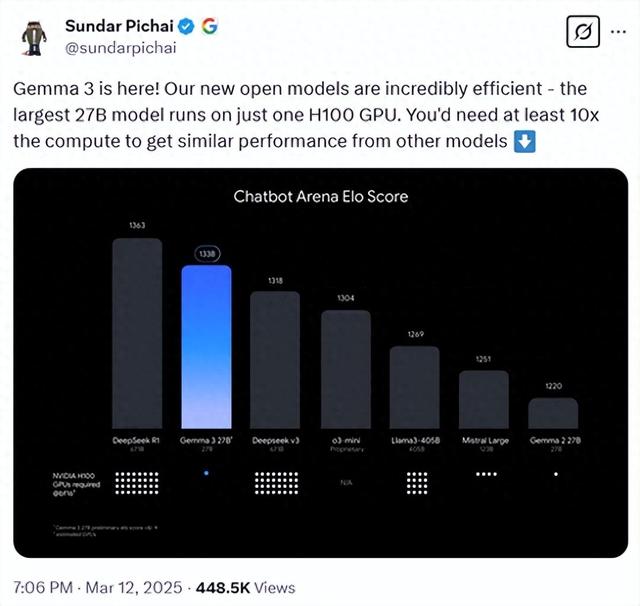
近期,谷歌的首席执行官Sundar Pichai在两天前的晚间透露了一个重要消息:谷歌将开源其最新的多模态大型模型Gemma-3,该模型以低成本与高性能为特色。Gemma-3提供了四种参数规模供选择,分别是10亿、40亿、120亿和270亿。值得注意的是,即便是参数量最大的270亿版本,也仅需一张H100显卡即可实现高效推理。相比之下,要达到相同效果,同类模型所需的算力至少要高出10倍。这使得Gemma-3成为当前性能卓越且参数规模较小的大模型之一。
根据LMSYS ChatbotArena的盲测数据,Gemma-3的表现十分亮眼,仅次于DeepSeek的R1-671B模型,而优于OpenAI的o3-mini、Llama3-405B等多个知名模型。DeepSeek的R1模型在业界的地位显著,每当有新的高性能低成本模型发布时,往往会与R1进行比较。
就在谷歌宣布Gemma-3之前不久,阿里巴巴也开源了一个名为QwQ-32B的模型,该模型的性能与R1相当,但参数量却减少了20倍。如今,谷歌也加入了低成本模型的竞争行列,预示着这一领域将变得更加激烈。
开源地址:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
Gemma-3架构与技术亮点
在架构设计层面,Gemma-3沿用了与前两代模型相同的Transformer解码器基础框架,但在此基础上实施了多项创新性和优化措施。针对长文本上下文处理中常见的内存占用剧增问题,Gemma-3巧妙地采用了局部与全局自注意力层交替配置的策略。具体而言,它在每连续的五个局部注意力层之后,巧妙地插入了一个全局注意力层。其中,局部注意力层的焦点集中在较短的文本片段上,即每段仅处理1024个token,以此来减少内存消耗。而全局注意力层则专门负责处理跨越整个文本上下文的长期依赖关系。通过这种设计,Gemma-3有效地平衡了处理长文本时的内存效率与模型性能。

Gemma-3模型在长上下文支持方面进行了显著优化,将上下文长度扩展至128K token(10亿参数版本为32K)。为了提升长上下文场景下的性能,模型对全局自注意力层的RoPE基础频率进行了调整,从10k提升至1M,而局部层的频率则保持在10k不变。此外,模型采用了类似位置插值的技术,扩展了全局自注意力层的跨度,使其能够更有效地捕捉长上下文中的信息,从而提升整体表现。
多模态能力是Gemma-3的核心技术亮点之一,它能够同时处理文本和图像数据。为了实现这一能力,模型集成了定制版的SigLIP视觉编码器。该编码器基于Vision Transformer架构,并通过CLIP损失的变体进行训练,进一步增强了模型在多模态任务中的表现。这些技术改进使Gemma-3在长上下文和多模态场景下展现出更强的竞争力。

Gemma-3在图像处理方面引入了一系列创新技术,旨在降低推理成本并提升性能。首先,模型采用了图像嵌入压缩技术,将视觉嵌入压缩为固定大小的256个向量。这种方法在保留关键信息的同时,显著减少了计算资源的消耗,从而提高了推理效率。
此外,Gemma-3还引入了Pan&Scan方法,以灵活处理不同分辨率和宽高比的图像。具体来说,Pan&Scan将图像分割成多个固定大小的区域,并将这些区域调整到统一分辨率后再输入编码器。这种处理方式有效避免了因图像尺寸不一致而导致的信息丢失或变形问题,增强了模型对图像内容的理解能力。这一技术使Gemma-3在处理复杂图像场景时表现更加出色,进一步提升了其在实际应用中的实用性。
高效训练过程
在预训练阶段,Gemma-3在继承Gemma 2方法的基础上进行了多项改进。为了适应图像和文本混合数据的训练需求,模型显著增加了token预算。具体来说,270亿参数版本使用了14T token,120亿参数版本使用了12T token,40亿参数版本使用了4T token,而10亿参数版本则使用了2T token。
此外,Gemma-3还引入了更多的多语言数据,包括单语和并行数据,并采用了特定策略来解决语言表示不平衡的问题。这些改进显著提升了模型的语言覆盖范围和多语言处理能力。最终,Gemma-3支持140种语言,其中35种语言可以直接使用,无需额外调整。这一扩展使模型在全球化应用中更具竞争力。

Gemma-3采用了与Gemini 2.0相同的SentencePiece分词器,该分词器具备分割数字、保留空格和字节级编码的特性。其生成的词汇表包含262k个条目,这使得模型在处理非英语语言时表现更加均衡。
在训练优化方面,Gemma-3运用了知识蒸馏技术。具体来说,每个token会采样256个logits,并按照教师模型的概率分布进行加权。学生模型通过交叉熵损失学习教师模型在这些样本中的分布。对于未采样的logits,教师模型的目标分布被设为零概率并重新归一化,从而引导学生模型学习更优的分布,进一步提升性能。
完成预训练后,Gemma-3进入后训练阶段,这一阶段专注于提升模型的特定能力并整合新特性。后训练采用了改进版的知识蒸馏技术,从大型指令微调的教师模型中获取知识,同时结合基于改进版BOND、WARM和WARP的强化学习微调方法。
为了优化模型,Gemma-3使用了多种奖励函数,旨在提升模型的帮助性、数学能力、编码能力、推理能力、指令遵循能力和多语言能力,同时最小化模型生成有害输出的可能性。这些奖励函数的数据来源包括从人类反馈中训练的加权平均奖励模型、代码执行反馈以及解决数学问题的真实奖励等。这一系列优化措施使Gemma-3在多种任务场景下表现出色。
测试数据
为了全面评估Gemma-3的性能,谷歌在多个主流测试平台上进行了测试,包括MGSM、Global-MMLU-Lite、WMT24++、RULER和MRCR等。测试结果表明,Gemma-3在多模态任务中表现优异,尤其是在DocVQA、InfoVQA和TextVQA等任务上,其性能显著超越了前代模型。
在长文本处理能力方面,Gemma-3的270亿参数版本在RULER128K测试中取得了66.0%的准确率,充分展现了其在长上下文场景下的强大能力。这些测试结果进一步验证了Gemma-3在复杂任务和多样化场景中的卓越表现。

在多语言支持方面,Gemma-3在MGSM和Global-MMLU-Lite等任务中表现优异,展现了其强大的多语言处理能力。在对话能力评估中,Gemma-3的270亿参数指令调优版本在ChatbotArena测试中获得了1338的Elo分数,成功跻身前10名,其表现接近DeepSeek-R1等大型模型,进一步证明了其在对话任务中的竞争力。
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。
欢迎关注“福大大架构师每日一题”,让AI助力您的未来发展。
