你有没有想过,有一天,机器人能准确地执行你指示的任务,而且还不需要特别的调校?
比如,这样一件事——你坐在沙发上,只需跟你的机器人说:“帮我把桌上的书移到书架上。”它就能立即理解并完成这项操作。
听起来像科幻小说中的情节吧?
这已经不是遥不可及了。
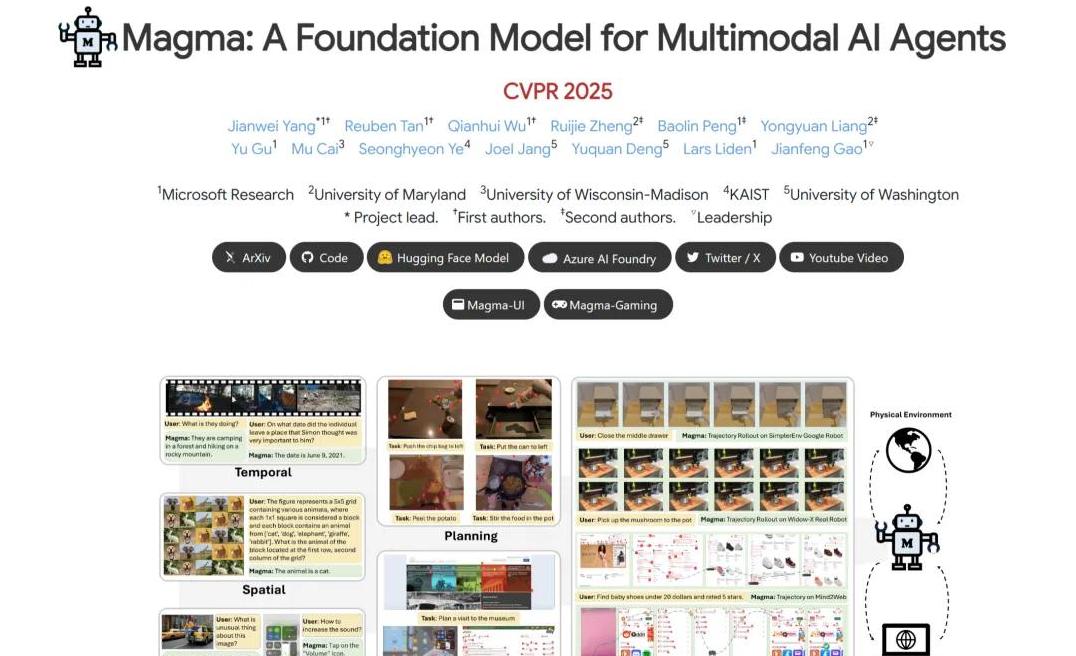
微软最近开源了一款名为Magma的多模态AI模型,它能在网页和机器人任务中轻松完成各种操作,这引起了各界的广泛讨论。
今天,我们就来聊聊这个话题。
先来说说这个叫Magma的模型有什么特别之处吧。
Magma是微软研究院推出的一项新技术,它能够同时理解视觉和语言输入,并凭这些信息做出合适的行动决策。
说白了,这个模型就像是一个懂得听、看、做的智能助手。
想象一下,当你在网上浏览天气信息时,Magma不仅能帮你找到所需的信息,还能为你打开飞行模式。
如果你有一个智能机器人,Magma能让它轻松完成移动物体、发送消息等任务。
这些操作能非常灵活地在数字界面和物理环境中进行,是不是听起来很酷?
两大标注方法:SoM与ToM
为什么Magma这么厉害呢?
它的背后有两大秘密武器。
第一个是叫Set-of-Mark(SoM)的标注方法。
这个方法能让模型关注任务中的关键对象,比如网页中的点击元素或餐桌上的摆放物品。
SoM能迅速定位这些关键对象,帮模型更好地理解任务,从而作出相应的行动。
另一个是Trace-of-Mark(ToM)。
ToM不仅关注静态物体,还能追踪动态视频中的运动轨迹。
你可以把它想象成一个能看懂动作电影情节的智能工具,通过标记物体的运动轨迹,ToM帮模型理解动作的时序变化。

比如,机器人抓取物体时的手臂运动轨迹,人类在视频中的操作等等。
这样一来,Magma就能预测接下来会发生什么,并做出更加精准的决策。
Magma的跨领域应用说到应用,你可能会好奇Magma的实际表现如何。
实话告诉你,它非常厉害。
在多项测试中,包括UI导航、机器人操作与视频理解,Magma无需进行额外的微调就能交出满意的答卷。
比方说,它能在网页界面导航任务中只需少量调整就取得非常突出的成绩;在WidowX机械臂操作和LIBERO任务中,它也大幅领先于其他对比模型。
除了这些,Magma还展现了强大的跨实体泛化能力,能在不同种类物品的抓取与摆放任务中表现出色。
甚至在视频理解和对话场景中,Magma需要的视频指令调优数据量并不多,却在大多数基准测试上与一些先进方法相当,甚至超越它们。
它不仅能描述视频内容,还能对下一步动作进行合理的预测和推断。
这就意味着,无论你让它看电影还是分析监控视频,它都能胜任。
开源与团队背景如果你对这项技术感兴趣,想自行尝试一下,微软已经把Magma模型开源了。
你可以在GitHub上找到它,还能在Hugging Face上获得部分模型权重和示例,方便开发者快速上手。
这对很多程序员来说,是个好消息。
再说说背后的研究团队吧。

你可能想不到,这个团队的大部分成员都是华人,其中不乏在学术界和工业界有着突出贡献的人才。
论文一作兼项目负责人杨健伟博士,是Microsoft Research深度学习组的首席研究员,他在通用多模态智能体领域有着深厚的研究背景。
还有顾禹博士,他主导的PubMedBERT和其它项目对医疗和企业级应用有着深远的影响。
他们的研究不仅推动了学术界的进步,还让AI技术更贴近我们的生活。
结尾回到我们开头说的那个场景,想象一下,未来的某天,智能机器人已经成了你生活的一部分,它不仅能听懂你的话,还能精准地执行各类任务,不需要你事先进行复杂的设置。
微软的Magma模型正让这一天越来越近。
它的强大功能和广泛应用,呈现了一个技术进步带来的美好愿景。

希望有一天,每个家庭都能拥有这样的智能助手,让我们的生活更加便利和高效。
而你有没有想过,这仅仅是AI技术发展的一个开端?
未来还有更多惊喜在等着我们去发现和体验。
