CLIP是美国OpenAI团队的一项技术专利,凭借技术实力和无私开源,蜚声技术圈。它在图文方向上颇有进展,一举奠定了图文模型领域的第一块地基石。
虽是“陈年”论文,但时至2023年,它仍有生命力。
这张图展示了 CLIP 模型的训练过程。图中的左侧是图像编码器,它将图像转换为一个向量表示。图像编码器使用了 Transformer 架构。图中的右侧是文本编码器,它将文本转换为一个向量表示。文本编码器也使用了 Transformer 架构。
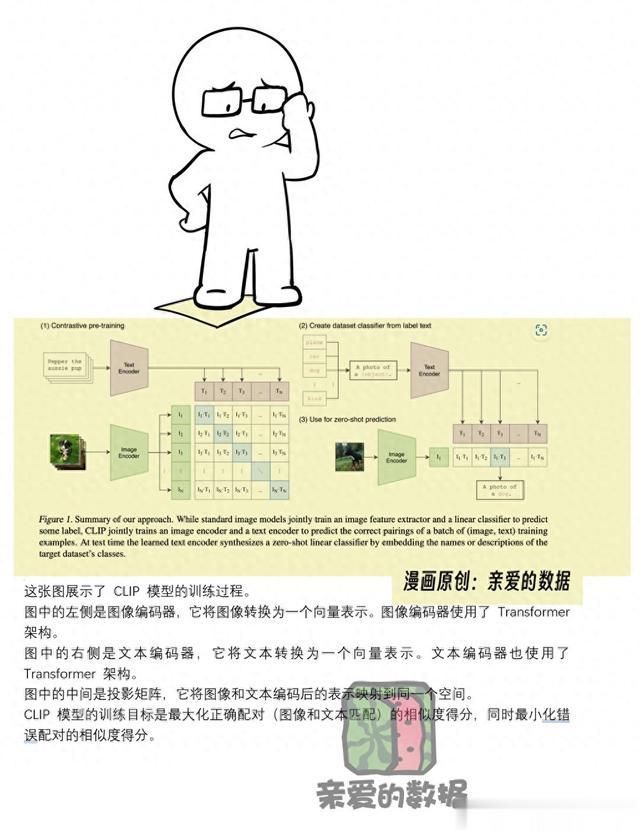
按道理图中的中间是投影矩阵,它将图像和文本编码后的表示映射到同一个空间。但是图中没有单独画出来,含在两个encoder里面了,I和T是投影过的特征向量。CLIP 模型的训练目标是最大化正确配对(图像和文本匹配)的相似度得分,同时最小化错误配对的相似度得分。具体来说,训练过程如下:
1.从一个大型图像-文本数据集中随机抽取一张图像和一句话。2.用图像编码器将图像转换为一个向量表示。3.用文本编码器将句子转换为一个向量表示。4.使用投影矩阵将图像和文本编码后的表示映射到同一个空间。5.计算图像和文本表示的相似度得分。6.如果图像和文本是正确配对的,则增加相似度得分。如果图像和文本是错误配对的,则减少相似度得分。7.重复步骤1-6,直到模型收敛。
通过这种训练方式,CLIP 模型能够学会将图像和文本之间的语义联系映射到相似度得分上。
CLIP 最大的亮点之一,能够将不同模式的数据,也就是文本和图像数据,映射到共享向量空间。这种共享的多模态向量空间使“文本到图像”和“图像到文本”的任务变得更加容易。
也就是融合训练。

《我看见了风暴:人工智能基建革命》,作者,谭婧
