
就在今天下午两点,快手正式发布了可灵 2.0。
作为国内文生视频的口碑一哥,可灵生成的 AI 视频在各大视频平台都被创作者们广泛应用,这次的升级发布会吸引到了很大的关注。
从昨天官方发出的预告片就基本可以猜出,可灵 2.0 主打运动能力。
果不其然,在可灵 2.0 更新后,官方也如此解释:可灵 2.0 的优势在于高质量运动和指令响应。
于是,知危编辑部速速搞了一个黄金会员来试玩。
一开始,编辑部真的被可灵 2.0 的费用惊到了:一个 5s 的片段,竟然就要 100 灵感值。要知道,可灵文生图最高清的只需要 1 个灵感值一张,可灵 1.6 的 5s 视频只需要 35 灵感值,新版足足贵了 2 倍。换算成人民币,可灵 2.0 一个 5s 视频大概 10 块钱。
当然,贵不一定是它的问题,如果生成结果足够好,也就值了。
参考可灵 2.0 发布会中强调的重点,我们主要测试了可灵 2.0 的这些特点:运动速度、运动幅度、复杂运动、时序响应、多模态编辑。
我们根据每个特点测试了 1 到 2 个视频,然后看每个视频能不能体现这些基础特性:指令遵循、电影美学、精准风格化等。
首先是运动速度和运动幅度,我们来测试一个跑车场景。
参考图:

提示词:
跑车在蜿蜒道路上高速行驶,偶尔过弯时轮胎打滑,摄像机从空中移动到车辆后方追踪沿海公路上行驶的跑车。
相机从空中持续追踪跑车,与车辆背后保持 5 米距离,保持车辆在画面中心。
道路两侧景观快速后退,海面波光粼粼。
汽车广告电影风格,景色壮观,色彩鲜明,动感强烈。
生成结果如下:

这个生成结果不算差,但在这么卷的 AI 视频赛道里,这个结果也就中规中矩,跑车速度不够快,没有高速行驶的动态感,像是飘在公路上,背景变化幅度小,汽车表面的光影效果也一般,最后是没有按照提示词第一句将镜头做转移。
有可能是提示词过于复杂了,让 AI 手忙脚乱。我们换一个场景,测试第一人称视角的过山车场景。
参考图:

这次把提示词写得简单些:
过山车列车先爬上高点,然后从高点开始急速下降,车厢随轨道高速移动。
第一人称视角,相机飞行在半空中,跟随过山车后方全程运动。
刺激游乐设施体验风格,色彩鲜艳,画面快速运动感强,高清晰度,阳光照射产生闪光效果。
生成结果如下:

这次的结果很不错!不仅实现了先升再下降的高速大幅度运动,远处的景观比如比如蓝色海盗船、红色屋顶小房子、摩天轮都以合理的方式拉近了物理距离。当然手稍微有点小崩,可以理解,瑕不掩瑜。
我们再换一个场景,测试电影中常见的追逐场景。
参考图:

提示词:
主角穿越赛博朋克世界的闹市进行追逐,背景环境不断变化。
主角奔跑速度均匀,不时回头,表情紧张。
相机保持与主角相同速度跟随,略微摇晃增加紧张感。
场景从拥挤市场变为狭窄小巷,再到开阔广场,人群散开。
动作电影风格,节奏紧凑,色调对比强烈,光影变化明显。
生成结果如下:

这个效果也很棒,除了主角运动速度很快之外,还展了背景运动的大幅度变化。在主角回头和转身瞬间的背景模糊,和回头后的场景的切换,都很有电影的感觉。不过有个有些滑稽的小缺点是,提示词中只是让主角 “ 不时回头 ”,结果他却直接转身了。
追逐戏只有一个人怎么够刺激,再加一个。
参考图:

提示词:
两名未来战士在霓虹长廊里前后追逐。
前方战士快步疾跑,后方战士穷追不舍,动作紧张有序。
镜头不断变换焦点:先对准前方逃跑者,再聚焦后方追击者。
环境光线闪烁,节奏感强烈,但场景本身保持相对稳定。
写实电影质感,展示快速视角切换带来的逼真动感。
生成结果如下:

这回真的翻车了,没有实现焦点的切换,可灵 2.0 还给前面的战士赋予了 “ 电子穿梭 ” 的能力,穿梭的战士又从后方的战士出现,一时间不知道谁在追谁。可能模型对 “ 未来战士 ” 的理解就是会有这样的超能力,视频乍一看有些怪,细看你别说还有点像某种刻意的设定......
要体现速度,也许只靠人工动力还是太渺小了,得借助万有引力的力量。
我们再换一个测试场景,看一下山坡能带来多大的速度感。
参考图:

提示词:
专业滑雪者从雪山顶峰滑下陡峭斜坡,速度超级快。
滑雪者身体前倾,双腿灵活控制方向。
相机从滑雪者后方跟随下滑,保持适当距离,偶尔切换到侧面。
滑雪道两侧雪松轻微摇晃,雪花随风飘动。
冬季运动广告风格,明亮雪景,蓝白色调为主,阳光反射效果。
生成结果如下:

效果还是不错的,滑雪的速度有逐渐变快,雪橇踩过的雪花飞溅效果挺合理,远景变化也没毛病。遗憾的是,知危没舍得花 200 灵感值来生成 10s 的视频,不然速度肯定能更快。
山坡释放的万有引力势能还是有限,我们到天上去。
参考图:

提示词:
跳伞者从高空飞机跳出并自由落体。
相机从跳伞者视角转为外部观察视角,跟随自由落体过程穿过云层。
云层迅速接近,地面景观从模糊变得清晰,风吹动衣物。
极限运动纪录片风格,高清晰度,大场景展示,视觉冲击力强。
生成结果如下:

非常神奇,跳伞运动员先是消失,然后在穿过一朵云之后又出现,疑似发生了 “ 量子隧穿 ” 现象。
不过,这里要中肯的说一句,编辑部内部反思了一下,我们的提示词可能表述的不够好,让模型误以为 “ 最开始画面看跳伞者的人,也是一个跳伞者 ”,这样生成的视频的状态就可以合理解释了。
测试完了运动速度和运动幅度,接下来我们看一下复杂运动,这一维度主要针对主体本身的动作是否足够复杂多样。
比如,我们可以让这个小哥来跳一跳专业的机械舞,把动作都设定好。
参考图:

提示词:
一位街舞舞者站在城市广场上。
首先,他迅速做出一个机械舞的定格动作,关节锁定;然后立即过渡到一个波浪式的胸部和手臂律动;最后马上完成一个下蹲后弹跳并做出定格手势的动作。
保持Hip-Hop节奏感和街舞特有的力量感。
相机初始保持中景拍摄,随后在波浪动作时轻微环绕舞者,最后在弹跳动作时切换为微慢动作并适当拉近,捕捉定格瞬间。
色彩对比鲜明,舞者动作线条清晰,重要动作环节有轻微强调效果,整体节奏感强。
生成结果如下:

小哥确实展现了很多个街舞动作,主要在后半部分,比如提示词提到的手臂律动、下蹲后弹跳、定格手势,运镜上展现了先环绕再拉近然后慢动作的效果。缺点就是观感上和机械舞没啥关系,甚至也不怎么像街舞。可能给主体安排了过多的动作,AI 也见招拆招学会 “ 偷工减料 ” 了。
我们再加大动作难度,安排两个舞者来跳探戈舞。
参考图:

提示词:
一对专业舞者在舞台上表演激情探戈舞。
舞者从静止姿势开始,展开一系列协调精准的舞步。
相机在舞者周围环绕,时而靠近时而远离,捕捉动作细节。
舞台灯光随舞蹈节奏变化,背景灯光闪烁。
舞蹈电影风格,动作流畅精准,情感表达强烈,灯光戏剧化。
生成结果如下:

虽然看起来会有很多槽点,但忽略女舞者在转身的时候有点过于 “ 着急 ”,总体来看舞者的动作还是很优美而专业的,运镜也没毛病。通常来说存在两个主体交互的场景出错概率都很大,至少这个案例中要接近完美已经不远了。
复杂运动测试完,我们再看看可灵 2.0 的时序响应能力如何,时序响应即按照指令一个接一个地执行的能力,知危主要测试了做饭的场景,并直接进行了文生视频的操作。
提示词:
一位女厨师站在现代化厨房的料理台前,料理台上放着西红柿,鸡蛋,调料瓶,平底锅,油,炉子等,平底锅已经放置在炉子上加热。
她迅速拿起一个西红柿开始切片;
然后立即将切好的西红柿倒入平底锅中;
最后她马上拿起旁边的调料瓶往锅中撒调料。
整个动作序列必须在5秒内流畅完成,没有中断或停顿,动作之间的转换自然连贯。
生成结果如下:

额,看起来厨师拿起西红柿没有切,而是当成鸡蛋一样敲碎了放进去,然后在放调料的时候因为瓶盖太紧了没来得及打开时间就结束了。
或许我们的要求太苛刻了,要完成这些动作只用 5s 还是太紧张了,那就咬咬牙,给厨师 10s 的时间吧。我们来看看结果如何:

比之前好了一些,但是手撕番茄的毛病还是没改,那调料瓶的时候调料瓶抽搐了一下,但是时序上的遵循确实是没毛病。不过我们认为可能是我们短时间内要求的动作太多了。为了让可灵 2.0 更好地完成顺序指令,建议动作还是少一些,简单一些。
最后,我们测试一下新版中比较有趣的多模态编辑功能。这个功能类似于 Gemini Flash 2.0 和 GPT-4o 的局部编辑功能,只不过这一次是视频,复杂度更高。多模态编辑不支持使用可灵 2.0,我们用可灵 1.6 来测试。
借用推特网友的现成视频( 基于可灵 2.0 ),我们来做个微调。
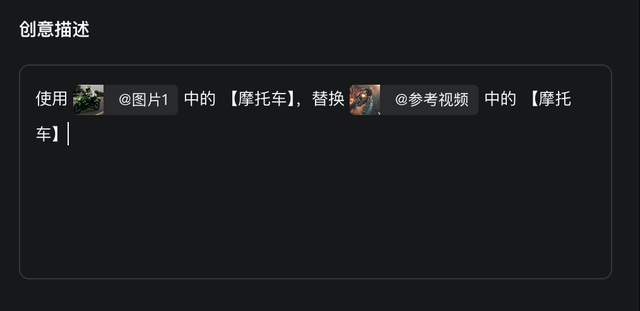
首先是这个网友制作的摩托车越野的场景:

我们用下图中的摩托车来替换原来的摩托车:

在 “ 替换元素 ” 选项下,先标记你需要替换的区域,基本上点击一个摩托车的关键点,可灵就能识别出你要修改的是摩托车。

另外,多模态编辑的提示词格式也很有趣,为了让指代更加精准,提示词已经不是纯文本的形式了,而是结合了图像和文本元素的语句。
生成结果如下:

动作一致性是很高的,就是 AI 顺道把头盔和衣服也换过来了。
我们再换一个视频,这次采用 “ 增加元素 ” 的编辑方式。
这次是一个摩托车极限跑酷的场景:

视频有 10s,但多模态编辑只支持 5s 视频,就裁剪为一半,然后融入这个元素:

提示词:

生成结果如下:

头盔完美地戴上了,整体一致性也很强,就是运动员身体动作和背景动态都有些收敛了。
好了,测试完毕。
总体来看,可灵 2.0 还是有很多可圈点之处的,特别是运动效果和多模态编辑。比如背景变化能保证合理性和大幅度,单主体运动成功率比较高。指令遵循虽然不会 100% 成功,但实现的指令密度还是挺高的。也带来了不少的意外惊喜,比如追逐戏中小哥的回头瞬间,探戈舞的动作标准度。
双主体乃至多主体运动是很有潜力的,只是失败率太大的话,会很费钱。多模态编辑倒是能给你省省钱,毕竟一次只需要 50 灵感值,而且提示词的设置精准度很高,这一点值得给个大赞。
多模态编辑生成结果的运动、动态、外观有较高的一致性,细节上的偏差在所难免。至于时序响应,他的确遵循了时序,但是动作翻车了,不知道是不是我们短时间安排的动作太多了,导致有些翻车。
对了强调一下,知危的测试不代表可灵 2.0 的平均水平,本次整体安排的测试案提示词给的都比较复杂,相机的变化幅度太大。你可以理解为针对新特性的一种极限测试,如果你稍微降低一些要求,效果会好不少。
最后提醒一下,如果你在生成时发现 5s 视频能带来不错的效果,那么可以尝试再生成一个 10s 的,可能有惊喜。如果 5s 视频效果差,也可能是时长不够,AI 来不及完成,如果有 10s 完成概率就大得多,非常建议尝试。
总之,中肯地讲,10 块钱换这样的 5s 视频,还算是值得的。
