众所周知,OpenAI旗下的GPT-4是现如今世界上最顶尖的大模型(LLM),但就在本周,有关测试表明,GPT-4“霸主”的地位已经被夺走了。
这个超越GPT-4的大模型叫Claude 3。
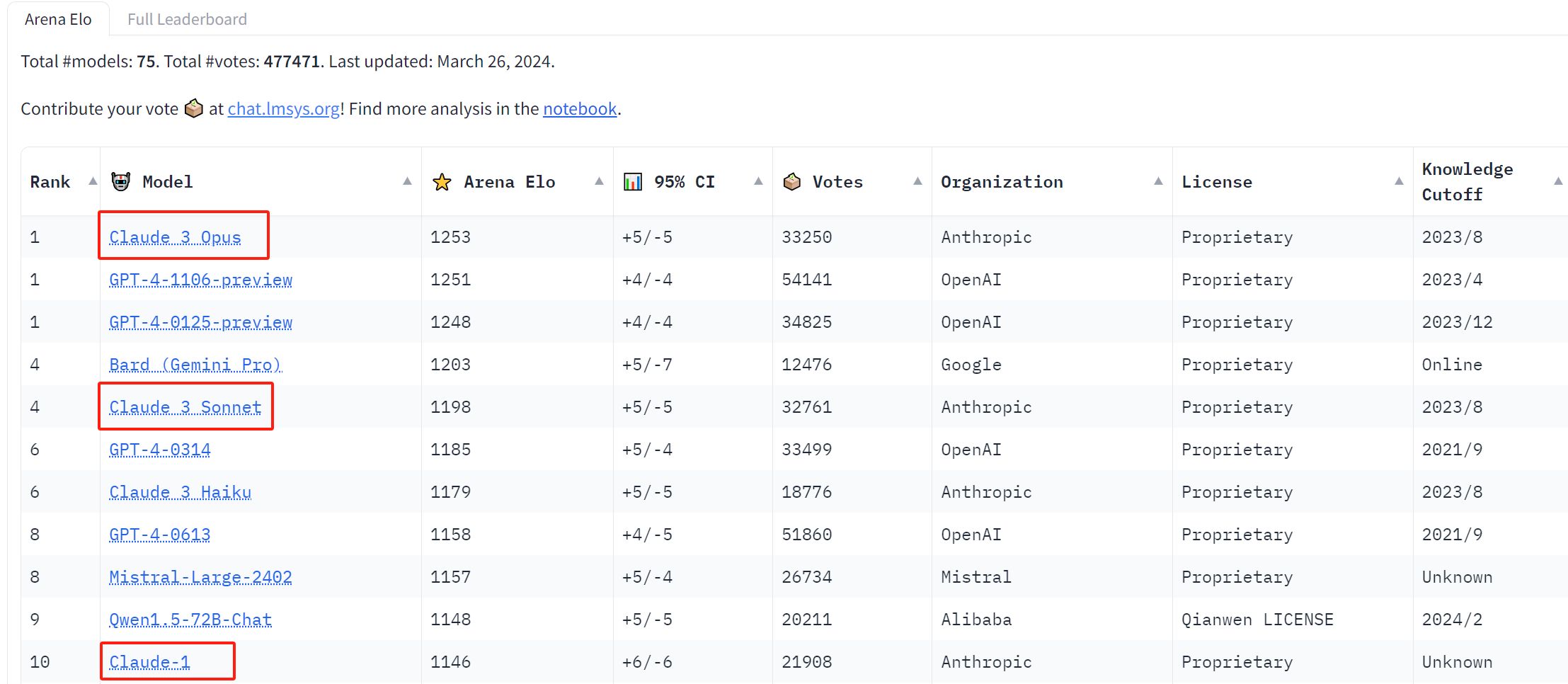
本周,人工智能初创企业Anthropic旗下的Claude 3 Opus在Chatbot Arena(一个测试和比较不同人工智能模型有效性的网站)的最新排名中,首次超越GPT-4,位列排行榜第一。
3月初,Anthropic宣布推出Claude 3大模型系列。该系列包括三个型号,按照性能从弱到强分别是Claude 3 Haiku、Claude 3 Sonnet和Claude 3 Opus。而在Chatbot Arena最新的排行榜上,Claude 3系列三个大模型均闯入TOP 10。
此前,根据Anthropic介绍,其最智能的模型Claude 3 Opus在人工智能系统的大多数常见评估基准上都优于同行,包括本科水平专家知识(MMLU)、研究生水平专家推理(GPQA)、基础数学 (GSM8K) 等。官方称:“Claude 3 Opus在复杂任务上表现出接近人类水平的理解力和流畅性。”
当时Anthropic就表示,在多项指标上,Claude 3已经展现出接近或者优于GPT-4或是Gemini 1.0的性能。此次第三方的测试结果再次佐证了Anthropic的这句话。
Chatbot Arena于去年5月推出,由大型模型系统组织(Large Model Systems Organization,简称“LMYSY Org”)创建。LMYSY Org是由加州大学伯克利分校的学生和教师创立的开放研究组织。创建Chatbot Arena的目的是帮助人工智能研究人员和专业人士了解两个不同的人工智能LLM在接受相同提示的挑战时表现如何。
Chatbot Arena是一个众包平台,这意味着任何人都可以在上面进行测试。在Chatbot Arena的聊天页面,包含了多达74种不同AI模型,包括Claude 3系列、OpenAI的GPT-4、谷歌的Gemini和Meta的Llama 2等等。
当有用户进行测试时,系统会要求用户在底部的提示框中输入问题。然后会有两个匿名模型驱动的聊天机器人来回答用户的问题,这两个模型被简单地标记为模型A和模型B。
在看完两个回答后,系统会要求用户进行评价。用户可以选择哪个更好,可以对它们进行同等评价,也可以表示两个都不喜欢。提交评分后,系统才会告诉用户刚才两个聊天机器人分别是由什么大模型来驱动的。

LMYSY Org会统计网站用户提交的投票,再将总数汇总到排行榜上,显示每个LLM的表现。据了解,自推出以来,已有超过40万名用户成为Chatbot Arena的裁判,最新一轮排名又吸引了7万名用户加入。
根据最新排行榜,Claude 3 Opus共获得33,250票,第二名GPT-4-1106-preview获得54,141票。但获得的评价多,不意味着更强。为了对LLM进行评级,排行榜采用的是Elo 排名系统,这是国际象棋等游戏中常用的一种方法,衡量玩家在某些比赛中与其他玩家相比的相对实力。在使用Elo 排名系统后,Claude 3 Opus在“模型强度的置信区间”上以总分1,253在最新的排名中斩获第一,险胜GPT-4-1106-preview的1,251分。

其中,在“对所有其他模型的平均胜率(假设抽样均匀且无平局)”一项上,Claude 3 Opus是唯一一个胜率过0.7的。
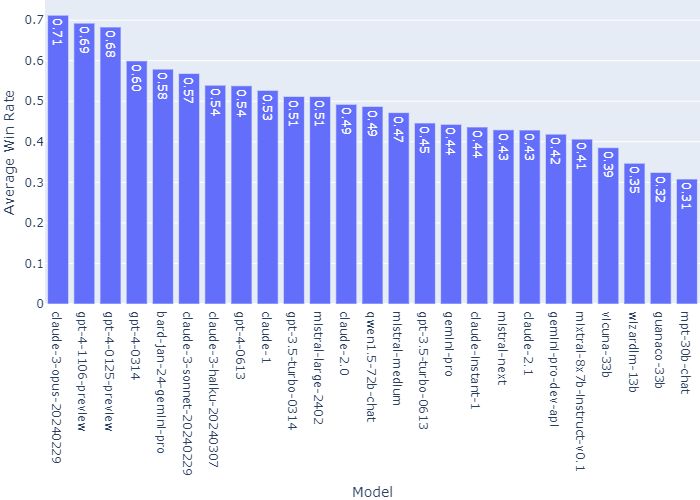
在最新排名中,进入TOP 10的其他LLM包括谷歌的Gemini Pro、Mistral-large-2402和Qwen1.5-72B-Chat等。
随着GPT-4痛失第一的宝座,Claude 3系列模型均进入前10名,再加上Claude 3系列中最弱Claude 3 Haiku击败 GPT-4 0613,Anthropic随即在整个AI圈引起了轰动。
软件开发者Nick Dobos在社交媒体上发文直言道:“国王已死。安息吧,GPT-4。”他表示,Claude 3 Haiku击败 GPT-4 0613是“疯狂的”,因为“它是如此便宜和快速”。

就连LMYSY Org官方也发文称:“Claude-3 Haiku给所有人留下了深刻的印象,甚至根据我们的用户偏好达到了 GPT-4级别!其速度、功能和上下文长度目前在市场上是无与伦比的。”