👆如果您希望可以时常见面,欢迎标星🌟收藏哦~
来源:内容编译自chipsandcheese,谢谢。
英特尔的 Alchemist 架构让该公司在高性能图形领域占有一席之地。Arc A770 被证明是一款出色的首款产品,能够以可靠的性能运行许多游戏。现在,英特尔将接力棒交给了名为 Battlemage 的新图形架构。

Arc B580 总体上比其即将推出的 Alchemist 前代产品更小。B580 有 5 个渲染切片,而 A770 有 8 个。总体而言,B580 有 2560 个 FP32 通道,而 A770 有 4096 个。
Battlemage 也配备了较小的内存子系统。B580 拥有 192 位 GDDR6 总线,运行速度为 19 GT/s,因此理论带宽为 456 GB/s。A770 拥有 560 GB/s 的 GDDR6 带宽,这要归功于 256 位总线,运行速度为 17.5 GT/s。

甚至主机接口也被缩减了。B580 只有一个 PCIe 4.0 x8 链路,而 A770 有一个全尺寸 x16 链路。如果英特尔想要击败其前代产品更大的实现,那么它的新架构还有很多繁重的工作要做。
战斗法师的 Xe 核心
Battlemage 的架构变化始于其 Xe Cores。两代产品之间最实质性的变化实际上是在 Lunar Lake 上首次亮相。Xe Cores 进一步分为 XVE 或 Xe Vector 引擎。英特尔将 Alchemist XVEs 对合并为两倍宽的 XVEs,完成了向更大执行单元分区的过渡。Xe Core 吞吐量保持不变,为每周期 128 个 FP32 操作。

共享指令缓存为 Xe Core 中的所有八个 XVE 提供数据。Alchemist 有一个 96 KB 的指令缓存,而 Battlemage 几乎肯定有一个至少同样大的指令缓存。英特尔 GPU 上的指令通常为 16 字节长,在某些情况下为 8 字节压缩形式。因此,96 KB 指令缓存的标称容量为 6-12K 条指令。
Xe 矢量引擎 (XVE)
XVE 构成了英特尔 GPU 中最小的分区。每个 XVE 最多跟踪八个线程,在它们之间切换以隐藏延迟并保持其执行单元的供给。64 KB 寄存器文件存储线程状态,为每个线程提供最多 8 KB 的寄存器,同时保持最大占用率。为英特尔 GPU 提供寄存器数量实际上不起作用,因为英特尔 GPU 指令可以比 Nvidia 或 AMD 架构更灵活地寻址寄存器文件。每条指令都可以指定矢量宽度,并访问小到单个标量元素的寄存器。
对于大多数数学指令,Battlemage 坚持使用 16 宽或 32 宽向量,放弃了 Alchemist 可能出现的 SIMD8 模式。向量执行减少了指令控制开销,因为单个操作会应用于向量中的所有通道。但是,如果某些通道采用不同的分支方向,则会导致吞吐量损失。从理论上讲,Battlemage 更长的本机向量长度会使其更容易遭受此类发散惩罚。但 Alchemist 尴尬地在 XVE 对之间共享控制逻辑,使得 SIMD8 的行为像 SIMD16,而 SIMD16 的行为很像 SIMD64,除了一个有趣的极端情况。

相比之下,Battlemage 的发散行为直观而直接。如果 16 个线程组以相同的方式运行,则 SIMD16 可实现充分利用。这同样适用于 SIMD32 和 32 个连贯线程组。因此,Battlemage 在处理发散分支时实际上比其前身更灵活,同时享受使用更大向量的效率优势。

与 Alchemist 一样,Battlemage 通过两个端口(ALU0、ALU1)执行大多数数学运算。ALU0 处理基本的 FP32 和 FP16 运算,而 ALU1 处理整数数学和不太常见的指令。英特尔的端口布局与 Nvidia 的 Turing 相似,后者也将调度带宽分为 16 宽的 FP32 和 INT32 单元。一个关键的区别是 Turing 使用固定的 32 宽向量,并通过在交替周期中为它们提供信息来保持两个单元的占用。英特尔可以连续发出相同类型的指令,并且可以选择每个周期向不同端口发出多条指令。

Battlemage 与 Turing 的另一个相似之处是,它继承了 Alchemist 的“XMX”矩阵乘法单元。英特尔声称是三向共发射,这意味着 XMX 位于单独的端口上。但是,VTune 仅显示 ALU0+ALU1 和 ALU0+XMX 的多个管道活动指标。我在上面将 XMX 绘制为单独的端口,但 XMX 单元可能位于 ALU1 上。

游戏工作负载往往使用更多浮点运算。在计算繁重的部分,ALU1 卸载其他运算,让 ALU0 自由处理浮点运算。XeSS 执行 XMX 单元,与矢量运算一起执行的共同问题最少。生成 AI 工作负载的 XMX+矢量共同问题更少。

正如任何专用执行单元所预期的那样,XMX 软件支持远未得到保证。使用其他框架运行 AI 图像生成或语言模型会严重消耗 B580 的常规矢量单元,而 XMX 单元则处于闲置状态。
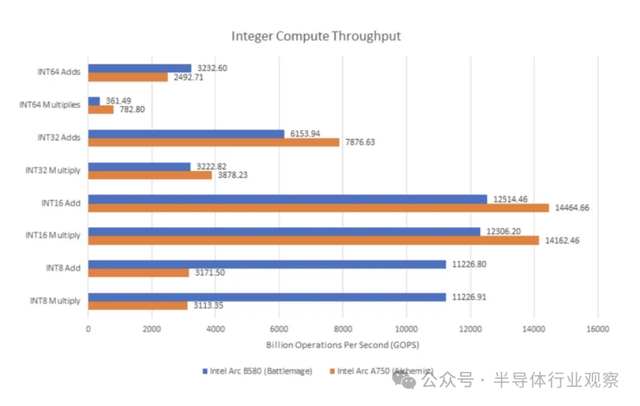
在微基准测试中,英特尔较旧的 A770 和 A750 通常可以使用其更大的着色器阵列来实现比 B580 更高的计算吞吐量。但是,B580 的表现更一致。Alchemist 在 FP32 FMA 操作方面遇到了麻烦。相比之下,Battlemage 可以毫无问题地达到其理论吞吐量。FP32+INT32 双重问题在 Battlemage 上并不完美,但在 A750 上几乎没有发生过。
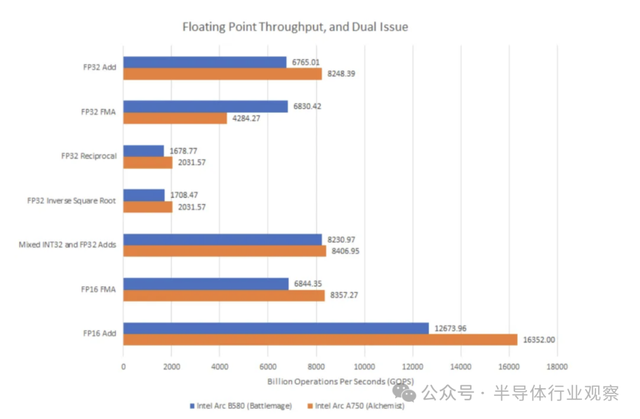
在整数方面,Battlemage 更擅长处理较低精度的 INT8 运算。使用 Meteor Lake 的 iGPU 作为代理,英特尔的上一代架构使用mov和add指令对来处理char16加法,而 Battlemage 仅用 即可完成add。
每个 XVE 还具有一个用于控制流指令的分支端口和一个允许 XVE 与外界通信的“发送”端口。这些端口上的负载通常较低,因为 GPU 程序的分支频率不如 CPU 程序高,并且通过“发送”端口访问的共享函数没有足够的吞吐量来处理所有同时访问它的 XVE。
内存访问
Battlemage 的内存子系统与 Alchemist 有很多共同之处,其起源可以追溯到过去十年来英特尔的集成图形架构。XVE 通过向相应的共享功能单元发送消息来访问内存层次结构。在某一时刻,整个 iGPU 基本上相当于一个 Xe Core,其中 XVE 等效物充当基本构建块。XVE 将通过消息传递结构访问 iGPU 的纹理单元、缓存和工作分配硬件。英特尔此后建立了更大的细分部门,但术语仍然存在。

纹理路径
每个 Xe Core 都有八个 TMU,即英特尔术语中的纹理采样器。采样器具有 32 KB 纹理缓存,并且可以向 XVE 返回 128 字节/周期。在这方面,Battlemage 与 Alchemist 没有什么不同。但 B580 的纹理带宽比其前代产品要少。其更高的时钟速度不足以弥补 Xe Core 数量少得多的缺陷。

B580 以更高的时钟速度运行,这也降低了纹理缓存命中延迟。不过,从时钟周期来看,Battlemage 的纹理缓存命中延迟与其前代产品几乎相同。L2 延迟已显著改善,因此 Battlemage 上的纹理缓存丢失并不那么糟糕。

数据访问(全局内存)
全局内存访问首先缓存在 256 KB 块中,该块兼作共享本地内存 (SLM)。它比 Alchemist 和 Lunar Lake 的 192 KB L1/SLM 块大,因此英特尔找到了晶体管预算,将更多数据保留在更靠近执行单元的位置。与 Lunar Lake 一样,即使计算内核不分配本地内存,B580 也更倾向于使用 SLM 而不是 L1 容量。
英特尔也许能够以另一种方式拆分 L1/SLM 块,但无论我是否分配本地内存,延迟测试都显示完全相同的结果。使用 Nemes 的 Vulkan 测试套件进行测试也显示 96 KB 的 L1。

Battlemage 上的全局内存访问延迟低于纹理访问,尽管 XVE 必须处理数组地址生成。对于纹理访问,TMU 会进行所有地址计算。XVE 所做的只是向它们发送消息。就时钟周期而言,L1 数据缓存延迟与 Alchemist 类似,但更高的时钟速度再次为 B580 带来了实际的延迟优势。
标量优化?
Battlemage 还通过标量内存访问减少了时钟周期延迟。英特尔没有像 AMD 那样的单独标量指令。但英特尔的 GPU ISA 允许每条指令指定其 SIMD 宽度,并且可以执行 SIMD1 指令。英特尔的编译器早在 Battlemage 之前就一直在进行标量优化并适时生成 SIMD1 指令,但据我所知,性能没有差异。现在有了。

在 B580 上,SIMD1(标量)访问的 L1 延迟比 SIMD16 访问快大约 15 个周期。在微基准测试中,SIMD32 访问需要一个额外的周期,但这是因为编译器生成了两组 SIMD16 指令来计算 32 个通道上的地址。我还让英特尔的编译器发出标量 INT32 添加,但这些添加并没有比矢量添加延迟有所改善。因此,标量延迟的改进几乎肯定来自优化的内存管道。

SIMD1 指令在 XVE 中也有帮助。英特尔不使用单独的标量寄存器文件,但可以比 AMD 或 Nvidia 更灵活地寻址其矢量寄存器文件。指令可以访问单个元素(子寄存器)并读出它们想要的任何矢量宽度。英特尔的编译器可以将许多“标量寄存器”打包成与矢量寄存器等效的寄存器,从而节省寄存器文件容量。
L1 带宽
float4使用小型阵列的负载,我能够从 B580 的 L1 中获得比 A750 更好的效率。英特尔表示 Xe-HPG 的L1 可以每周期提供 512 字节,但我无法在 Alchemist 或 Battlemage 上获得接近的带宽。微基准测试将两种架构上的每 Xe 核心带宽设定为每周期略低于 256 字节。

即使 L1 每周期只能提供 256 字节,英特尔 Xe Core 仍能获得与 AMD RDNA WGP 一样多的 L1 带宽,以及与 Nvidia Ampere SM 一样多的两倍的 L1 带宽。每周期 512 字节可以让每个 XVE 每周期完成一次 SIMD16 加载,无论如何这都有点过度了。
本地内存 (SLM)
Battlemage 对 L1 缓存和 SLM 使用相同的 256 KB 块。SLM 为线程组提供本地地址空间,并充当快速软件管理暂存器。在 OpenCL 中,这通过本地内存类型公开。每个人都喜欢用不同的名字来称呼它,但在本文中,我将使用 OpenCL 和英特尔的术语。

尽管本地内存和 L1 缓存命中都由相同的物理存储支持,但 SLM 访问的延迟更短。与缓存命中不同,SLM 访问不需要标签检查或地址转换。在 SLM 模式下访问 Battlemage 的 256 KB 内存块可将延迟降至略高于 15 纳秒。它比在 Alchemist 上执行相同操作更快,并且与 AMD 和 Nvidia 的最新 GPU 相比非常具有竞争力。

本地内存/SLM 还允许工作组内的线程同步和交换数据。从atomic_cmpxchg本地内存测试来看,B580 在线程之间传递值的速度比其前代产品要快一些。几乎所有改进都归功于更高的时钟速度,但这足以使 B580 与 AMD 和 Nvidia 的较新 GPU 保持一致。

本地内存的后备结构通常包含用于处理原子操作的专用 ALU。例如,AMD 的 RDNA 架构上的 LDS 被分成 32 个存储体,每个存储体有一个原子 ALU。英特尔几乎肯定有类似的东西,我正在用atomic_add本地内存上的操作来测试它。每个线程都针对数组中的不同地址,旨在避免争用。

Alchemist 和 Battlemage 似乎都在每个 Xe Core 的 SLM 单元上附加了 32 个原子 ALU,就像 AMD 的 RDNA 和 Nvidia 的 Pascal 一样。Meteor Lake 的 Xe-LPG 架构每个 Xe Core 的原子 ALU 数量可能只有后者的一半。
L2 缓存
Battlemage 与其前代产品和 Nvidia 当前的 GPU 一样,具有两级缓存层次结构。B580 的 18 MB L2 略大于 A770 的 16 MB L2。A770 将其 L2 分为 32 个存储体,每个存储体每个周期能够处理 64 字节访问。在 2.4 GHz 下,这相当于近 5 TB/s 的带宽。
英特尔没有透露 B580 的 L2 拓扑,但合理的假设是英特尔将存储体大小从 512 KB 增加到 768 KB,使 4 个 L2 存储体与每个内存控制器绑定。如果是这样,B580 的 L2 将有 24 个存储体和 4.3 TB/s 的理论带宽,频率为 2.85 GHz。使用 Nemes 的 Vulkan 测试进行微基准测试可以获得相当一部分带宽。旧款 A750 的效率要低得多,尽管可能拥有更多的理论 L2 带宽,但它获得的带宽大约与 B580 一样多。

除了将执行单元与慢速 VRAM 隔离开来之外,L2 还可以充当 GPU 之间的一致性点。B580 在使用全局内存在线程之间传输数据时速度非常快,并且比其前代产品更快。

通过对全局内存进行原子加法运算,Battlemage 在其尺寸的 GPU 上表现良好,并且大大超越了其前代产品。

我使用的是 INT32 操作,因此 A750 上的 86.74 GOPS 对应 351 GB/s 的 L2 带宽。在 B580 上,220.97 GOPS 需要 883.9 GB/s。然而,VTune 报告 A750 上的 L2 带宽要高得多。不知何故,A750 在测试期间看到的 L2 带宽为 1.37 TB/s,几乎是其应有带宽的 4 倍。

Meteor Lake 的 iGPU 与 Alchemist 关系密切,但其全局原子添加吞吐量与 Xe Core 数量的比率与 Battlemage 相似。VTune 报告称,Meteor Lake 的 iGPU 使用的 L2 带宽比要求的多,但只高出 2 倍。奇怪的是,它还显示了 XVE 的预期带宽。我想知道英特尔的跨 GPU 互连中是否存在某些东西无法与更大的 GPU 很好地扩展。

使用 Battlemage,原子被分成一个单独的类别,并且不作为常规 L2 带宽报告。VTune 表示原子通过加载/存储单元传递到 L2,没有任何膨胀。此外,L2 的繁忙度仅为 79.6%,这表明该层还有一点余地。

这可能只是性能监控方面的改进,但性能计数器通常与底层架构紧密相关。我怀疑英特尔对处理全局内存原子的方式进行了重大更改,让性能在更大的 GPU 上得到更好的扩展。我注意到较新的游戏有时会使用全局原子操作。也许英特尔也注意到了这一点,并决定是时候对其进行优化了。
VRAM 访问
B580 具有 192 位 GDDR6 VRAM 子系统,可能配置为六个 2×16 位内存控制器。OpenCL 的延迟比上一代更高。

我怀疑这只适用于 OpenCL,因为 Vulkan 的延迟(使用 Nemes 的测试)显示延迟略高于 300 纳秒。大测试规模下的延迟可能会遇到 TLB 未命中,我怀疑英特尔对不同的 API 使用不同的页面大小。
与同类产品相比,Arc B580 的理论 VRAM 带宽更高,为 456 GB/s,但 L2 容量也较小。例如,Nvidia 的 RTX 4060使用 128 位 GDDR6 总线以 17 GT/s 的速度运行,VRAM 带宽为 272 GB/s,前面有 24 MB 的 L2。我用 VTune 分析了一些内容,并找出了 VRAM 带宽使用率的峰值。我还检查了同一采样间隔内报告的 L2 带宽。

至少在我检查的几个例子中,英特尔在缓存容量和内存带宽之间的平衡似乎效果很好。即使在 VRAM 带宽需求很高的情况下,18 MB L2 也能够捕获足够的流量以避免超出 GDDR6 带宽限制。如果英特尔假设使用较小的 GDDR6 内存子系统(如 Nvidia 的 RTX 4060),B580 将需要更大的缓存以避免达到 VRAM 带宽限制。
PCIe 链路
可能为了降低成本,B580 的 PCIe 链路比其前代产品更窄。不过,x8 Gen 4 链路提供的理论带宽与 x16 Gen 3 链路一样多。使用 OpenCL 进行测试无法接近理论带宽,但与 A750 相比,B580 处于劣势。

只要有足够的 VRAM, PCIe 链路带宽通常对游戏性能的影响很小。与其直接竞争对手相比,B580 拥有相对较大的 12 GB VRAM 池,后者也拥有 PCIe 4.0 x8 链路。这可能会让 B580 在中端市场中占据优势,但这并不意味着它不会出现问题。

例如,DCS 将使用超过 12 GB 的 VRAM 和 mod。观察不同区域的不同飞机通常会导致 B580 出现卡顿。VTune 显示高 PCIe 流量,因为 GPU 必须频繁从主机内存读取。
最后的话
Battlemage 保留了 Alchemist 的高级目标和基础,但做了大量改进。计算更易于使用,缓存延迟得到改善,全局内存原子的奇怪扩展问题也得到了解决。英特尔还进行了一些令人惊讶的优化,例如降低标量内存访问延迟。结果令人印象深刻,尽管 Arc B580 在几乎所有纸面规格上都落后,但其表现仍轻松超越了即将离任的 A770。
英特尔的 GPU 架构的一些变化使其更接近 AMD 和 Nvidia 的设计。英特尔的编译器通常更喜欢 SIMD32,这是 AMD 经常为计算代码或顶点着色器选择的模式,也是 Nvidia 独家使用的模式。SIMD1 优化与 AMD 的标量单元或 Nvidia 的统一数据路径相似。Battlemage 的内存子系统比其前代产品更强调缓存,同时更少地依赖高 VRAM 带宽。AMD 的 RDNA 2 和 Nvidia 的 Ada Lovelace 在其内存子系统方面也采取了类似的举措。
当然,Battlemage 与其独立 GPU 竞争对手相比仍然有很大不同。即使使用更大的 XVE,Battlemage 使用的执行单元分区仍然比 AMD 或 Nvidia 要小。借助 SIMD16 支持,英特尔继续支持比竞争对手更短的矢量宽度。生成 SIMD1 指令为英特尔提供了一定程度的标量优化,但无法像 AMD 或后 Turing Nvidia 那样拥有完整的标量/统一数据路径。而且 18 MB 的缓存仍然小于 Nvidia 和 AMD 中端显卡的 24 或 32 MB。
除了与 AMD 和 Nvidia 的不同之外,Battlemage 是英特尔进军中端显卡市场的必经之路。独立 GPU 市场上出现第三个竞争对手对任何 PC 爱好者来说都是好消息。当然,英特尔还有一段路要走。驱动程序开销和对可调整大小的 BAR 的依赖就是英特尔仍在努力摆脱仅使用 iGPU 的背景的几个例子。
但我希望英特尔在站稳脚跟后能进军高端 GPU 市场。高端 dGPU 市场将迎来第三家参与者,因为许多人仍然使用 Pascal 或 GCN,因为他们觉得还没有合理的升级。英特尔的 Arc B580 至少在缺货时解决了部分被压抑的需求。我期待看到英特尔未来的 GPU 努力。
参考链接
https://chipsandcheese.com/p/intels-battlemage-architecture
END
👇半导体精品公众号推荐👇
▲点击上方名片即可关注
专注半导体领域更多原创内容
▲点击上方名片即可关注
关注全球半导体产业动向与趋势
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。

今天是《半导体行业观察》为您分享的第4034期内容,欢迎关注。

『半导体第一垂直媒体』
实时 专业 原创 深度
公众号ID:icbank
