在中美关税大战愈演愈烈之际,一份AI领域的重磅报告——《2025年人工智能指数报告》(HAI报告)出炉。该报告由斯坦福大学李飞飞团队以人为本人工智能研究院发布,已经连续发布8年,在全球AI领域具有很强的影响力。

相比一些商业机构发布的AI报告,HAI报告的编写团队主要由来自斯坦福大学、摩根大通等学术界和产业界的跨学科专家组成,报告内容和数据更客观公正,更有研究价值。因此,HAI报告的研究结论和测试结果,其含金量远高于其他商业报告。
2025年的HAI报告透露出多项AI领域最进展,最值得关注的是,中美顶级模型性能差距缩至0.3%;推理成本暴降,小模型性能飙升,AI正变得更高效、更普惠,这也意味着美国对算力封锁的效果正在打折。
本次HAI报告引入了一项全新评测标准MixEval,是专为评估大语言模型在复杂真实语言任务中表现的测试集,尤其聚焦于“分布式用户查询”和“复杂问题处理能力”,在更具挑战性的MixEval-Hard基准测试中,中美大模型均有上榜,前三名分别是Open AI o1、Claude3.5和LLaMA3.5,都来自美国。
中国有三款大模型入围,分别是讯飞星火(SPARK4.0)位居第十名,零一万物位居第十一名,阿里巴巴Qwen-Max位居第十三名。
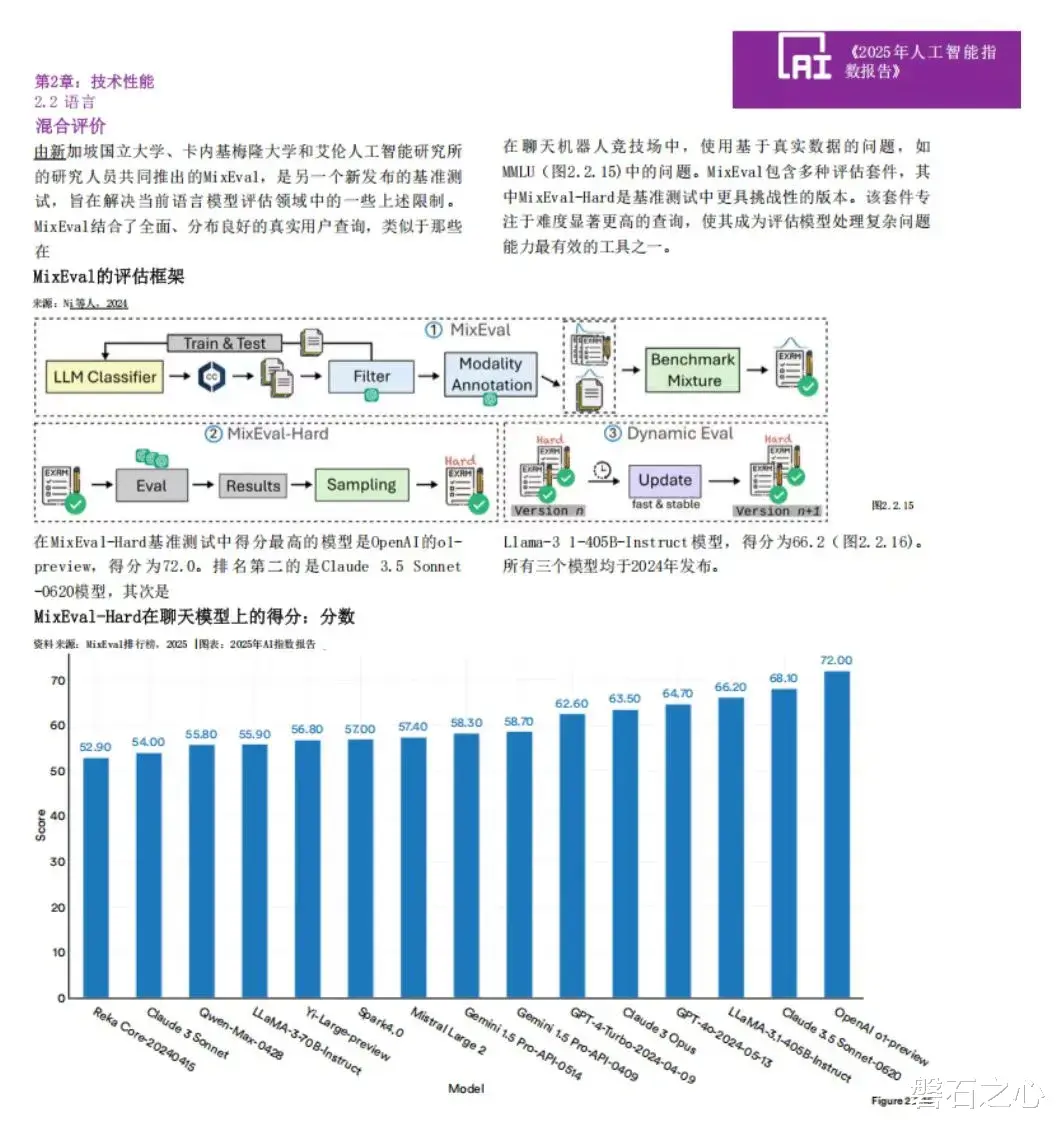
这份测试结果表明,以讯飞星火4.0为代表的国产大模型,在2024年通过不断的迭代和性能突破,已经在国际主流的大模型测试结果中展现出不俗的能力,正在快速追赶中美AI的发展差距。
除了这份大模型性能测试排名外,报告还透露出三点新动向:
首先,中国在AI大模型上是当之无愧的第二名,与美国的差距只有0.3%。这份报告特别对中美大模型进行对比,成为吸睛的部分。从数量上看,2024年美国发布了40个“前沿模型”,而中国为15个,欧洲仅3个。
从论文方面看,2023年,中国贡献了全球23.2%的AI论文和69.7%的AI专利,远远超过美国;而美国在论文总量上仅排全球第三,约为中国的一半。
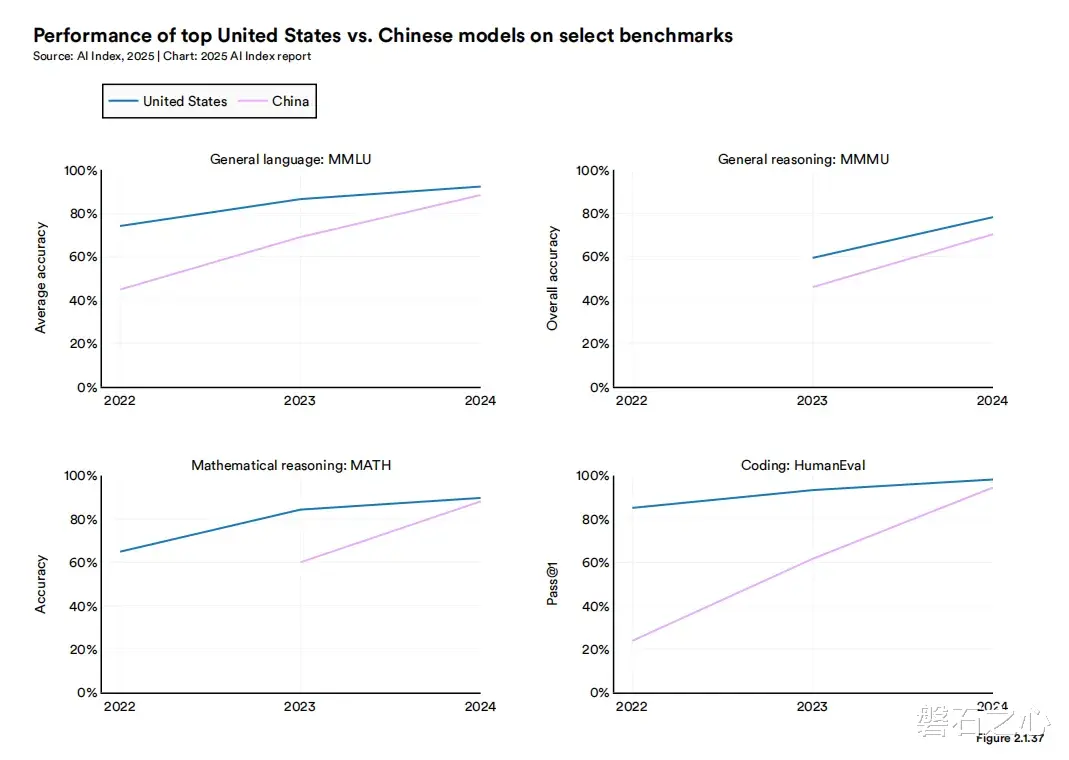
从几项关键指标来看,中国大模型对美国的追赶也可以用“极速”来形容。在MMLU这项多任务语言理解测试中,中美模型在2023年相差17.5个百分点,而到2024年只差0.3%;HumanEval(代码生成任务)也从31.6%的差距收缩到3.7%。
其次,推理成本暴降,“小模型”性能飙升,AI开始普惠。春节后,DeepSeek号称是只用600万美元做出来的,这给OpenAI等依靠堆算力取胜的大模型带来巨大压力,甚至导致美国算力相关股票暴跌。
算力成本下降是不争的事实。报告显示,随着小模型性能提升,达到GPT-3.5水平的推理成本在两年间下降280倍,硬件成本以每年30%的速度递减,能效年提升率达40%。
对于被卡脖子的中国大模型来说,是重大利好。
比如,在MixEval-Hard测试中进入前十的讯飞星火4.0就是在纯国产算力基座上训练出来的大模型,而且2025年3月3日,科大讯飞发布的深度推理模型X1在数学能力上大幅跃升,以70B参数规模便追平了OpenAIo1和DeepSeekR1。
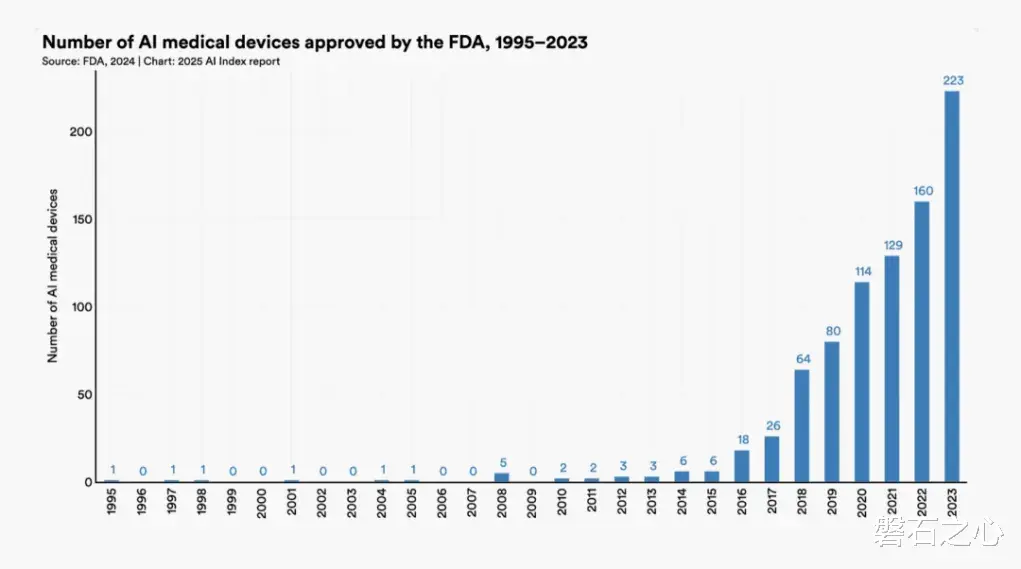
第三,AI医疗已经从梦想走进现实。HAI报告指出:2023年,美国FDA共批准了223款AI医疗设备,而2015年时这一数字还只有6件。报告还表示,OpenAI的GPT-4在复杂医学问诊的测试中,表现甚至优于医生与AI协作小组。
其实,在中国“AI+医疗”也在大规模落地,并诞生了首个上市公司——讯飞医疗。基于星火深度推理大模型X1首发的星火医疗大模型X1已经应用到智医助理、讯飞晓医APP中,实现AI辅助诊断和用户健康咨询。
3月26日,讯飞医疗发布上市后的首个年报,成绩亮眼,全年实现营业收入7.34亿元,同比增长32.0%;实现毛利4.04亿元,同比增长28.4%。
从斯坦福这份报告可以看出,当前,美国仍然是AI大模型领域的第一名,但是中国企业的追赶速度正在加快,与美国之间的差距极速缩小。同时,推理成本大幅减少,让美国对中国算力的封锁效果变差,国产算力的价值逐渐提高。
在中美各种较量之中,AI技术的较量关乎未来,国产大模型的发展令人振奋。
