
来源:学术头条
近日,OpenAI 突然发布了他们的「最具性价比」的新一代模型 GPT-4o mini。
据介绍,GPT-4o mini 将取代 GPT-3.5 Turbo,立即在 ChatGPT 免费上线,其在 MMLU 上的得分率为 82%,在 LMSYS 排行榜上的聊天偏好方面优于 GPT-4。
GPT-4o mini 不仅性能更优,价格也比 GPT-3.5 Turb 便宜了 60%,每百万输入 token 为 15 美分,每百万输出 token 为 60 美分。
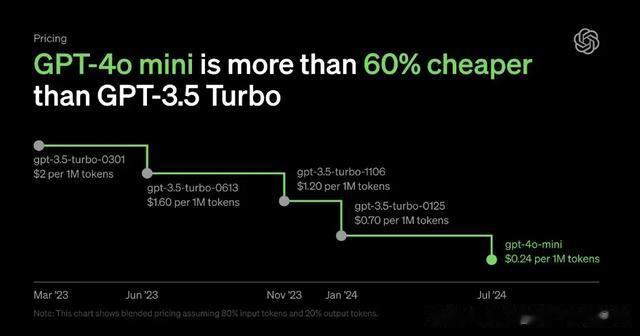
OpenAI 在官方博客中表示,GPT-4o mini 将大大扩展人工智能(AI)应用的范围,使智能变得更加经济实惠。
GPT-4o mini 以其低成本和低延迟实现了各种任务,如连锁或并行多个模型调用(如调用多个应用程序接口)、向模型传递大量上下文(如完整代码库或对话历史)或通过快速、实时文本回复与客户交互(如客户支持聊天机器人)的应用。
目前,GPT-4o mini 的API支持文本和视觉,未来还将支持文本、图像、视频和音频输入和输出。该模型的上下文窗口可容纳 128K token,每个请求最多支持 16K 输出 token,知识期限到 2023 年 10 月。由于改进了与 GPT-4o 共享的 tokenizer,GPT-4o mini 处理非英语文本更加经济高效。
兼具出色文本、多模态能力的小模型
据官方博客介绍,在文本智能和多模态推理方面,GPT-4o mini 在学术基准测试中超越了 GPT-3.5 Turbo 和 Gemini Flash、Claude Haiku,并支持与 GPT-4o 相同的语言范围。与 GPT-3.5 Turbo 相比,GPT-4o mini 还提高了长上下文性能。
目前,OpenAI 已在多个关键基准上评估了 GPT-4o mini 在推理任务、数学/编码能力、多模态推理方面的表现。
推理任务:在涉及文本和视觉的推理任务方面,GPT-4o mini 优于其他小型模型,在文本智能和推理基准 MMLU 中的得分率为 82.0%,而 Gemini Flash 为 77.9%,Claude Haiku 为 73.8%。
数学和编码能力:GPT-4o mini 在数学推理和编码任务方面表现出色,优于市场上以前的小模型。在测量数学推理的 MGSM 中,GPT-4o mini 的得分率为 87.0%,而 Gemini Flash 为 75.5%,Claude Haiku 为 71.7%。在衡量编码性能的 HumanEval 中,GPT-4o mini 的得分率为 87.2%,而 Gemini Flash 为 71.5%,Claude Haiku 为 75.9%。
多模态推理:GPT-4o mini 在多模态推理评估 MMMU 中也表现出色,得分率为 59.4%,而 Gemini Flash 为 56.1%,Claude Haiku 为 50.2%。
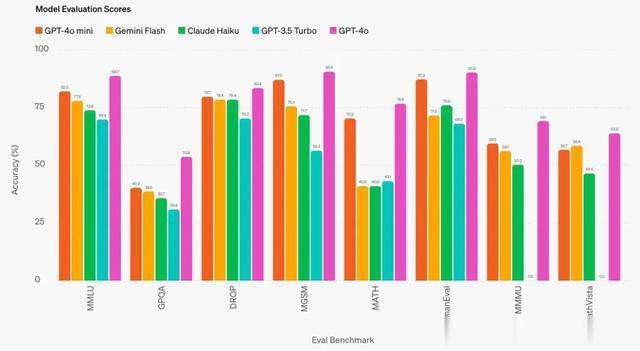
此外,OpenAI 还发现,GPT-4o mini 在从收据文件中提取结构化数据或在提供线程历史记录时生成高质量电子邮件回复等任务方面的性能,明显优于 GPT-3.5 Turbo。
内置安全措施
在安全性方面,OpenAI 在预训练中就过滤掉不希望模型学习或输出的信息。在后期训练中,他们使用 RLHF 等技术使模型的行为与人类的策略保持一致,从而提高模型响应的准确性和可靠性。
GPT-4o mini 内置了与 GPT-4o 相同的安全缓解措施,OpenAI 根据 Preparedness Framework 和自愿承诺,通过自动和人工评估对其进行了仔细评估。70 多名社会心理学和错误信息等领域的外部专家对 GPT-4o 进行了测试,以确定潜在风险。这些专家评估得出的见解有助于提高 GPT-4o 和 GPT-4o mini 的安全性。
在这些经验的基础上,OpenAI 还利用研究中获得的新技术努力提高 GPT-4o mini 的安全性。API 中的 GPT-4o mini 是第一个应用指令分层方法的模型,该方法有助于提高模型抵御越狱、提示注入和系统提示提取的能力。这使得模型的响应更加可靠,有助于在大规模应用中更安全地使用。

声明
本文素材来源于网络,人工智能产业链联盟(union)整理编辑,不代表人工智能产业链联盟(union)立场,转载请注明,如涉及作品版权问题,请联系我们删除或做相关处理!
编辑:Zero
