LLM可以处理长达100,000个token的输入,但在生成超过2,000词的适度长度输出时仍然面临困难,因为模型的有效生成长度本质上受到其在监督微调(SFT)过程中所见样本的限制。
为解决这个问题,本文的作者引入了AgentWrite,这是一个基于代理的流程,它将超长生成任务分解为子任务,使现成的LLM能够生成超过20,000词的连贯输出。

主要贡献如下:
介绍了限制当前(长上下文)LLM输出长度的主要因素,即SFT数据中对输出长度的约束。
提出AgentWrite,使用分而治之的方法和现成的LLM自动构建具有超长输出的SFT数据。并且使用这种方法,构建了LongWriter-6k数据集。
将LongWriter-6k数据集进行SFT训练,成功地将现有模型的输出窗口大小扩展到10,000+词,同时不影响输出质量。
成长度限制的原因论文先构建LongWrite-Ruler评估(创建8个不同的指令,中英文各4个,并在指令中改变输出长度要求"L")来探测LLM的生成长度限制。然后,通过改变模型SFT阶段数据的最大输出长度,发现训练模型在LongWrite-Ruler测试中的最大输出长度与SFT数据的最大输出长度显示出显著的正相关。
如下图所示,LongWrite-Ruler测试表明所有测试模型的最大输出长度限制约为2k词。

对照实验
在这三个训练集上训练GLM-4-9B模型,并测量结果模型在LongWriter-Ruler上的最大输出长度。下图显示了在不同最大输出长度的SFT数据集上训练的GLM-4-9B的LongWriter-Ruler测试。

上图表明,模型的最大输出长度与SFT数据中的最大输出长度成正比增加,分别达到约600、900和1,800词。
AgentWrite: 自动数据构建AgentWrite是一个分而治之风格的代理,流程如下图所示。

AgentWrite首先将长写作任务分解为多个子任务,每个子任务要求模型只写一段。然后模型依次执行这些子任务,我们将子任务输出连接起来以获得最终的长输出。
更详细的描述概述如下步骤:
i) 步骤1: 规划使用LLM根据写作指令生成写作大纲,其中包括每段的主要内容和字数要求。使用的提示如下:

串行调用LLM完成每个子任务,逐节生成写作内容。为确保输出的连贯性,在调用模型生成第n节时,还输入之前生成的n-1节,允许模型基于现有的写作历史继续写下一节。
使用的提示如下:

在两个长篇写作数据集上测试了所提出的AgentWrite方法的生成长度和质量
a) LongWrite-Ruler:
用于精确测量该方法可以提供多长的输出。
b) LongBench-Write
通过收集120个不同的用户写作提示构建了这个数据集,其中60个是中文,60个是英文。为评估模型的输出长度是否满足用户要求,作者确保所有这些指令都包含明确的字数要求,组织成四个子集:0-500词、500-2,000词、2,000-4,000词和4,000词以上。
该数据集的关键统计数据如下:

采用两个指标进行评估:一个用于评分输出长度,另一个用于评分输出质量。模型的输出长度应尽可能接近指令中规定的要求。因此,我们使用分段线性函数计算输出长度得分Sl(其中l是要求的长度,l'是实际输出长度):
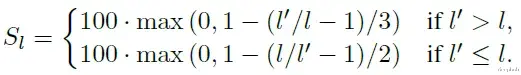
验证结果
下图显示了LongWrite-Ruler上的输出长度测量结果

观察到AgentWrite成功将GPT-4o的输出长度从最大2k词扩展到约20k词。考虑到GPT-4o在评估AgentWrite性能时可以成功完成输出长度不超过2,000词的任务,所以仅在要求输出长度为2,000词或更多的指令上应用AgentWrite。此外还评估了AgentWrite的一个变体,表示为"+Parallel",它在步骤2中并行调用模型为每个段落生成输出。
下表概述了LongBench-Write上AgentWrite策略的评估:

在整合AgentWrite后,GPT-4o可以生成长达20k词的内容。这显著提高了GPT-4o的长度跟随得分(Sl),特别是在[4k, 20k)词的输出长度范围内。检查质量得分(Sq),可以看到AgentWrite在扩展长度的同时不会影响输出质量。通过比较六个维度的质量得分,发现AgentWrite显著提高了广度和深度得分(+5%),同时略微降低了连贯性和清晰度得分(-2%)。虽然+Parallel略微提高了模型的输出长度得分,但它损害了AgentWrite的输出质量,特别是在连贯性方面(-6%)。这表明在AgentWrite的步骤II中为模型提供先前生成的上下文是必要的。
LongWriter: 教会模型生成更长的输出i) 数据构建从GLM-4的SFT数据[2]中选择了3,000条指令,主要是中文。从WildChat-1M3中选择了3,000条指令,主要是英文。并使用GPT-4o进行自动选择过程。手动检查自动选择的指令,并验证超过95%的指令确实需要几千词的回应。
对于这6,000条指令,使用带有GPT-4o的AgentWrite流程来获得回应。进一步对获得的数据进行后处理,包括过滤掉太短的输出和因AgentWrite步骤I中获得的规划步骤过多而导致模型输出崩溃的情况,其中包括0.2%的数据被过滤掉。
清理模型可能在每个输出部分开头添加的无关标识符,如"段落1"、"段落2"等。我们将最终获得的长输出数据集称为"longwriter-6k"。为确保模型的通用能力,将longwriter-6k与通用SFT数据结合,形成整个训练集。
ii) 模型训练a) 监督微调
基于两个最新的开源模型进行训练,即GLM-4-9B和Llama-3.1-8B。对这两个模型的训练结果是两个模型:LongWriter-9B(GLM-4-9B-LongWriter的缩写)和LongWriter-8B(Llama-3.1-8B-LongWriter的缩写)。
b) 对齐(DPO)
对监督微调的LongWriter-9B模型进行直接偏好优化。DPO数据来自GLM-4的聊天DPO数据(约50k条)。还专门针对长篇写作指令构建了4k对数据。
对于每个写作指令,从LongWriter-9B中抽样4个输出,并按照[4]中的方法对这些输出进行评分。然后我们选择得分最高的输出作为正样本,并从剩余的三个输出中随机选择一个作为负样本。结果模型LongWriter-9B-DPO在上述数据混合上训练了250步。
实验结果下表概述了在LongBench-Write上的评估结果。由于使用GPT4-o来判断输出质量Sq,在判断自身时可能带来不公平。

i) 大多数之前的模型无法满足超过2,000词的长度要求,而LongWriter模型能够持续为此类提示提供更长、更丰富的回应。
之前的模型在[2k, 4k)范围的提示上普遍表现不佳(得分低于70),只有Claude 3.5 Sonnet达到了不错的分数。
对于[4k, 20k)范围的提示,几乎所有之前的模型都完全无法达到目标输出长度,甚至得分为0(意味着所有输出长度都小于要求长度的1/3)。
通过添加来自LongWriter-6k的训练数据,作者训练的模型可以有效地达到要求的输出长度,同时保持良好的质量,这从[2k, 20k)范围的Sl和Sq以及下图的散点图中可以看出。

在测试中,作者使用了两个现有的支持128k上下文窗口的长上下文模型:GLM-4-9B和Llama-3.1-8B。下图报告了它们在三个LongWriter模型生成的约100个长于8,192个token的文本样本的不同位置上的累积平均NLL损失。较低的NLL值表示更好的预测。

两个模型在后期位置的预测显著改善,表明LongWriter模型输出中存在长程依赖。
ii) DPO有效提高了模型的输出质量和在长生成中遵循长度要求的能力
通过比较LongWriter-9B和LongWriter-9B-DPO的得分,作者发现DPO显著提高了Sl(+4%)和Sq(+3%)得分,并且改进在所有范围内都是一致的。
作者手动注释了GPT-4o和三个longwriter模型在LongBench-Write中输出的成对胜负,并在下图中可视化了结果。

iii) LongWriter模型的输出长度限制扩展到10k到20k词之间,而需要更多具有长输出的数据来支持更长的输出
下图显示了LongWriter模型的LongWrite-Ruler测试结果,显示它们的最大生成长度在10k-20k词之间。

这篇论文确定了当前LLM的2,000词生成限制,并提出通过在对齐过程中添加长输出数据来增加它们的输出窗口大小。为自动构建长输出数据,开发了AgentWrite,这是一个基于代理的流程,使用现成的LLM创建扩展的、连贯的输出。
使用论文构建的LongWriter-6k成功地将当前LLM的输出窗口大小扩展到10,000+词。
论文: https://arxiv.org/abs/2408.07055
代码: https://github.com/THUDM/LongWriter
