我最近有机会与IBM杰出工程师、IBM剑桥研究中心主任Lisa Amini博士讨论了当前的IBM人工智能发展,该研究中心是麻省理工-IBM Watson AI实验室的所在地。在此之前,Amini博士曾担任IBM纽约TJ Watson研究中心认知计算小组的知识与推理研究主管,他在哥伦比亚大学获得了计算机科学博士学位。Amini博士和她的团队隶属于IBM Research,任务是创建下一代Automated AI(自动化人工智能)和数据科学。
我对于“自动化对人工智能和机器学习生命周期的影响”这个话题很感兴趣,并与Amini博士集中讨论了AutoAI的下一代功能。
AutoAI自动执行高度复杂的任务,为数据寻找并优化最好的机器学习模型、特征和模型超参数。AutoAI完成了原本需要专业数据科学家团队和其他专业资源才能完成的工作,且速度要快得多。

人工智能建模颇具挑战性

图:“数据科学家想要多自动化?”(图片来源/IBM)
构建人工智能和机器学习模型,是一项涉及多方面的工作,涉及收集需求和将问题公式化。在模型训练开始之前,必须获取、评估数据,并对其进行预处理,以识别并纠正数据质量问题。
由于这个过程非常复杂,因此数据科学家和机器学习工程师通常会创建“机器学习管道”将这些步骤连接在一起,以便在每次优化数据和模型时重复使用。“管道”为模型训练、测试、部署及推理处理数据清理和操控。构建和调整管道不仅复杂,而且还是一项劳动密集型的工作。它需要一个训练有素的资源团队,他们要了解数据科学,还要有了解模型目的和输出的主题专家。
这是一个漫长的过程,因为要做出很多设计选择,并且要针对各种数据的处理和建模阶段进行无数次优化调整。
管道的高度复杂性使其成为自动化的首要对象。
IBM AutoAI在人工智能全生命周期中自动建模

图片来源/IBM
Amini博士表示,AutoAI可以在几分钟内完成通常需要整个数据科学家团队数个小时到数天才能完成的工作。自动化功能包括数据准备、模型开发、特征工程和超参数优化。

图片来源/IBM
整个建模过程端到端的自动化可以显著节省资源。以下是AutoAI的部分功能列表:
自动分析数据,并针对预测建模问题自动生成个性化的模型管道。
模型管道是在 AutoAI 分析数据集并发现最适合问题设定的数据转换、算法和参数设置时迭代创建的。
结果显示在排行榜上,并根据问题优化目标,对自动生成的模型管道进行排名。
从数据准备,到算法选择,再到模型创建,流程的每个阶段都提供可视化。
用户只需单击鼠标,即可轻松部署模型,或为任何管道生成Python notebook。
用于持续模型改进的自动化任务,可以在需要时,将AI模型API集成到应用程序中。
AutoAI显著提高了生产力。只需点击几下鼠标,即使是只有基本数据科学技能的人,也可以使用自定义数据自动选择、训练并调优高性能机器学习模型。
而专业的数据科学家,可以快速迭代可能的模型和管道,并试验最新的模型、特征工程技术和公平算法,无需从头开始编写管道代码。
未来的人工智能自动化项目
IBM Research正在开展多个下一代人工智能自动化项目,例如处理新数据类型的下一代算法,实现新的自动化质量和公平性,并显著提高规模和性能。
Amini博士深入探讨了两个特别有趣的、用于扩展企业人工智能的下一代功能:AutoAI for Decisions和Semantic Data Science。
用于改进决策的AutoAI
时间序列预测,是最流行但也是最困难的预测分析之一。它使用历史数据来预测未来结果出现的时间。时间序列预测通常用于财务计划、库存和产能规划。数据集的时间维度使分析变得困难并且需要更高级的数据处理。

IBM的AutoAI产品已经支持时间序列预测。它自动执行以下步骤来构建预测模型:
为训练准备数据集
根据数据类型确定需要哪种模型,例如分类还是回归
将适当的插补转换器置入管道中以处理丢失的数据
通过确定哪些数据列能够最好地支持问题来进行特征选择
测试各种超参数调整选项以获得最佳结果
根据准确性和精确度等因素生成管道并对其排名。
Amini博士解释说,在许多环境中,创建时间序列预测之后,下一步是利用预测来改进决策。
例如,数据科学家可能会建立一个“时间序列预测模型”预测产品需求,但是该模型也可以作为库存补货决策的输入,通过减少成本、高昂的大量库存积压、或者避免由于库存告罄造成的销售损失,实现利润最大化。
有时,我们会用简单的启发式方法进行库存补货决策,例如,决定何时应该补货,以及补货的数量。在另一些情况下,我们会用被称为“决策优化”的更系统性方法来构建规范性模型,以补充时间序列预测模型。
规范性分析(与预测性分析相反)使用复杂的数学建模技术和数据结构进行决策优化,并利用供应短缺的专业知识。然而,像AutoAI生成预测模型那样直接根据数据自动化生成决策优化管道的产品,目前还不存在。
多模型管道

Amini博士解释说,同时使用机器学习和决策优化,才能得到最好的结果。为了支持该功能,IBM的研究人员正在开发“多模型管道”,以适应预测性模型和规范性模型的需求。“多模型”将允许业务分析师和数据科学家使用通用模型从各自的角度讨论问题。这样的产品同样需要资源协作。
深度强化学习自动化
现在可通过IBM Research的Early Access计划,获得为决策模型自动生成管道的新功能。它利用深度强化学习来学习从数据到决策策略的端到端模型。这项名为“AutoDO(自动决策优化)”的技术利用强化学习(RL)模型,让数据科学家能够训练机器学习模型,在不确定的情况下执行顺序决策。强化学习(RL)的自动化至关重要,因为RL算法对内部超参数高度敏感。因此,它们需要大量的专业知识和手动工作对它们进行调整,以适应特定的问题和数据集。
Amini博士解释说,该技术会根据数据和问题,自动选择使用最好的强化学习模型。它还可以使用高级搜索策略,为模型选择最佳的超参数配置。
该系统可以自动搜索历史数据集或任何兼容的环境,以自动生成、调整最佳RL管道,并对它们进行排名。该系统支持各种类型的强化学习,包括在线和离线学习以及无模型和基于模型的算法。
自动扩展人工智能
强化学习自动化解决了在企业中扩展人工智能的两个紧迫问题。
首先,它为顺序决策问题提供了自动化,在这类问题中,不确定性可能会削弱启发式甚至是不使用历史数据的正规优化模型。
其次,它为具有挑战性的强化学习模型构建领域带来了一种自动化、系统化的方法。
Semantic Data Science(语义数据科学)
AutoAI之类最先进的自动化机器学习产品可以有效地分析历史数据,创建自定义机器学习管道并对其进行排名。它包括自动化特征工程——可扩展和增强数据的特征空间以优化模型性能。自动化方法目前依靠统计技术来探索特征空间。
但是,如果数据科学家理解了数据的语义,就有可能利用领域知识来扩展特征空间,从而提高模型准确性。这种扩展可以使用来自内部或外部数据源的补充数据来完成。特征空间是用于表征数据的一组特征。例如,如果数据是关于汽车的,则特征空间可能是福特、特斯拉、宝马。
可以在现有的python脚本或者文献中描述的关系中找到补充的特征转换。尽管如此,要知道哪些特征和转换是相关的,用户必须具备足够的技术技能来破译和翻译代码和文档。
数据科学家的新语义能力
Amini博士介绍了IBM Research创建的另一个强大的新功能,该功能被称为“Semantic Data Science(语义数据科学)”,它可以自动监测给定数据集的语义概念。语义概念表征概念,帮助理解单词和句子,从而提供了一种表达含义的方式。一旦AutoAI检测到正确的语义概念,程序就会使用这些概念广泛搜索现有代码、数据和文献中可能存在的相关特征和特征工程操作。
AutoAI可以使用这些新的、语义丰富的特征来提高生成模型的准确性,并通过这些生成的特征提供可供人类阅读的解释。

即使没有评估这些语义概念或者新功能的专业知识,数据科学家们还是可以试用AutoAI。但是,想要理解发现的语义概念,可以使用Semantic Feature Discovery(语义特征发现)可视化资源管理器来探索发现的关系。
用户只需单击Sources超链接,即可直接从可视化资源管理器进入新功能生成的Python代码或文档,如下图所示。
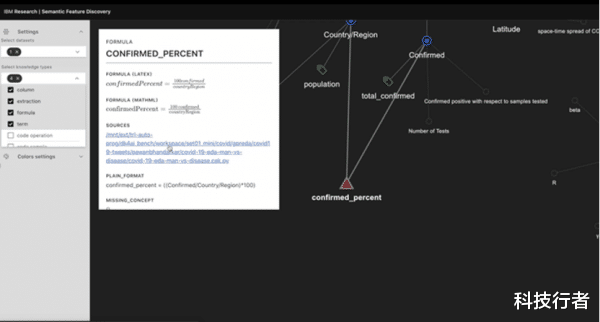
IBM Research Early Access产品也包含了Semantic Data Science功能。甚至可以在IBM的API Hub上试用其中一些功能。
Amini博士用一句话总结了IBM对AutoAI投入的大量研究工作,并以此结束了我们的谈话:
“我们希望AutoAI和Semantic Data Science去做专家数据科学家想做、但是因为没有时间或者不具备专业知识而不总是能够自己完成的事情。”
要点总结
AutoAI允许没有深厚数据科学专业知识的人,生成各种类型的模型,即使是那些具有深厚数据科学专业知识的人,也可以用它更快速地进行原型设计和迭代。使用AutoAI可以快速大规模地生成模型。
AutoAI将减少建模的工作量,并提高生产力和准确性。它还将增加部署并投入运营的企业模型的数量。
AutoAI for Decisions将自动生成管道可以解决的问题类型,扩展到需要在不确定性和强化学习下进行决策优化的问题。
Semantic Data Science将为建模过程增添助力。它将充当专家资源广泛收集并整合难以找到的、各种类型和来源的信息,从而提高在建模型的质量。
AutoAI是IBM Watson Studio的一部分。
