开源大数据丨洞察报告
核心摘要:
大数据技术诞生至今已近20年,由于开源的加持,如今它已经成为数字经济的重要技术使能。但在其演进过程中,各类子技术的发展并不同步,他们的热度反应了行业中的多数关切,也引导着行业的未来走势。本报告从开发者视角,首先对当前大数据开源组件按照其功能类型进行分层梳理,明确各类型开源组件的定位以及组件间关系。报告核心部分通过热力图的方式,对12大类大数据组件中的代表性开源工具的热力趋势进行分析,以时序维度定量展示开源组件的相对热力变化,并讨论驱使热力变动的背景因素,以及热力变动所带来的行业焦点转换。最后,报告围绕平台底层的基础云设施与大数据组件适配问题提出评价标准,为个人及企业开发者的选型提供参考。

大数据技术的行业应用
大数据技术应用广度与深度持续加大,成为决定企业竞争力的重要因素
十多年来,随着大数据技术的演进与成熟,其在经济领域中的应用也在拓展并持续深化。目前,在包括医疗保健、零售、金融服务、制造业、电信、能源与公共服务的各主要行业中,大数据技术在精细管理、趋势预测、风险识别、决策支持等场景中发挥着越来越重要的作用。数字时代背景下,数据已成为企业核心资产,而大数据技术则是对这项资产开发,利用,赋能企业的重要手段,越来越多的企业认识到用对、用好大数据技术将决定自身的行业竞争力。

大数据工具的开源
开源趋势下,大数据传统工具已经成熟,个性化新型工具不断加入
狭义上的开源大数据工具是指在开源大生态下,专注于解决海量、多类型数据的连接、存储、管理等功能的工具集合。但从搭建大数据平台角度出发,通常还需要加入AI类组件以帮助数据分析,云原生工具以实现容器编排,另外关系型及各类非关系型数据库被视为大数据的基础,由此得到广义上的大数据工具套件。本报告将以广义大数据工具为研究对象,对其进行分析。

开源大数据工具的分类及功能
按功能类型分为5层11模块,合理的工具选型是搭建大数据平台的前提
大数据工具组件是大数据技术输出的载体,数字化与智能化时代下,一套完整的大数据工具可以分为基础层、数据连接层、编排与分析层、人工智能层、监控及可视化层共5层,包括储存格式、数据框架,数据库、数据管理、数据查询与连接、流处理与消息管理、数据编排、在线分析、机器学习运维、记录及监控、数据可视化11个模块。
大数据工具层级图是对大数据工具的总览,开源工具林林总总,企业应先解各个工具的定位与功能,根据自身需求牟定工具类型,再进行具体工具的选型。


热力趋势(1/12):数据存储
沿二进制存储、列存储、云上数据湖的路径演化,多样化容纳数据类型

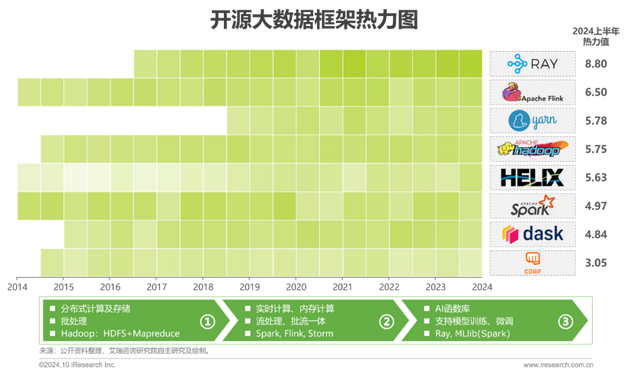
热力趋势(2/12):框架
大数据框架随数据量的扩大以及处理速度需求提升而迭代;进入大模型时代,大数据框架进而整合模型开发组件
热力趋势(3/12):数据库 - 之一
数据库种类逐渐丰富,支持云原生、大模型开发训练及实时分析

热力趋势(3/12):数据库 - 之二
数据库种类逐渐丰富,支持云原生、大模型开发训练及实时分析

热力趋势(4/12):数据管理
随系统复杂性提升,数据管理更注重数据血缘,版本控制及流程自动化

热力趋势(5/12):查询与连接
从批量到实时,从单一数据源到跨系统多元数据,从关系型数据到非关系型数据,工具的进化让数据查询更迅速、更灵活、更丝滑

热力趋势(6/12):流处理及消息管理
由简单的消息处理功能发展为功能复杂适应混合场景的数据管理工具

热力趋势(7/12):编排
大数据编排工具的演变反映了数据工作流不断变化的需求和复杂性

热力趋势(8/12):在线分析
由对数据的批量抓取分析发展为云原生可处理高并发的实时数据分析

热力趋势(9/12):机器学习运维 - 之一
由基础开发生命管理发展为以AI专有性能指标为核心设置的工具生态体系

热力趋势(9/12):机器学习运维 - 之二
由基础开发生命管理发展为以AI专有性能指标为核心设置的工具生态体系

热力趋势(10/12):记录与监测
由简单的日志管理及可视化发展为集日志、指标、追踪为一体数据观测栈

热力趋势(11/12):可视化
由静态、本地化解决方案向高互动性、云化、融合AI能力的方向演进

热力趋势(12/12):数据安全
从基础安全和监控能力发展到高级威胁检测,最终实现全面的访问管理和数据治理

开源大数据工具热力趋势总结
由于不同时期的技术挑战与应用需求促使大数据工具的迭代与丰富

云厂商开源大数据工具支持度比较
基础设施覆盖度、云计算成本及效用以及开源配套服务是影响客户在利用开源工具自建大数据平台时选型底层云平台的主要因素
基础设施覆盖度:云厂商更广阔的基础设施覆盖度意味着客户在进行大数据处理时的延迟时间更少,并可以选择本地化的部署方式,这对于需要低延时以及数据驻留合规性要求更为严格的国际化用户尤为重要。
云计算成本与效用:大数据的处理需要耗费海量计算资源,因此计算效率与成本效益是客户的重要考量因素。定制化核心基础硬件能够从底层增强云计算效率,从成本及能耗角度看也会带来显著提升。
开源配套服务:云平台对于开源大数据工具更广泛的配套服务以及更深度的融合决定了客户利用开源工具构建大数据平台的难易度与开发成本,客户更倾向于使用开源友好度高的云平台服务。
综合比较AWS,Azure与GCP三大全球性云厂商,AWS在基础设施覆盖的广度、云计算优化的深度、以及生态中开源配套服务的丰富度上均有一定优势,与当下处理复杂数据类型、重分析呈现的大数据热点开发组件契合度较高,是大数据云基础平台的优质选择。


说明(1/2):热力值意义及数据采集
热力值意义
本报告中所指热力趋势是从开发者视角所做的研究判断,通过对开发者围绕开源社区相关行为的定量分析,综合得到热力值,是开发者对该开源大数据工具的关注、参与、讨论、贡献的综合体现。
因此开源大数据工具的热力值越高,代表该工具能够更快速的迭代,受到更精细的优化打磨。从应用视角看,该开源工具更易被使用,并在应用场景中被广泛推开,即热力值由开发者端传导至应用端。事实上,许多开源大数据工具的应用者同时也是开发者,他们针对实践中的问题持续优化大数据工具,将解决方案回馈至开发社区。
基础数据
【数据来源】GH Archive: https://www.gharchive.org/;GithubStars Explorer: https://emanuelef.github.io/daily-stars-explorer
【数据采集时间】起始时间为最早有记录时间,终止时间为2024年6月30日
【数据采集对象】开源大数据工具所对应的Github代码仓(Repository ),而非对应的Github项目(Project )
核心指标
【选取范围及指标意义】指标选取范围为GH Archive可提供的17类Github事件,事件定义遵循GH Archive中对应的属性说明。
【指标选定逻辑】基于开发者在开源社区(Github)中的基础行为,选取Star、Fork、Issue、Commit、Pull Request五项核心指标,其他Github事件或为此五类事件的从属事件,或其本身一般性属性较低。
以下表格为GH Archive中所列举的17类事件,标色事件为本报告选取的五项基础指标。事件具体定义请参考Github文档:https://docs.github.com/zh/rest/using-the-rest-api/github-event-types。

说明(2/2):热力值计算方式
计算方式
【观察值提取】以半年为计算的标准时段,根据获取的时点基础数据,计算每半年指标变动值。即当年6月30日相对于上一年12月31日的变动值,以及当年12月31相对于当年6月30日的变动值。
【核心指标标准化处理】采用对数函数非线性标准化方式,通过指标极值确定阈值,对指标的观察值做进行无量纲化处理,便于不同数量级指标间进行综合分析和比较。

【AHP层次分析法加权】结合定量与定性分析,通过多位专家判断五项核心指标的相互重要程度,取几何平均后,确定偏好矩阵,再经过一致性检验后确定指标对热力值影响,即指标在计算热力值中所占权重。

【热力值计算及展现】根据各指标权重及该指标中开源大数据工具的标准化值,加权计算该开源大数据工具热力值。以半年为基础热力区间,展示热力图。热力图中每一格对应时间(横坐标)与开源工具(纵坐标),颜色深浅代表热力值大小。

