我是【桃大喵学习记】,欢迎大家关注哟~,每天为你分享职场办公软件使用技巧干货!
——首发于微信号:桃大喵学习记
今天跟大家介绍的是WPS中的一个新神器——REGEXP函数。它就像一个文本侦探,能基于正则表达式,对复杂的文本信息进行匹配提取和替换。今天就跟大家分享REGEXP函数常用的几个场景,公式可以直接套用,谁用谁知道,好用到爆!
REGEXP函数介绍
功能:基于正则表达式,对复杂文本进行匹配、提取和替换。
语法:=REGEXP(原始字符串,正则表达式,[匹配模式],[替换内容])
第1参数:【原始字符串】,必填项,就是要用正则表达式匹配的文本;
第2参数:【正则表达式】,必填项,要匹配文本的正则表达式(字符串);
第3参数:【匹配模式】,可选项,0或忽略表示提取,1表示判断是否包含,2表示替换;
第4参数:【替换内容】,可选项,仅在匹配模式为2时有效,用来替换匹配的内容。
场景一:从无规律的文本数据中提取数字
①提取所有数字
公式:=REGEXP(A2,"[0-9.]+")
②提取第一串数字
公式:=REGEXP(A2,{"[0-9.]+"})

解读:
“[0-9.]+”表数字及含小数点的数字。并且REGEXP函数有个特点,就是当第二参数使用常量数组时,它只给出了每种情况的第一个值。所谓常量数组就是用大括号括起来,这样就可以获取第一个数字了。
场景二:从无规律的文本数据中提取字母
①提取所有字母
公式:=REGEXP(A2,"[A-z]+")
②提取第一串字母
公式:=REGEXP(A2,{"[A-z]+"})

解读:
“[A-z]+“表示所有英文字符。同样用大括号括起来可以获取第一个字母。
场景三:从无规律的文本数据中提取汉字
①提取所有汉字
公式:=REGEXP(A2,"[一-龟]+")
②提取第一串汉字
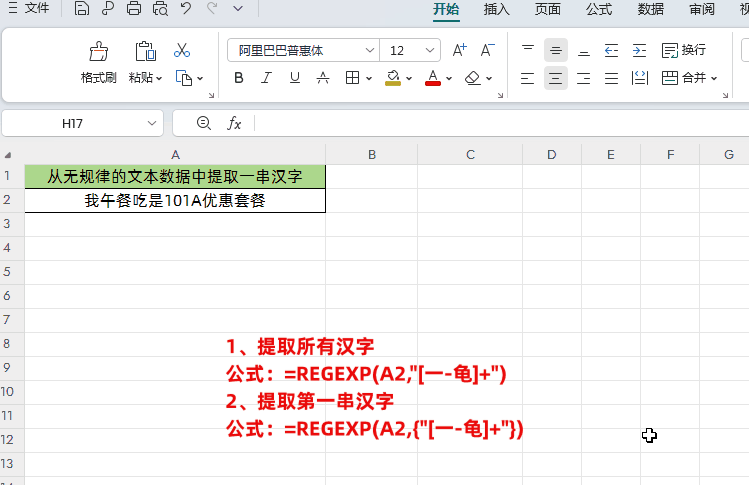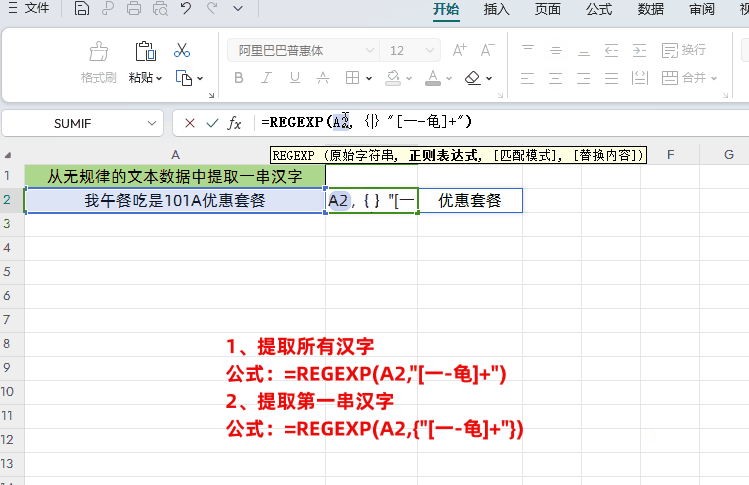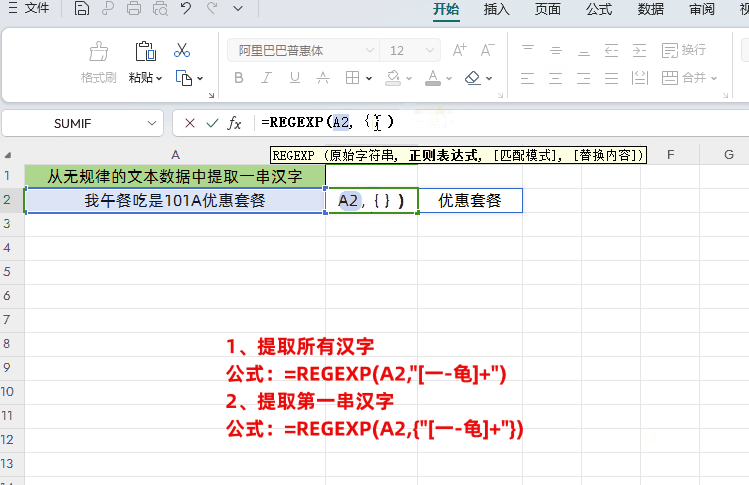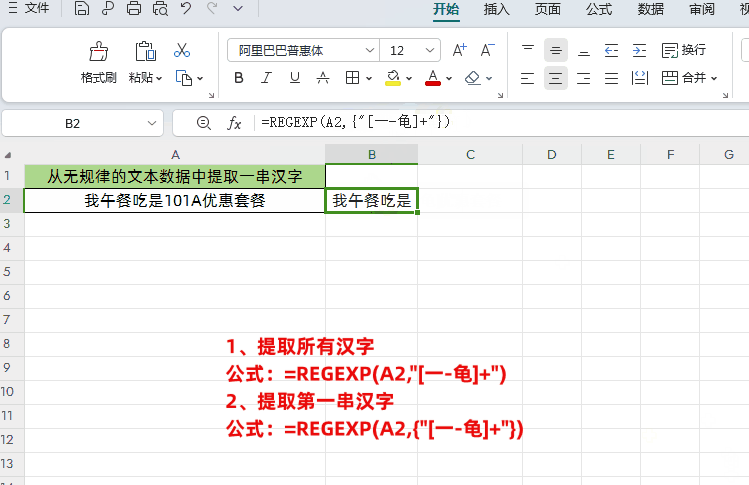
公式:=REGEXP(A2,{"[一-龟]+"})
解读:
“[一-龟]+“表示所有中文字符。同样用大括号括起来可以获取第一个汉字。
场景四:按分隔符号拆分内容
①按分隔符横杆"-"拆分数据
公式:=REGEXP(A1,"[^-]+")

解读:
公式中正则表达式中的^代表非,^-代表不是横杆的内容,[^-]+不是横杆的连续内容。
②按换行符拆分数据
公式:=REGEXP(A1,"[^\n]+")

解读:
公式中正则表达式中的\n代表换行符,^\n代表不是换行符的内容,[^-]+不是换行符的连续内容。
③按多个分隔符拆分数据
公式:=REGEXP(A1,"[^-/]+")

解读:
公式中正则表达式中的^代表非,^-/代表不是横杆“-”和不是斜杠“/”的内容,[^-/]+不是横杆和斜杠的连续内容。
场景五:结合其它函数
①对拆分后的数值进行求和
公式:=SUM(--REGEXP(A2,"[0-9.]+"))

解读:
用REGEXP函数提取后的数字其实是文本格式,然后再用双减号“--”,也就是减负运算转换成数值形式再进行求和运算。
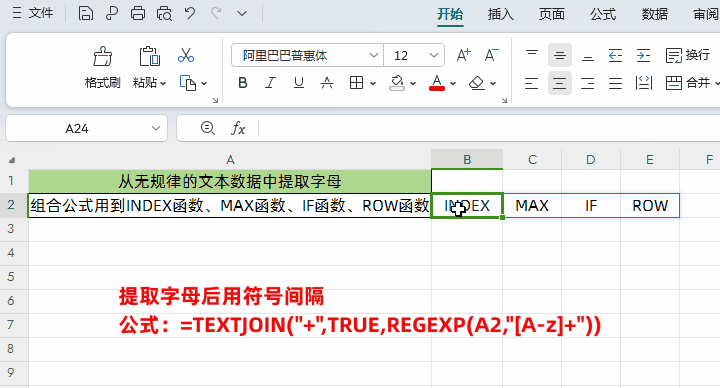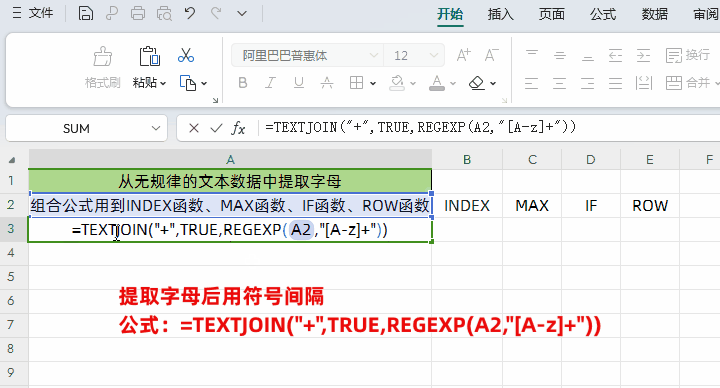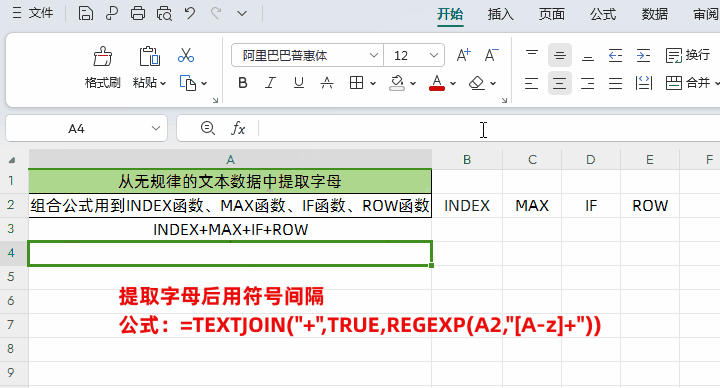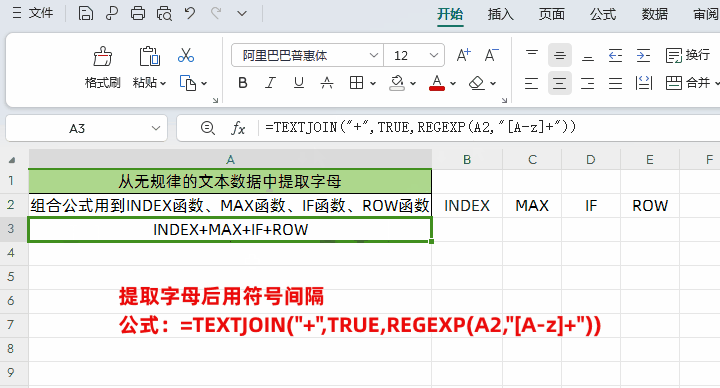
②把拆分后的内容用用“+”间隔开
公式:=TEXTJOIN("+",TRUE,REGEXP(A2,"[A-z]+"))
③把拆分后的内容连接到一起
公式:=CONCAT(REGEXP(A2,"[一-龟]+"))

以上就是【桃大喵学习记】今天的干货分享~觉得内容对你有所帮助,别忘了动动手指点个赞哦~。大家有什么问题欢迎关注留言,期待与你的每一次互动,让我们共同成长!
