尽管大语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。
对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建和部署成本过高。改善成本 - 性能的一种方法是使用稀疏激活混合专家 (MoE)。MoE 在每一层都有几个专家,每次只激活其中的一个子集(参见图 2)。这使得 MoE 比具有相似参数量的密集模型更有效,因为密集模型为每个输入激活所有参数。

出于这个原因,行业前沿模型包括 Gemini-1.5、 GPT-4 等在内的模型都使用了 MoE。
然而,大多数 MoE 模型都是闭源的,虽然有些模型公开发布了模型权重,但有关训练数据、代码等的信息却很有限,甚至有些研究没有提供这些信息。由于缺乏开放资源和对研究细节的深入探索,在 MoE 领域无法构建具有成本效益的开源模型,从而接近闭源前沿模型的能力。
为了解决这些问题,来自艾伦人工智能研究院、 Contextual AI 等机构的研究者引入了 OLMoE ,这是一个完全开源的混合专家语言模型,在类似大小的模型中具有 SOTA 性能。
 论文地址:https://arxiv.org/pdf/2409.02060论文标题:OLMoE: Open Mixture-of-Experts Language Models
论文地址:https://arxiv.org/pdf/2409.02060论文标题:OLMoE: Open Mixture-of-Experts Language Models特别的,该研究使用 5.1 万亿个 token 预训练了 OLMoE-1B-7B 模型,该模型总共拥有 69 亿参数,其中每个输入 token 只激活 13 亿参数。
结果是与使用具有约 1B 参数的密集模型(例如 OLMo 1B 或 TinyLlama 1B )实现了类似的推理成本,只是需要更多的 GPU 内存来存储约 7B 的总参数。实验表明,MoE 的训练速度比具有等效激活参数的密集 LM 快 2 倍左右。
如图 1 所示,OLMoE-1B-7B 显著优于所有开源 1B 模型,并且与推理成本和内存存储明显更高的密集模型相比表现出了竞争力。

通过指令和偏好调优,该研究还创建了 OLMoE-1B-7B-INSTRUCT,它在常见基准 MMLU、GSM8k、HumanEval 等上超越了各种更大的指令模型,包括 Llama2-13B-Chat 、OLMo-7B-Instruct (0724) 和 DeepSeekMoE-16B。
受控实验强调了 MoE(见表 1)和一般 LM 的关键设计选择。结果表明使 MoE 性能卓越的一个关键设计决策是使用细粒度路由和粒度专家(granular experts):在每一层使用 64 个小专家,其中 8 个被激活。
此外,路由算法的选择也很重要:该研究发现无丢弃(dropless)基于 token 的路由优于基于专家的路由。最后,该研究分析了 OLMoE-1B-7B 中的路由行为,发现路由在预训练的早期就饱和了,专家很少被共同激活,并且专家表现出领域和词汇的专业化。

最后,作者希望这个完全开源的 MoE 能够促进更多研究和分析,从而提高对这些模型的理解。训练代码、中间检查点(每 5000 step )、训练日志和训练数据都已经开源。
论文作者 Niklas Muennighoff 表示:OLMoE 是第一个 100% 开源的混合专家 LLM。
 预训练与自适应
预训练与自适应预训练架构
OLMoE 是由 N_L 个 transformer 层组成的语言模型,仅包含解码器。对于 OLMo 这样的密集模型,原本模型中单一的前馈网络被 N_E 个小型前馈网络(专家)组成的混合专家网络所替代,对于每个输入 token x,只有 k 个专家会被选中并被激活,负责处理这个输入。
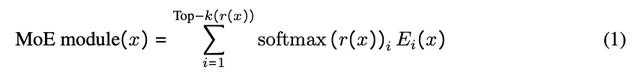
其中,路由器(r)是一个经过训练的线性层,将输入的原始数据映射到被选中的 k 个专家上。对路由器的输出应用 softmax 函数,计算 N_E 个专家的路由概率。然后,每个被指定的专家 E_i 处理输入 x,其输出乘以其各自的路由概率。再将所有选定的

专家的结果相加,构成模型单个层的 MoE 模块输出。
MoE 模型的训练往往涉及对一个已经存在的大型密集模型转换成一个稀疏模型,也就是所谓的「稀疏升级」。这个过程中,需要改变模型的训练目标,比如调整 auxiliary load balancing 以及路由器的损失函数。具体的方法如下表所示:

在这项研究中,论文作者使用了总计 69 亿参数中的 13 亿活跃参数,每层有 64 个专家,其中有 8 个被激活。他们使用了一种名为「无丢弃 token」的路由方法:对于每个输入 token,路由器网络将分配 8 个专家来处理它。
论文作者引入了两个辅助损失函数:负载平衡损失(

)和路由器 z 损失(

),来训练 OLMoE-1B-7B。他们给这两个损失函数分别设定了权重(α 和 β),然后把它们和模型的主要学习目标(交叉熵损失

结合起来,最终计算的损失函数为:

预训练数据
训练数据方面,论文作者使用了来自两个不同来源的数据集:DCLM 和 Dolma 1.7。这些数据集包括了多种类型的数据,比如网络爬取的数据、编程问题解答、数学问题解答和学术论文等。他们将这些数据混合起来,创建了一个名为 OLMOE-MIX 的新数据集。
下表中展示了预训练数据的组成:

对于数据的处理,论文作者使用了过滤器去除了包含太多重复 token 的内容、GitHub 上星标少于 2 的项目以及某些词出现频率过高的文档。他们将在每轮训练开始前随机混洗数据,总计超过 5 万亿个 token。在「退火」阶段(最后 100B 个 token),他们首先重新混洗整个数据集,然后按照此前 OLMo 论文中的方法,将学习率线性衰减到 0。
自适应
论文作者从指令调优和偏好调优两方面,基于之前的开放模型,构造了 OLMoE-1B-7B-INSTRUCT。在指令调优集中,他们增加了更多的代码和数学数据,以提高模型在这些领域的性能。
GPT-4 和 Llama 3 在预训练阶段使用了像 GSM8k 或 MATH 这样的数学数据集的样本。按照这个思路,论文作者还添加了「No Robots」和「Daring Anteater」的一个子集。这些数据集不仅质量高还更多样,这是拓展模型适应性的两个关键因素。
下表展示了 OLMoE-1B-7B-INSTRUCT 所使用的数据:
 实验
实验该研究的评估程序由三部分组成:预训练期间、预训练之后和自适应之后。
预训练期间:如图 3 所示,该研究在预训练期间使用当前最佳 OLMo 模型在常用下游任务上对 OLMoE-1B-7B 的性能进行了基准测试。

研究团队发现,在所有任务中,OLMoE-1B-7B 比密集 OLMo 模型以更少的计算量 (FLOP) 获得了更好的性能。尽管 OLMoE-1B-7B 使用了不到一半的 FLOP 进行训练并且仅使用 1B 个激活参数,但 OLMoE-1B-7B 在训练结束时可与 OLMo-7B 媲美,甚至优于 OLMo-7B。
预训练之后:在表 4 中,该研究在常见的下游任务上对 OLMoE-1B-7B 进行基准测试。
研究发现 OLMoE-1B-7B 在使用少于 2B 个激活参数的模型中表现最好,使其成为许多 LM 用例中最经济的选择。
如果预算较大,Qwen1.5-3B-14B 具有更强的性能,但其激活参数和总参数比 OLMoE-1B-7B 多一倍以上。
研究发现,尽管每条前向传播所需的计算量减少了约 6-7 倍,但 OLMoE-1B-7B 的性能优于一些具有 7B 参数的密集 LM,例如 Llama2-7B ,但不如其他 LM,例如 Llama3.1-8B 。上图 1 比较了 OLMoE-1B-7B 和其他 LM 的 MMLU 性能和激活参数,表明 OLMoE-1B-7B 是其成本范围内最先进的。

自适应之后:在表 5 中,该研究对 OLMoE-1B-7B 的指令 (SFT) 和偏好 (DPO) 调优进行了基准测试。SFT 在所有测量任务上都改进了本文的模型。
DPO 在大多数任务上都有帮助,尤其是 AlpacaEval,这与先前研究的结果一致。DPO 模型(称之为 OLMoE-1B-7B-INSTRUCT)在所有基准测试模型中具有最高平均值。

更多资讯,点击
