
训练大模型有多烧钱?
解锁大型语言模型的运行秘诀
大型语言模型 (LLM) 对硬件要求很高,其中显卡内存至关重要。Meta 的 LLaMA 2 模型提供了规模不等的选项:
* 70B 模型:320GB GPU 内存
* 13B 模型:50GB GPU 内存
* 7B 模型:30GB GPU 内存
选择合适的 GPU 内存容量可确保 LLM 平稳运行,释放其强大的语言处理能力。
利用量化技术,可牺牲模型精确度以降低内存占用量。与性能略差的机器人对话时,即使没有独立显卡,使用 CPU 即可运行 LLaMA 2。该技术可将内存需求减至原先的一半、四分之一甚至八分之一。
体验 Meta 开源的 LLaMA 2,一款高度可定制的大型语言模型。它的灵活性让您可以根据自己的具体需求进行重新训练和微调,解锁无穷无尽的应用程序。
LLM模型训练成本高昂,如OpenAI模型,每小时微调成本为34至103美元。预估LLaMA 2模型微调成本将远超此价格范围,具体取决于所需计算量。
LLaMA模型训练耗时惊人,其7B版本训练时间为21年(基于单张A100 GPU),而70B版本则需要103年。Meta使用大量A100 GPU,7B模型训练成本为27.6万美元,70B模型为170万美元。这些数字凸显了大语言模型训练的计算密集性和高昂成本。
A100和RTX4090算力相差不大,但是显存大小和传输频宽就很重要:
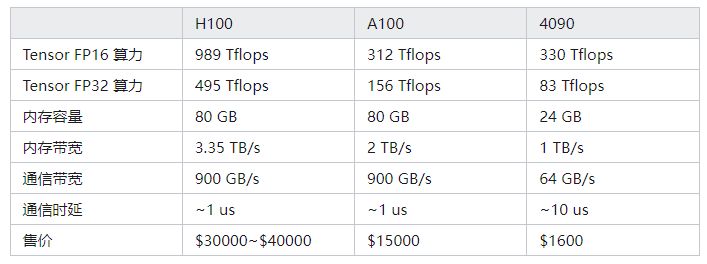
采用 A100 GPU 可将 PyTorch 训练和测试的吞吐量提升 40%(高于 RTX 4090),而采用 H100 GPU 可提升 60-150%。

优化文本
使用 6 倍模型参数量乘以训练数据 Token 数可估算训练算力(Flops)。
Google Colab 提供按月订阅服务:
* Pro:100 个运算单元,每月 10.49 美元
* Pro+:500 个运算单元,每月 52.49 美元
以 A100 GPU 为例,每小时耗用约 13 个运算单元,折合每 GPU 小时 1.36 美元。
利用 27,540 个经过严格挑选的示例对 Meta 的 LLaMA 模型进行微调,大幅提升了其性能。这些示例使模型能够更深入地理解问题并提供准确的答案。
xxxLLaMA,基于LLaMA 2的微调模型,专为繁体中文处理而设计,包含两个阶段,以增强中文处理能力。
LLaMA 2模型在预训练阶段使用8块A100 GPU进行了两周的训练,熟练掌握了中文语言的关键语法和特征。指导微调:通过 12 小时的微调,8 块 H100 GPU 大幅提升了模型性能。微调利用了来自 Stanford-Alpaca 的独特数据集,其中包含:
* 179 个指导问题
* 174 种不同类型的数据集
此数据集提供逐步指导、详细解释和额外知识,即使仅使用 1000 条微调数据,也能显著增强模型能力。
凭借52,000个数据集和4块A100 GPU,LLaMA-7B在短短一天内完成了训练,达到与text-davinci-003相当的性能。该模型采用自我指导方法,不断学习和优化自身,使其具备先进的文本生成和理解能力。
成本对比:
* ChatGPT API:500 美元
* 4 块 A100 GPU,24 小时训练:100 美元
深入了解模型训练和微调的成本:
训练模型需要大量的资源和时间,通常是成本不菲且持续的过程。虽然 LoRA 微调可以用更少资源获得较好效果,但仍需要考虑设备和资源成本。
常用AI计算GPU卡规格比较
大型语言模型 (LLM) 领域由 ChatGPT 主导,但其应用开发成本很高。为了提高成本效益,建议使用 OpenAI 或 Azure API。通过这种方法,企业可以利用 LLM 的强大功能,同时最大限度地降低训练和执行费用。
数据无法上云或需调整时,开源模型(如 LLaMA、Mistral、Gemma)提供了本地执行解决方案。这些模型可用于重新训练或微调,以符合特定需求,为各种应用程序提供灵活性。
在运行LLM模型时,CPU/RAM/SSD的级别次要,最关键的是GPU。目前,H100/A100有钱也买不到。然后是工作站级别的GPU,如RTX-6000/5000/4500/4000/4000 SFF等,RTX-6000有48GB内存,不需要量化就可以直接运行13B大小的模型。再次下来是普通玩家勉强买得起的消费级显卡4090,价格为1万6-1万9人民币。如果一张不够,想要体验团结就是力量,可以考虑购买工作站级别的高端主机,可以插入四张双宽度显卡。
释放LLM潜能需要强大的经济基础。对于LLaMA 2模型,不同GPU性能的影响值得考虑。升级到双GPU可能显著提升性能,具体提升取决于GPU类型。
先看不同型号单一 GPU 跑 LLM 的效能数字:

表格有附不同 GPU 跑 llama2-7b-chat 及 llama2-13b-chat 模型的效能数字,单位为 Tokens/s。CPU 只能用惨烈形容,不到 2。4090 跑 7B 模型数字挺漂亮,甚至赢过 A100。有趣的是 8 bit 量化版的数很难看,4 bit 量化版也输给 16 bit,关于这点网路上讨论不少,我的理解这是用动态量化节省记忆体的代价。参考:2-3x slower is to be expected with load_in_4bit (vs 16-bit weights), on any model -- that's the current price of performing dynamic quantization。
探索多 GPU 推理加速潜力
一项研究显示,使用 3090 GPU 运行 LLaMA 2 7B 模型时,添加额外 GPU 可显着提升推理速度。

批次模式执行可显着提升性能,克服GPU通信成本带来的负面影响。增加GPU数量至5张3090时,批次模式下性能持续增长,而单纯推理则出现下降趋势。
更多:
选择华硕龙芯主板的理由:从支持国产芯片到性价比考量
探秘Nvidia开创性的DGX-GB200机架系统背后的创新
浙江大学研究团队如何在消费级GPU上实现对100B模型微调
女科学家提出GaLore:为消费级GPU上高效训练LLM铺平道路
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-




