
计算机视觉的GPT时刻,来了!
最近,来自UC伯克利的计算机视觉「三巨头」联手推出了第一个无自然语言的纯视觉大模型(Large Vision Models),并且第一次证明了纯视觉模型本身也是可扩展的(scalability)。

值得一提的是,让LVM做非语言类智商测试(Raven's Progressive Matrices)中常见的非语言推理问题,它时常能做出正确的推断。
对此,研究人员惊喜地表示,这或许意味着LVM也展现出了「AGI的火花」!
纯视觉模型的逆袭
最近一段时间以来,GPT 和LLaMA 等大型语言模型(LLM) 已经风靡全球。
随着大语言模型的爆发,不管是学术界还是业界,都开始尝试使用「文本」来扩大视觉模型的规模。
包括GPT4-V在内的SOTA模型,都是把视觉和文字组合在一起训练的。

以「苹果」为例,这种方法在训练时不仅会给模型看「苹果的照片」,而且还会配上文字「这是一个苹果」。
然而,在面对更加复杂的图片时,就很容易忽略其中大量的信息。
比如「蒙娜丽莎」应该怎么去描述?或者摆满各种物品的厨房的照片,也很难清晰地被描述出来。
对此,来自UC伯克利和约翰斯·霍普金斯大学的研究人员,提出了一种全新的「视觉序列」建模方法,可以在不使用任何语言数据的情况下,训练大规模视觉模型(Large Vision Model)。

这种名为「视觉序列」的通用格式,可以在其中表征原始图像和视频,以及语义分割、深度重建等带标注的数据源,且不需要超出像素之外的任何元知识。
一旦将如此广泛的视觉数据(包含4200亿个token)表征为序列,就可以进行模型的训练,让下一个token预测的交叉熵损失最小化。
由此得到的LVM模型,不仅可以实现有效地扩展,完成各种各样的视觉任务,甚至还能更进一步地涌现出比如数数、推理、做智力测试等能力。
简单来说就是,大规模视觉模型只需看图训练,就能理解和处理复杂的视觉信息,完全不用依赖语言数据。
如何构建大视觉模型
此前,使用预训练模型的价值 (例如ImageNet预训练的AlexNet),早在2015年就已经在R-CNN中得到了证明。
从此, 它从此成为计算机视觉的标准实践。

而自监督预训练,作为一种大大增加可用于预训练的数据量的方法被提出。
不幸的是,这种方法并不是很成功,可能是因为当时基于CNN的架构没有足够的能力来吸收数据。
随着Transformer的推出,其容量变得高得多,因此研究人员重新审视了自监督预训练,并发现了基于Transformer的掩码图像重建方法,例如BEiT, MAE,SimMIM,它们要比基于CNN的同类方法表现好得多 。

然而,尽管如此,目前预训练的纯视觉模型在扩展到真正大的数据集(例如LAION)时,还是遇到了困难。
那构建一个大规模视觉模型(Large Vision Model,LVM),需要哪些要素呢?
LLaVA 等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。
比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管它们和人类的语言体系「两模两样」。

最近,UC 伯克利和约翰霍普金斯大学的研究者探讨了另一个问题的答案—— 我们仅靠像素本身能走多远?
研究者试图在 LVM 中效仿的LLM 的关键特征:1)根据数据的规模增长进行扩展,2)通过提示(上下文学习)灵活地指定任务。
他们指定了三个主要组件,即数据、架构和损失函数。

在数据上,研究者想要利用视觉数据中显著的多样性。
首先只是未标注的原始图像和视频,然后利用过去几十年产生的各种标注视觉数据源(包括语义分割、深度重建、关键点、多视图 3D 对象等)。
他们定义了一种通用格式 —— 「视觉句子」(visual sentence),用它来表征这些不同的注释,而不需要任何像素以外的元知识。训练集的总大小为16.4 亿图像/ 帧。
在架构上,研究者使用大型 transformer 架构(30 亿参数),在表示为token 序列的视觉数据上进行训练,并使用学得的tokenizer 将每个图像映射到256 个矢量量化的token 串。

在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方法。
一旦图像、视频、标注图像都可以表示为序列,则训练的模型可以在预测下一个 token 时最小化交叉熵损失。
通过这一极其简单的设计,研究者展示了如下一些值得注意的行为:
随着模型尺寸和数据大小的增加,模型会出现适当的扩展行为;
现在很多不同的视觉任务可以通过在测试时设计合适的 prompt 来解决。
虽然不像定制化、专门训练的模型那样获得高性能的结果, 但单一视觉模型能够解决如此多的任务这一事实非常令人鼓舞;
大量无监督数据对不同标准视觉任务的性能有着显著的助益;
在处理分布外数据和执行新的任务时,出现了通用视觉推理能力存在的迹象,但仍需进一步研究。
实验结果
最后,研究人员评估了模型的扩展能力,以及它理解和回答各种提示任务的能力。
1.扩展
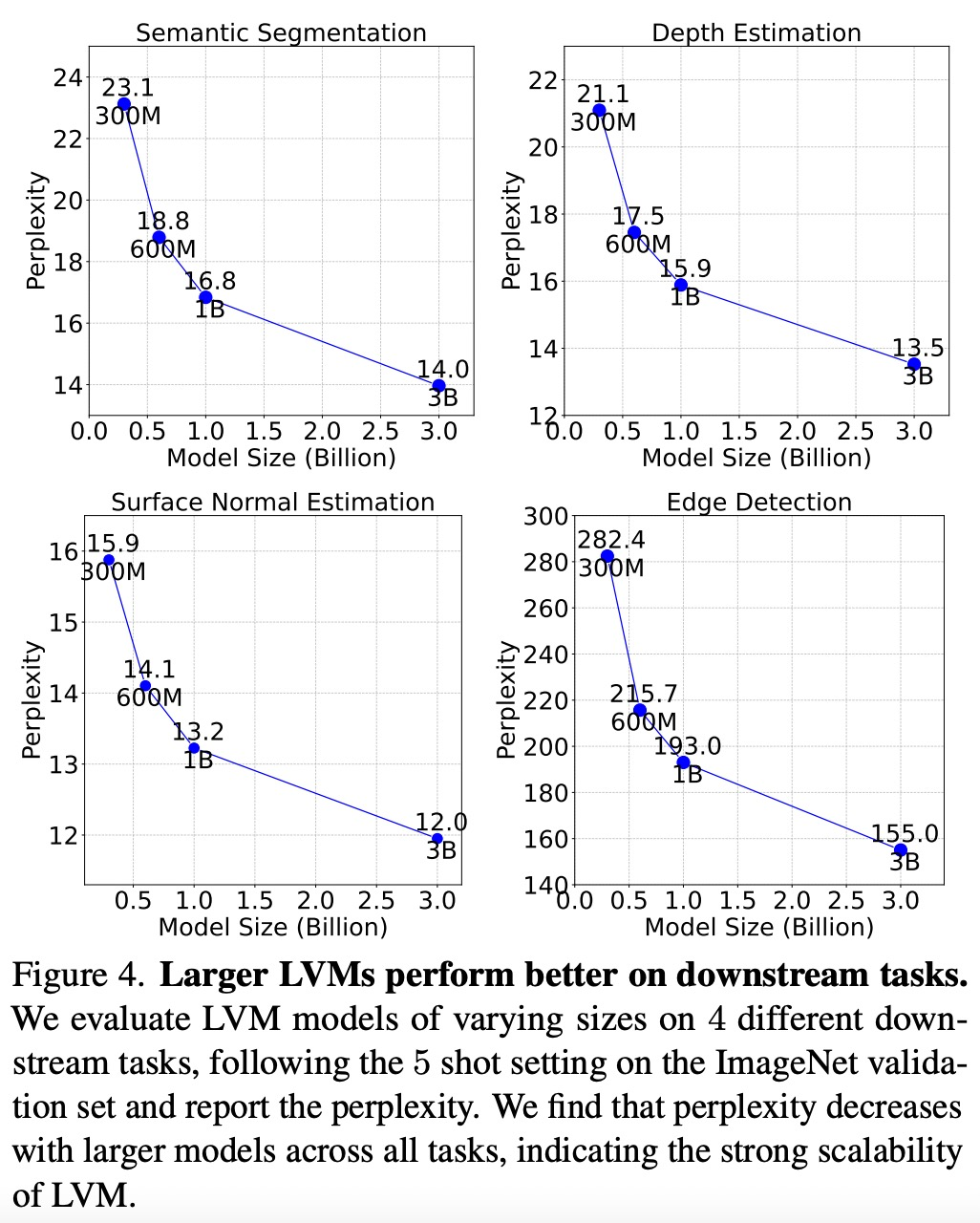
如下图所示,该研究首先检查了不同大小的 LVM的训练损失。

如下图所示,较大的模型在所有任务中复杂度都是较低的,这表明模型的整体性能可以迁移到一系列下游任务上。
如下图所示,每个数据组件对下游任务都有重要作用。LVM 不仅会受益于更大的数据,而且还随着数据集的多样性而改进。

2.序列 prompt
为了测试 LVM对各种prompt的理解能力,该研究首先在序列推理任务上对LVM进行评估实验。其中,prompt非常简单:向模型提供7张图像的序列,要求它预测下一张图像,实验结果如下图所示:

那么,需要多少上下文(context)才能准确预测后续帧?
该研究在给出不同长度(1到 15帧)的上下文prompt情况下,评估了模型的帧生成困惑度,结果如下图所示,困惑度从1帧到11帧有明显改善,之后趋于稳定(62.1→ 48.4)。

要想达成视觉的GPT时刻,现在的基础设施建设还远远不够。
尤其是,视觉需要一个充分复杂的交互环境和足够丰富的任务(包括收集各种instruction),而按照现在的技术水平,这样的基础设施建设,即使整 个业界共同努力,在顺利找到方向的前提下,至少还需要3-5年。
这种3D认知能力,或许来源于我们从出生开始就不断观看的每秒24 frame除了睡觉不间断的视频数据。

我们从一开始就不断注视着物体旋转,倾斜,好奇宝宝一般的看看左侧又看看右侧,看完底面又看看顶面。
这种巨量的数据让我们早早的就熟悉了三维空间中的各种变换,看到一个视角就能立刻想到另一个。
更不用说我们的视觉是三维的,连珍贵的深 度信息都能直接获取。
然而,过去大多数视觉AI是怎么训练的?只不过是数据集中孤立的一张张图片而已,每个物品每个场景只会从某个视角出现一次。

这种情况下怎么 能指望模型有3D的理解能力呢?因此,稍微换个视角就会让神经网络失效完全不奇怪了 为了解决这个问题,目前来说,唯一适合的训练素材是视频。
视频的帧间预测 强迫模型学习三维空间中不断变化的视角,有助于构建模型理解三维变换的能力。
最后,虽然不是完全没有,但LVM的few-shot能力还是和GPT差远了,而few-shot才是GPT之所以是GPT的原因。

LVM执行的绝大多数任务,说到底还是训练集中本来就专门使用了的:分割,检测,视角变换,风格化...这个角度来说,LVM只是把各种任务训监督学习练进了同一个模型而已。
而GPT,相比之下,可以执行“以李清照的风格给代码写注释”这种摸不着头脑的任务。从这个角度来说,LVM距离GPT的路还很长很长。vision-text双模态模型是这方面的捷径。
