推理 LLM 是当今 AI 研究中的热门话题。我们从 GPT-1 开始,一直到像 Grok-3 这样的高级推理器。这段旅程非常了不起,一路上发现了一些非常重要的推理方法。其中之一是思维链 (CoT) 提示(Few-shot 和 Zero-shot),导致了我们今天看到的大部分 LLM 推理革命。
令人兴奋的是,Zoom Communications 的研究人员现在发布了一种更好的技术。

这种技术称为 Chain-of-Draft (CoD) Prompting,在准确性上优于 CoT Prompting,在回答查询时仅使用所有推理Token的 7.6%。

使用直接答案 (Standard)、思维链 (CoT) 和草稿链 (CoD) 提示 Claude 3.5 Sonnet时的准确性和标记使用比较,以解决不同推理领域的任务
这对于推理目前非常冗长、需要大量计算时间且具有高延迟的 LLM 来说是一个巨大的胜利,这是许多实际时间关键型应用程序中的瓶颈。
接下来,我们深入探讨了草稿链 (CoD) 提示的工作原理,以及如何使用它来使您的 LLM 比以往任何时候都更加准确和Token效率。
提示研究员如何发现大模型的新方法的?首先,让我们谈谈提示研究人员不断在 LLM 中发现新的方法。
Transformers 将我们带到了生成式预训练 Transformers 或 GPT,我们很快发现将其扩展到 GPT-2(15 亿个参数)使其充当无监督的多任务学习器(在没有监督学习/微调任务特定数据集的情况下执行多项任务)。
随着进一步扩展到 GPT-3(1750 亿个参数),发现该模型可以快速适应并在新任务上表现良好,只需在输入提示中提供几个示例(Few-shot Prompting)。
然后发现,将解决问题分解为中间推理步骤并促使大型语言模型 (LLM) 生成这些步骤,可以在算术、常识和符号推理任务中实现最先进的性能。
这种方法称为思维链 (CoT) 提示。

标准和思维链提示的示例(图片来自 ArXiv 研究论文,标题为“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”)
在 CoT 之后,很快发现 LLM 是zero-shot推理器。
与原始的 CoT 提示方法一样,他们不需要使用小样本推理示例来提示他们以获得更好的性能。
只需在提示中添加短语“Let's think step by step”就可以让他们在解决问题时逐步推理。
这种方法称为 Zero-shot Chain of Thought Prompting。

标准 Zero-shot 和 Few-shot 提示、原始 CoT 提示(显示为“(b) Few-shot-CoT”)和 Zero-shot CoT 提示之间的比较(图片来自题为‘Large Language Models are Zero-Shot Reasoners’)
研究人员随后意识到,链式推理和对答案的贪婪解码是不够的。
复杂的推理任务可能有多个推理路径可以得出正确的答案,如果多条路径导致相同的答案,我们可以确信最终答案是正确的。
这导致了一种称为 Self-Consistency 的新解码策略,该策略对模型进行采样以生成多个推理路径,并从中选择最一致的答案。

CoT 提示中的贪心解码与自洽性(图片来自 ArXiv 研究论文,标题为“Self-Consistency Improves Chain of Thought Reasoning in Language Models”)
各种思维架构的提出遵循这种在解决问题时考虑多种推理路径的方法,引入了 Tree-of-Thoughts (ToT) 框架,它使用树状思维过程探索解决方案空间。

Tree-of-Thought 框架(图片来自 ArXiv 研究论文,标题为“Large Language Model Guided Tree-of-Thought”)
它使用称为 “Thoughts” 的语言序列作为解决问题的中间步骤。这些是在需要时使用具有 lookahead 和 backtracking 的搜索算法进行评估和探索的。

各种推理方法的比较(图片来自 ArXiv 研究论文,标题为“‘Tree of Thoughts: Deliberate Problem Solving with Large Language Models’”)
Tree 架构被 Graph 取代,从而产生了 Graph-of-Thoughts 框架,可以更好地对解决方案空间进行建模。

CoD与其他推理方法的比较(图片来自 ArXiv 研究论文,标题为“Graph of Thoughts: Solving Elaborate Problems with Large Language Models”)
但这还不是全部!
提示并不是帮助 LLM 更好地推理的唯一方法,还有很多其他技术,在下面这篇论文中还有很多新方法的提出。
 但是延迟呢?
但是延迟呢?探索推理空间是一项计算成本高昂的任务,会增加响应延迟。
引入了一种称为 Skeleton-of-Thought (SoT) 的减少延迟的解决方法,它首先指导 LLM 生成答案的框架/大纲。
然后,它进行并行 API 调用/批量解码,以并行完成每个骨架点的内容。
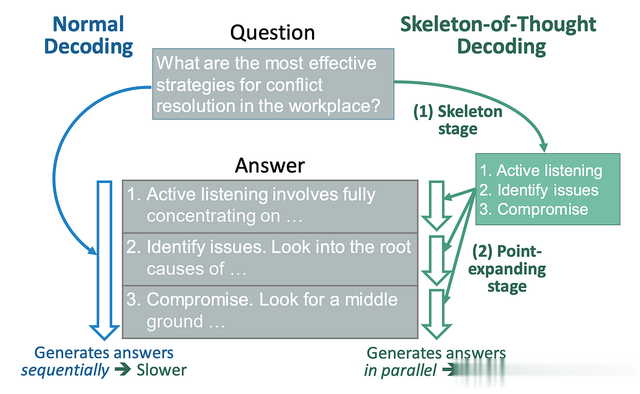
Skeleton-of-Thought (SoT) 与标准解码的比较概述(图片来自题为“Skeleton-of-Thought:Prompting LLMs for Efficient Parallel Generation”的 ArXiv 研究论文)
推理模型还可能过度思考简单的问题,生成不必要的推理Token,从而导致查询到响应时间过长。

在问题 “2 加 3 的答案是什么?(图片来自 ArXiv 研究论文,标题为“Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs’
QwQ-32-B-Preview 模型如何解决这个加 2 和 3 的简单问题,这不是很疯狂吗?

QwQ-32-B-Preview 对一个简单的算术问题过度思考(图片来自 ArXiv 研究论文,标题为“不要为 2+3=想那么多?关于类似 o1 的 LLM 的过度思考')
研究人员试图通过限制推理token预算来解决这个问题,但 LLM 通常无法遵守这一点。
在回答问题之前,还使用了额外的 LLM 根据问题的复杂性动态估计不同问题的代币预算,但这进一步增加了响应延迟。

带有估计和提示的代币预算感知 LLM 推理 (TALE) 概述(图片来自题为“‘Token-Budget-Aware LLM Reasoning”的 ArXiv 研究论文)
我们能否将所有这些见解结合起来,并以某种方式简化它们以达到单一的方法?
草稿链“Chain-of-Draft” 提示的灵感回到基础,思维链 (CoT) 是一种非常了不起的提示方法,可以更好地进行 LLM 推理。
然而,它是冗长的,LLM 在得出答案之前会产生数千个推理Token。
这与人类的思考和推理方式大不相同。
我们通常不会用冗长的语言进行推理,而是在思考时记下最重要的中间点(草稿)。
这就是 Chain-of-Draft (CoD) Prompting 的灵感来源。
它只是要求模型逐步思考,并将每个推理步骤限制为最多五个单词。
为了确保模型理解这一点,研究人员手动编写了这种 Chain-of-Drafts 的 Few-shot 示例,并在提示中给出。
令人惊讶的是,这样的限制并没有以任何方式强制执行,模型只是作为一般准则来提示。
这与标准的 few-shot prompting 形成鲜明对比,后者在提示中给出查询-响应对,并要求模型直接返回最终答案,而无需任何推理或解释。
这也不同于 Chain-of-Thought 提示,后者在提示的查询-响应对中给出了中间推理步骤,并要求模型回答问题。
在下图中,可以更好地理解这些方法之间的差异,其中要求 LLM 解决一个简单的算术问题。


 CoD 提示的效果如何?
CoD 提示的效果如何?为了评估 CoD 提示,GPT-4o 和 Claude 3.5 Sonnet 使用上述三种方法进行提示。
下图显示了每种提示方法为这些模型提供的系统提示。
 标准、CoT 和 CoD 提示效果对比
标准、CoT 和 CoD 提示效果对比CoD 在算术推理 GSM8K 数据集上实现了 91% 的准确率,同时使用的Token比 CoT 少 80%,减少了延迟而没有任何重大的准确率损失(CoD 为 91.1%,而 GPT-4o 为 CoT 为 95.4%)。

不同提示技术的 GSM8K 评估结果
在对日期和体育理解的BIG-Bench任务进行常识推理测试后,CoD显著减少了延迟和Token的使用量,同时与CoT具有相同/更高的准确性。

日期理解 BIG-Bench任务的评估结果
请注意,当与 Claude 3.5 Sonnet 一起用于体育理解任务时,CoD 表现非常令人印象深刻,直接将 CoT 提示的平均输出token从 189.4 降低到 14.3(减少 92.4%)!

体育理解 BIG Bench任务的评估结果
最后,当对抛硬币的符号推理任务(预测一系列抛硬币后的最终硬币状态)进行评估时,CoD 会产生 100% 的准确率,并且Token比其他方法少得多。

研究人员创建的 Coin-flipping 数据集中的问题示例

在研究人员创建的包含 250 个测试用例的定制数据集上进行硬币翻转评估
这些成绩绝对是惊人的!
CoD 提示以最小的延迟实现惊人的高准确性,从而减少响应时间并有利于时间/计算关键型应用程序。
此类 CoD 数据还可用于训练 LLM 更好地推理(基于 DeepSeek-R1 强化学习训练方法),使其更快、更便宜、更高效、更具可扩展性。
