 1. 定义
1. 定义QLoRA 是一种 参数高效微调方法,结合了 量化(Quantization) 和 低秩适配(LoRA) 的技术,旨在通过 降低模型精度 和 仅训练少量可学习参数 的方式,显著减少大型语言模型(LLM)微调所需的内存和计算资源。其核心目标是让 超大规模模型(如65B参数) 能够在单个GPU上完成微调。
2. 关键术语解释术语
解释
NF4(NormalFloat 4-bit)
针对正态分布权重设计的4位量化格式,优化存储和计算效率。
LoRA(Low-Rank Adaptation)
通过低秩矩阵修改模型参数,仅需训练少量适配器参数(如键/值矩阵)。
Block-wise Quantization
将权重张量分块量化,每块独立计算缩放因子,避免单个异常值影响整体精度。
Paged Optimizer
优化器内存管理技术,分页存储梯度以减少显存占用。
二、背景与动机1. 传统微调的局限性内存瓶颈:全精度微调超大模型(如65B LLaMA)需 780GB+ 显存,远超单GPU容量。计算成本高:全参数更新导致训练时间长、资源消耗大。资源受限场景:个人开发者或中小团队难以承担高昂的算力成本。2. QLoRA的优势内存效率:通过 4位量化,模型显存占用可减少 90%以上(如65B模型仅需 <48GB)。参数效率:仅需训练 0.1%-1% 的额外参数(如LoRA秩为64时,65B模型新增约 2.5M参数)。性能保持:在多项任务中,QLoRA的性能接近全精度微调(如Guanaco模型达 99.3% 的性能)。三、核心原理与技术1. 技术框架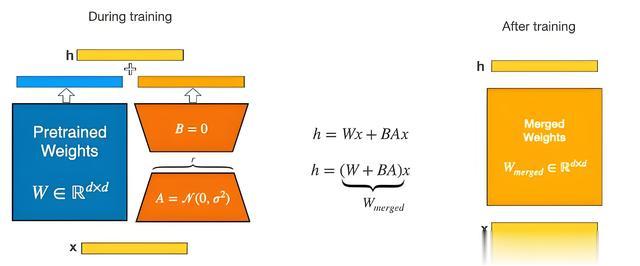
QLoRA的核心思想是:
量化预训练模型:将模型权重从FP32/FP16压缩为4位NF4格式。插入LoRA适配器:仅训练少量低秩矩阵,冻结主模型参数。优化器管理:使用Paged Optimizer分页存储梯度,避免内存尖峰。2. 关键技术详解(1) NF4量化原理:针对正态分布权重设计,通过 Block-wise分块量化(如每块1024个元素)独立计算缩放因子。优势:相比传统Int8,NF4在精度和显存之间取得更好平衡。公式示例:Int4 = round(127 * (FP32) / c) # c为每块的缩放因子(2) LoRA结构适配器设计:在Transformer的 自注意力层 和 前馈网络 中插入低秩矩阵。参数形式:A = W + ΔW = W + B * A * C其中,B, A, C 是低秩矩阵(如秩r=64),仅需训练这些矩阵的参数。
(3) Paged Optimizer作用:将优化器状态(如梯度)分页存储于CPU内存,仅在需要时加载到GPU,避免显存溢出。适用场景:处理超大规模模型时,显存不足时的救星。四、QLoRA微调详细流程 1. 实现步骤步骤1:安装依赖pip install transformers accelerate bitsandbytes datasets步骤2:加载量化模型from transformers import AutoTokenizer, AutoModelForCausalLMimport bitsandbytes as bnbmodel_name = "facebook/llama-65b"tokenizer = AutoTokenizer.from_pretrained(model_name)# 以4位NF4量化加载模型model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, # 启用4位量化 bnb_4bit_use_double_quant=True, # 双重量化优化 bnb_4bit_quant_type="nf4", # 使用NF4格式 device_map="auto" # 自动分配到GPU/CPU)步骤3:插入LoRA适配器from peft import get_peft_config, get_peft_model, LoraConfig, TaskType# 配置LoRA参数peft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, # 训练模式 r=64, # 低秩秩值(如64) lora_alpha=16, lora_dropout=0.1, target_modules=["query_key_value"] # 适配器插入的层)# 将LoRA适配器绑定到模型model = get_peft_model(model, peft_config)print(model.print_trainable_parameters()) # 输出可训练参数量步骤4:数据准备与训练from datasets import load_datasetfrom transformers import TrainingArguments, Trainer# 加载数据集(如指令遵循数据)dataset = load_dataset("your_dataset_name")train_dataset = dataset["train"]# 预处理函数def preprocess(examples): inputs = tokenizer(examples["text"], truncation=True, max_length=512) return inputstrain_dataset = train_dataset.map(preprocess, batched=True)# 训练配置training_args = TrainingArguments( output_dir="./qlora_model", per_device_train_batch_size=2, # 根据显存调整 gradient_accumulation_steps=8, # 梯度累积 learning_rate=1e-4, num_train_epochs=3, fp16=True # 使用混合精度)# 启动训练trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset)trainer.train()步骤5:保存与推理# 保存QLoRA适配器model.save_pretrained("./qlora_model")# 加载推理模型from peft import PeftModelmodel = PeftModel.from_pretrained(model, "./qlora_model")model.eval()五、实际案例:Guanaco模型微调1. 案例背景任务:指令遵循(Instruction Following),基于LLaMA-65B微调。方法:使用QLoRA在单个 A100 40GB GPU 上完成训练。2. 实验结果
1. 实现步骤步骤1:安装依赖pip install transformers accelerate bitsandbytes datasets步骤2:加载量化模型from transformers import AutoTokenizer, AutoModelForCausalLMimport bitsandbytes as bnbmodel_name = "facebook/llama-65b"tokenizer = AutoTokenizer.from_pretrained(model_name)# 以4位NF4量化加载模型model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, # 启用4位量化 bnb_4bit_use_double_quant=True, # 双重量化优化 bnb_4bit_quant_type="nf4", # 使用NF4格式 device_map="auto" # 自动分配到GPU/CPU)步骤3:插入LoRA适配器from peft import get_peft_config, get_peft_model, LoraConfig, TaskType# 配置LoRA参数peft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, # 训练模式 r=64, # 低秩秩值(如64) lora_alpha=16, lora_dropout=0.1, target_modules=["query_key_value"] # 适配器插入的层)# 将LoRA适配器绑定到模型model = get_peft_model(model, peft_config)print(model.print_trainable_parameters()) # 输出可训练参数量步骤4:数据准备与训练from datasets import load_datasetfrom transformers import TrainingArguments, Trainer# 加载数据集(如指令遵循数据)dataset = load_dataset("your_dataset_name")train_dataset = dataset["train"]# 预处理函数def preprocess(examples): inputs = tokenizer(examples["text"], truncation=True, max_length=512) return inputstrain_dataset = train_dataset.map(preprocess, batched=True)# 训练配置training_args = TrainingArguments( output_dir="./qlora_model", per_device_train_batch_size=2, # 根据显存调整 gradient_accumulation_steps=8, # 梯度累积 learning_rate=1e-4, num_train_epochs=3, fp16=True # 使用混合精度)# 启动训练trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset)trainer.train()步骤5:保存与推理# 保存QLoRA适配器model.save_pretrained("./qlora_model")# 加载推理模型from peft import PeftModelmodel = PeftModel.from_pretrained(model, "./qlora_model")model.eval()五、实际案例:Guanaco模型微调1. 案例背景任务:指令遵循(Instruction Following),基于LLaMA-65B微调。方法:使用QLoRA在单个 A100 40GB GPU 上完成训练。2. 实验结果方法
显存占用
训练时间(小时)
性能(与FP16全微调对比)
全精度微调
780GB
24小时
100%
QLoRA
40GB
24小时
99.3%
LoRA(FP16)
120GB
30小时
98.7%
3. 完整代码示例# 使用Hugging Face和bitsandbytes的完整QLoRA流程from transformers import AutoTokenizer, AutoModelForCausalLMfrom peft import LoraConfig, get_peft_model, TaskTypeimport torchimport bitsandbytes as bnb# 加载模型model_name = "facebook/llama-65b"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", device_map={"":0} # 指定GPU ID)# 配置LoRApeft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, r=64, lora_alpha=16, lora_dropout=0.1, target_modules=["query_key_value"], inference_mode=False)model = get_peft_model(model, peft_config)# 数据加载与训练(假设数据集已存在)from datasets import load_datasetdataset = load_dataset("your_dataset")train_dataset = dataset["train"]def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=512)train_dataset = train_dataset.map(tokenize_function, batched=True)# 训练配置from transformers import TrainingArguments, Trainertraining_args = TrainingArguments( output_dir="./results", per_device_train_batch_size=1, gradient_accumulation_steps=4, learning_rate=2e-4, num_train_epochs=3, fp16=True, logging_steps=1)trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset)trainer.train()六、资源与扩展阅读1. 官方工具库Bitsandbytes(量化库):链接:https://github.com/TimDettmers/bitsandbytes
功能:支持4位NF4量化和Paged Optimizer。
PEFT(Parameter-Efficient Fine-Tuning):链接:https://github.com/huggingface/peft
功能:提供LoRA、QLoRA等参数高效微调的统一接口。
2. 核心论文QLoRA论文:“QLoRA: Efficient Finetuning of Quantized LLMs”(2023)
链接:https://arxiv.org/abs/2305.14314
NF4量化技术:“Block-Wise Quantization for Deep Learning”(相关技术背景)
链接:https://arxiv.org/abs/2102.02689
3. 成功案例模型Guanaco模型:链接:https://huggingface.co/decapoda-research/llama-65b-guanaco
描述:基于QLoRA微调的65B LLaMA模型,在多项指令任务中超越ChatGPT。
七、注意事项与优化建议硬件要求:至少需要 32GB+ GPU显存(如A100 40GB),建议使用 bitsandbytes 的Paged Optimizer。
超参数调优:秩值(r):建议从 64~128 开始,平衡性能与参数量。
学习率:通常设为 1e-4~3e-4,避免过大导致梯度爆炸。
数据质量:使用 高质量指令数据(如Alpaca、ShareGPT数据集),避免噪声干扰。
多GPU扩展:使用 DeepSpeed 或 FSDP 分布式训练,进一步加速训练。
八、总结QLoRA通过 量化+低秩适配 的创新结合,解决了超大规模模型微调的显存和资源瓶颈,使单卡训练成为可能。其核心优势包括:
内存效率:65B模型仅需 <40GB 显存。性能接近全精度:在指令任务中达到 99%+ 的性能。灵活性:支持快速适配多任务(如对话、代码生成)。