务,知识密集型任务中,Florence-VL 通过深度 - 广度融合策略有效结合了多层级、多任务视觉特征,使得整体准确率相比传统 CLIP-based 方法有所提升。
3. 消融实验
为了证明采用 Florence-2 作为视觉编码器的优越性,我们使用 llava 1.5 的预训练和指令微调数据,并且采用和 llava 1.5 相同的训练策略。我们发现 florence-VL 显著优于 llava 1.5, Florence-VL 在 TextVQA 和 OCR-Bench 等任务中表现突出,显示出生成式视觉特征在提取图像文字信息中的优势。

总结
在本文中,我们提出了 Florence-VL,一种基于生成式视觉编码器 Florence-2 的多模态大语言模型。与传统依赖对比学习的视觉编码器(如 CLIP)相比,Florence-2 通过生成式预训练能够捕捉更丰富的视觉特征,提供多层次、多角度的图像表征。我们设计了创新的深广融合(Depth-Breadth Fusion)策略,通过整合不同深度层次和任务提示生成的视觉特征,将视觉信息全面映射到语言模型输入空间。通过广泛的实验,我们验证了 Florence-VL 在多种任务中的卓越表现,包括通用视觉问答、OCR、图表理解和知识密集型任务等。在未来,我们将进一步探索:例如自适应融合策略:根据任务动态调整深度与广度特征的平衡等。
