
目录
一、业务背景
1. 使用场景
2. 解决问题
二、框架设计
1. 整体架构
2. 状态设计
3. 算子实现
4. 混合状态存储架构
5. 特征冷启动
三、案例优化
四、写在最后
一
业务背景
使用场景
推荐系统在当今的互联网应用中扮演着至关重要的角色,它极大地丰富了用户体验,帮助用户在海量信息中发现和探索他们可能感兴趣的内容。然而,随着数据量的激增和用户需求的日益多样化,传统的离线推荐系统已经难以满足用户对于实时性和个性化推荐的需求。在这种背景下,实时推荐系统应运而生,它能够迅速响应用户的行为变化,并提供更为精准的个性化推荐。
为了实现这一目标,高效的实时推荐系统必须能够持续更新用户和物品的特征,以实时捕捉和反映它们的最新行为和兴趣变化。在这个过程中,实时特征的准确性和稳定性变得至关重要,它们直接影响到推荐系统在生产环境中的效果表现。

解决问题
目前特征体系可以分为两类:统计类型、属性类型。

在实时特征计算的实践中,如果单纯依赖Flink SQL而不进行定制开发,可能会面临一些挑战,例如处理同质滑窗特征状态的冗余性以及特征冷启动的线上问题。为了突破这些限制,需要构建一个全面的实时处理框架,以适应多样化的实时特征业务场景。
该框架旨在简化与底层组件(如Flink、Kafka、Redis、HBase等)的交互,隐藏其复杂性,让业务开发人员无需深入了解这些组件的细节。通过内置的序列特征和滑动窗口特征算子,开发人员可以专注于业务逻辑的实现,从而提升开发效率和系统的可维护性。
二
框架设计
整体构架
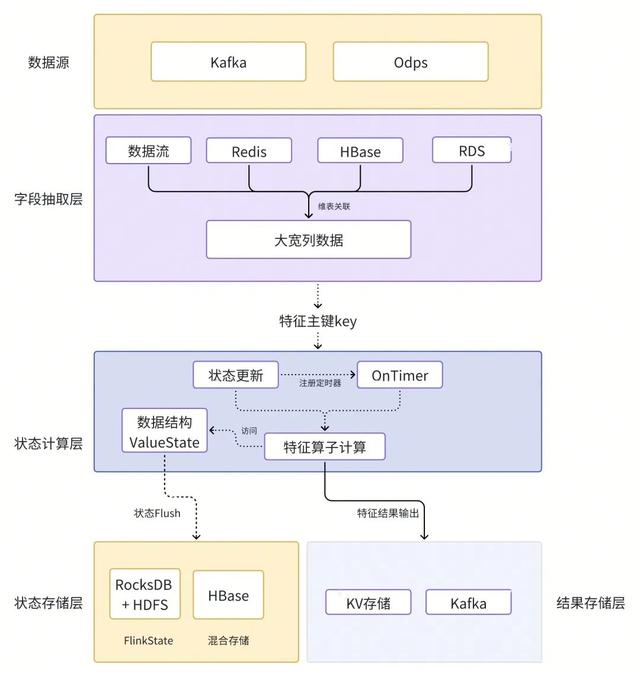
状态设计
业务上有许多同质滑窗特征,它们具有相同的计算逻辑,但查询的窗口长度各异。如果对每个滑窗特征都使用Flink原生的hopWindow,不仅会导致状态的无限膨胀,还可能在数据刷新时引发IO爆炸的风险。为了解决这一问题,我们对状态管理进行了优化重构。
根据最小的窗口单位将状态划分为多个分片,确保每个分片对齐到完整的时间粒度。例如,如果以小时为单位,就对齐到每小时的整点;如果以天为单位,则对齐到每天的0点。这样,具有相同窗口单位的特征就可以共享状态,例如,最近1小时、2小时、3小时的统计特征都可以从1小时的分片中进行统计。
当数据到达时,根据事件的时间戳(eventTime)将其合并到相应的分片中。然后,根据窗口的大小配置,查询对应的分片并进行聚合,最后刷出聚合结果。这种方法不仅提高了数据处理的效率,还降低了系统资源的消耗。

通过上面的状态重构方案,我们来解决滑动窗口的两类问题:
比如计算一个item最近1小时、2小时、3小时内的曝光数、点击数和转化数。
满足不同长度时间周期的计算
可以根据窗口单位选择对应的分片进行合并计算,这意味着,可以直接利用已经对齐到小时分片的状态,而无需为每个不同长度的窗口单独维护状态。

满足不同查询时间(滑动查询)的计算
在处理滑动查询时,如果遇到数据上报的空白期,比如11:00到12:00之间没有数据,我们利用Flink的定时器功能来应对。通过设定定时器,可以在没有新数据到达时自动触发计算,将这段时间的数据视为0,并更新状态。这样,即使数据上报出现间断,我们也能确保推荐系统的状态保持最新。

算子实现
接口定义
框架设计了三种核心算子来处理实时特征:普通序列特征算子、滑动序列特征算子和滑窗统计算子。这些算子都继承自一个公共的算子抽象类,并实现了特定的方法来执行它们的功能。
compute 方法负责根据事件时间(eventTime)来获取相应的状态分片,注册下一个触发计算的定时器,并完成聚合结果的输出。这个方法是算子处理实时数据流的核心,确保了数据的实时处理和状态的及时更新。
onTimer 方法则处理定时器触发时的逻辑。当定时器触发时,它会根据触发时间(triggerTime)扫描相应的状态分片,并输出聚合结果。这允许算子在预定的时间点进行数据的聚合和输出,即使在数据流中出现间隙或延迟的情况下也能保持计算的连续性。
// 计算特征结果,由子类实现public abstract void compute(long processTimeInMillis, FcDataObj input, byte[] stateBytes, StateContext context) throws InvalidProtocolBufferException;// 定时器触发时调用的方法,由子类实现public void onTimer(long triggerTime, byte[] currentStateBytes, StateContext context) throws Exception {}生产逻辑
以滑窗统计为例,具体讲解下生产逻辑:
根据时间轴按照指定的粒度切分不同的分片收到新的数据上报,根据eventTime合并到对应分片根据配置的窗口大小,取出对应分片合并计算特征结果,同时注册下一次触发的定时器(分片滑出窗口的时间)定时器触发按照triggerTime扫描出在窗口大小内的分片数据,进行合并计算窗口的滑入滑出均以分片为单位,因为分片为特征的最小精度
混合状态存储架构
在实时特征生产场景中,Flink任务常常需要处理大规模状态数据。生产环境中可能会遇到两个主要问题:
当状态数据量达到TB级别时,在保证数据不丢失、不重复的语义下,一旦发生故障需要恢复,恢复速度会很慢,导致业务中断时间较长,通常超过10分钟目前 Flink SQL 的状态恢复机制较为严苛,在很多场景下,作业变更无法从原先状态恢复,对于新增特征的需求,希望能够在状态上直接进行更新,实现无损重启。为了解决这些问题,框架实现了状态的冷热数据分离,热数据在FlinkState内,冷数据(包含热数据)存储在外部存储(Redis,HBase)。
在任务执行过程中,会优先从FlinkState中读取数据。如果FlinkState中没有找到所需的数据,则会从外部存储系统中加载。每次执行checkpoint操作时,会将状态的变更部分同步到外部存储中,以此确保数据的一致性。这样的设计既保证了数据的高可用性,也提高了系统的容错能力。

任务恢复时,不再将全量数据同步拉取、同步加载。而是同步加载热数据,运行时按需查询冷数据。热数据加载完毕后,整个任务即可开始运行。

若要在现有状态中添加新特征,可以采用旁路离线任务的方式,将新特征作为额外的一列写入外部存储。一旦数据同步完成,只需对现有的任务逻辑进行相应的修改,即可实现新特征的无缝集成。
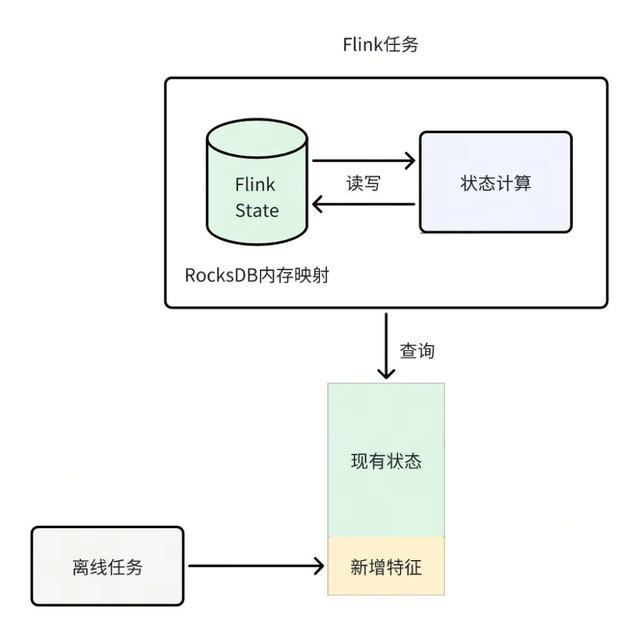
特征冷启动
对于超长窗口的聚合统计,例如30天的特征,无需等待特征任务上线30天后才能使用。可以使用离线数据完成状态的补全,然后再使用增量数据进行实时特征更新。
使用混合Source完成批流任务切换的步骤如下:
利用离线数据(例如ODPS表中存储的最近n-1天的历史数据)来完成状态的初始化。这一步骤中,我们将数据同步到外部存储,但不做即时的聚合结果输出。将数据源切换为Kafka,并调整偏移量,使其从当天的0点开始消费数据。这样就可以进行特征的更新和计算。
三
案例优化
测试任务:统计瀑布流场景下item最近1hour/2hour/3hour/4hour/5hour/6hour的曝光量和点击量。
使用Flink SQL的hopWindow进行多特征计算,遇到反压问题,导致checkpoint超时失败。
下面是两种计算方式的性能对比:

在相同的计算资源和处理相同量级数据的条件下,实时特征框架任务的性能优于Flink SQL任务。
四
写在最后
实时特征框架通过内置的多种算子,灵活应对不同的业务场景,并且设计多种优化方案以提升性能:
通过共享状态的方式处理滑动窗口聚合特征,这样不仅减少了计算量,也减轻了IO压力。采用混合状态存储架构,使得大规模状态任务能够快速恢复,提高了系统的可靠性。支持从外部构建状态,从而实现特征的冷启动,这为新特征的快速接入提供了可能。我们期待在未来的迭代中,这一框架能够不断进化,以适应更多场景的需求。
