报告出品方:中信建投
以下为报告原文节选
------
一、国内 AI 产业有望迎来跨越式发展
1.1 海外 AI 产业蓬勃发展
OpenAI 于 2023 年 3 月发布 GPT-4,谷歌于 2023 年 12 月发布 Gemini 大模型,并在近期推出 Gemini1.5 pro以及开源模型 Gemma,大模型能力持续迭代升级。伴随大模型能力的提升,海外 AI 应用蓬勃发展,云大厂比如微软推出 copilot、bing AI 等,谷歌推出 workspece、聊天机器人 Gemini 等外,B 端垂直企业服务、C 端应用等层出不穷。据 SensorTower 数据显示,2023 年,AI 应用年度下载量和内购收入分别上涨 60%和 70%,超过21 亿次和 17 亿美元(其中 2023H1 下载量突破 3 亿次)。英伟达提到,FY24 全年估计 40%收入来自 AI 推理端。
近期 openai sora、谷歌 Genie 发布,视频应用领域 AI 能力边界大幅跃升,AI 向基础世界模型、AGI 领域迈进。

从支撑 AI 发展的基础设施角度,不管是从英伟达、超微电脑、台积电、AMD 等硬件厂商的业绩和指引,还是从海外云厂商的 capex 投入,都印证海外 AI 产业的持续提速。
英伟达 FY24Q3、FY24Q4 业绩持续超过分析师预期,主要来自 AI 带动数据中心业务超预期带动,英伟达对下一季度指引乐观,预计 FY25Q1 收入 240 亿美元,同样超过分析师预期的 219 亿美元。超微电脑 FY24Q2营收超预期,FY24Q3 预计净销售额在 37 亿美元至 41 亿美元之间,远超市场预期,主要得益于 AI 系统强劲需求的驱动。台积电预计未来几年 AI 相关业务 CAGR 将达 50%,上调远期 AI 营收占比目标,预期 2027 年 AI营收占比达到高双位数(high teen),此前预期为低双位数(low teen)。AMD 在 2023 年 12 月上调加速器规模预测,预计到 2027 年,人工智能加速器的整体市场规模将达 4000 亿美元,CAGR 达到 70%,此前 2023年 8 月 AMD 预计 2027 年人工加速器行业规模为 1500 亿美元。
海外云厂商对 AI 投入展望持续乐观。谷歌指引 2024 年资本支出将明显增长。meta 指引 2024 年资本开支300 亿美元-370 亿美元,上限上调 20 亿美元。微软表示,基于对云和人工智能基础设施的投资、第三方产能合同的交付转移到下一季度,预计下一季度资本支出将环比大幅增加。亚马逊预计 2024 年资本支出将同比增加。

1.2 国内大模型基本实现能力边界突破
国内厂商也加快研发节奏,纷纷发布大模型产品,并不断持续迭代更新。2023 年 3 月-6 月间,包括百度、清华智谱、阿里巴巴、科大讯飞、百川智能等厂商相继发布自己的大模型产品,后续持续迭代更新,在 2023 年9 月、10 月前后发布重要更新,提升模型能力。国内领先的大模型基本在 2023 年 10 月至 11 月实现了能力边界的突破,实现看齐甚至部分能力超越 ChatGPT,并且后续在持续的进一步迭代升级。随着国内大模型能力的提升,AI 应用预计 2024 年也将迎来加速落地。

参考国内中文模型评测机构 SuperCLUE 发布中文大模型基准测评,对比来看,国内大模型厂商的能力在快速提升。2023年5月,国内大模型总体与 GPT3.5有约20分的差距,国产得分最高的星火认知大模型总分 53.58,而 GPT3.5 为 66.18。2023 年 11 月,国产头部大模型已基本完成对 GPT3.5 的总分超越,与 GPT4-Turbo 的差距也在快速缩小,74.02 分的文心一言 4.0、72.88 分的 Moonshot 等大模型超越了 59.39 分的 GPT3.5,与 89.79 分的 GPT4 仍有距离。SuperCLUE 最新的 2024 年 2 月测评结果显示,国产第一梯队大模型已将与 GPT4.0 的得分差距拉至 10 分以内,其中文心一言 4.0 总分 87.75,GLM-4 总分 86.77,通义千问 2.1 总分 85.7、Baichaun3 总分 82.59、Moonshot(kimichat)总分 82.37、讯飞星火 V3.5 总分 81.01,而 GPT4.0-Turbo 总分 92.71、GPT3.5总分 64.34。

近期 Kimi 支持 200 万字超长文本,用户数激增,国内模型的能力和应用的展望进一步乐观。2024 年 3 月18 日,月之暗面宣布 Kimi 智能助手已支持 200 万字超长无损上下文(2023 年 10 月刚发布时,Kimi 可支持的无损上下文输入长度为 20 万字),在长文本处理能力上取得了突破性进展,并于即日起开启产品内测。Kimi的月活用户从 2023 年底的 50 万左右增至接近 300 万,网页端的日活从 3 月 9 日的 12 万多增至 14 日的 35 万左右,3 月 21 日,Kimi 因访问量暴增而疑似宕机。
1.3 国家大力推动 AI 建设与应用落地
2024 年 2 月 19 日,国务院国资委召开中央企业人工智能专题推进会。会议认为,加快推动人工智能发展,是国资央企发挥功能使命,抢抓战略机遇,培育新质生产力,推进高质量发展的必然要求。中央企业要主动拥抱人工智能带来的深刻变革,把加快发展新一代人工智能摆在更加突出的位置,不断强化创新策略、应用示范和人才聚集,着力打造人工智能产业集群,发挥需求规模大、产业配套全、应用场景多的优势,带头抢抓人工智能赋能传统产业,加快构建数据驱动、人机协同、跨界融合、共创分享的智能经济形态。会议强调,中央企业要把发展人工智能放在全局工作中统筹谋划,深入推进产业焕新,加快布局和发展人工智能产业。要夯实发展基础底座,把主要资源集中投入到最需要、最有优势的领域,加快建设一批智能算力中心,进一步深化开放合作,更好发挥跨央企协同创新平台作用。开展 AI+专项行动,强化需求牵引,加快重点行业赋能,构建一批产业多模态优质数据集,打造从基础设施、算法工具、智能平台到解决方案的大模型赋能产业生态。10 家头部中央企业签订倡议书,表示将主动向社会开放人工智能应用场景。

二、国产算力基础设施迎来发展机会
2.1 AI 发展需要强大算力基础设施支撑
大语言模型所使用的数据量和参数规模呈现“指数级”增长,带来智能算力需求爆炸式增长。OpenAI 在2018 年推出的 GPT 参数量为 1.17 亿,预训练数据量约 5GB,而 GPT-3 参数量达 1750 亿,预训练数据量达 45TB,而当前来看,大模型参数进一步提升,已经达到万亿级,并持续迭代发展。训练阶段算力需求与模型参数数量、训练数据集规模等有关,参考天翼智库测算信息,根据 OpenAI 发布的论文《Scaling Laws for Neural Language Models》数据,训练阶段算力需求=6×模型参数数量×训练集规模,GPT-3 模型参数约 1750 亿个,预训练数据量为 45TB,折合成训练集约为 3000 亿 tokens,GPT-3 的总算力消耗约为 3646PFLOPS-day,实际运行中,GPU算力除用于模型训练,还需处理通信、数据读写等任务,对算力会有更大消耗。面向推理侧算力需求,参考天翼智库测算信息,根据 OpenAI 发布的论文《Scaling Laws for Neural Language Models》数据,平均每 1000 个 token对应 750 个单词,推理阶段算力需求=2×模型参数数量×token 数。ChatGPT 上市仅 5 天就突破 100 万用户,两个月内用户就突破 1 亿大关,现在每周活跃用户维持在亿量级。假设按照 1 亿的 ChatGPT 的活跃用户数、日活跃用户 2000 万人,平均每位用户单次查询对应 1000 个 token,每天查询 10 次,GPT-3 模型每日对话产生推力算力需求为 810PFLOPS-day,同样考虑到有效算力比率,实际运行中需要更大算力支撑。

人工智能的发展将带动算力规模高速增长,继而刺激算力基础设施的需求。根据中国信通院数据,2022 年全球计算设备算力总规模达到 906EFLOPS,预计未来 5 年全球算力规模增速将超 50%。IDC 数据显示,2022年中国通用算力和智能算力规模分别达 54.5EFLOPS(基于 FP64)和 259.9EFLOPS(基于 FP16),2027 年通用算力和智能算力规模将达到 117.3EFLOPS 和 1117.4EFLOPS,预估未来 5 年复合增长率 16.6%和 33.9%。

运营商加大智能算力基础设施投入。中国移动 2024 年计划总体资本开支 1730 亿元同比下降 4%,用于算力资本开支计划 475 亿元同比增长 21%。中国电信 2024 年计划总体资本开支 960 亿元同比下降 4%,用于产业数字化资本开支 370 亿元同比增长 4%,用于云/算力投资 180 亿元。中国联通 2024 年计划总体资本开支 650 亿元同比下降 12%,公司表示投资重点将由稳基础的联网通信业务转向高增长的算网数智业务。在相关 AI 服务器采购方面,2023 年 8 月,中国电信启动 2023-2024 年 AI 算力服务器集采,整体采购规模为 4175 台,中标总价超84 亿元。2023 年 9 月,中国移动启动了 2023 年至 2024 年新型智算中心(试验网)采购项目,采购人工智能服务器(2454 台)、数据中心交换机(204 套)及其配套产品等,总价约 33 亿元(标包 4-12 总额,标包 1-3 采购失败)。2024 年 3 月,中国联通发布 2024 年人工智能服务器集中采购项目资格预审公告,涵盖人工智能服务器合计 2503 台,关键组网设备 RoCE 交换机合计 688 台。同时,三大运营商也在积极加快智算中心等基础设施的建设。

国内互联网厂商资本开支呈现回暖态势。2023年全年腾讯资本开支为238.93亿元,同比增长32.6%,2023Q1、2023Q2、2023Q3、2023Q4 腾讯的资本开支分别为 44.11、39.35、80.05、75.24 亿元,分别同比-36.7%、+31.1%、+236.8%、+33.1%。阿里巴巴在 2023 年前三季度单季资本开支同比均呈现下滑,2023Q1、2023Q2、2023Q3 阿里巴巴的资本开支分别为 25.13、60.07、41.12 亿元,分别同比-72.7%、-46.0%、-62.5%,2023Q4 同比转为正增长,资本开支为 72.86 亿元,同比增长 25.8%。

英伟达持续升级 GPU,算力持续提升。2024 年 3 月 GTC 上,英伟达发布 GB200 超级芯片,采用 Blackwell架构,采用台积电的 4 纳米(4NP)工艺,整合两个独立制造的裸晶(Die)形成一个 Blackwell GPU,两个 Blackwell GPU 与一个 GraceCPU 结合成为 GB200 superchip。Blackwell GPU 共有 2080 亿个晶体管,上一代 H100 只有 800亿晶体管,整体性能明显提升。一个 GB200 NVL72 就最高支持 27 万亿参数的模型。英伟达表示,过去在 90天内训练一个 1.8 万亿参数的 MoE 架构 GPT 模型,需要 8000 个 Hopper 架构 GPU,15 兆瓦功率,如今同样给90 天时间,在 Blackwell 架构下只需要 2000 个 GPU,以及 1/4 的能源消耗。
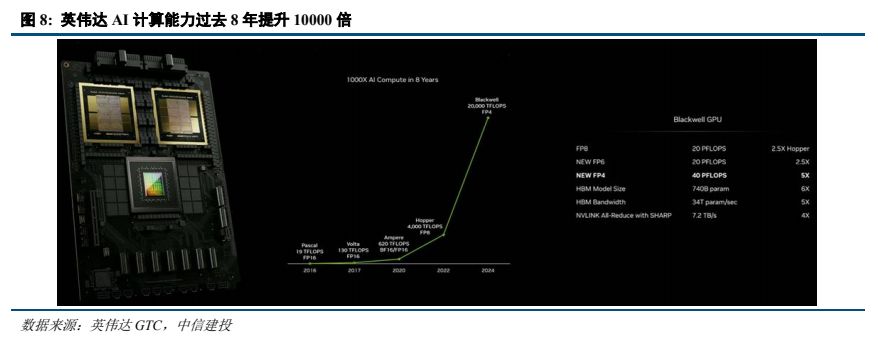
2.2 禁运持续升级,国产化大势所趋
美国对中国先进芯片进口限制持续升级。2023 年 10 月,美国颁布新的半导体出口限制,对芯片算力和性能密度做了更严格的规定,A100/A800、H100/H200/H800、L4、L40s 均不满足出口条件。在 2022 年 8 月,美国首次针对中国实施大规模芯片出口制裁,停止出口 A100 和 H100 两款芯片和相应产品组成的系统。本次制裁主要限制总计算性能(算力*位宽)≥4800 且互联带宽≥600GB/s 的高端 AI 芯片出口,在制裁后,英伟达为中国重新设计了 A800 和 H800 两款“阉割版”芯片,主要在互联速率和双精度计算性能上做了限制。2023 年 10月升级版本的芯片禁令加大了打击力度,性能满足以下条件均受出口管制:(1)总计算能力 TPP(算力*位宽)超过 4800 的芯片;(2)TPP 超过 1600 且 PD(TPP/芯片面积)超过 5.92 的芯片;(3)2400≤TPP<4800,且 1.6≤PD<5.92的芯片;(4) 1600≤TPP,且 3.2≤PD<5.92 的芯片。在此要求下,A100/A800、H100/H200/H800、L4、L40s 均不满足出口条件,英伟达只能全方位削弱芯片算力,向中国提供 H20、L20、L2 芯片。而近日美国政府再次升级对华半导体出口管制措施。参考钛媒体信息,北京时间 2024 年 3 月 30 日凌晨,美国商务部下属的工业与安全局(BIS)发布“实施额外出口管制”的新规措施,修订了 BIS 于 2022、2023 年 10 月制定的两次出口限制新规,全面限制英伟达、AMD 以及更多更先进 AI 芯片和半导体设备向中国销售,此次新规中,BIS 删除和修订了部分关于美国、中国澳门等地对华销售半导体产品的限制措施,包括中国澳门和 D:5 国家组将采取“推定拒绝政策”,并且美国对中国出口的 AI 半导体产品将采取“逐案审查”政策规则,包括技术级别、客户身份、合规计划等信息全面查验。
国内算力自立自强是必然趋势。此前国内对英伟达芯片依赖度较高,2022 年,中国 AI 加速卡市场中,英伟达占据 85%的出货量,而国产芯片中,华为、百度昆仑、寒武纪、燧原各自占比 10%、2%、1%、1%。IDC数据显示,2023 年上半年,中国加速芯片的市场规模超过 50 万张。从技术角度看,GPU 卡占有 90%的市场份额,从品牌角度看,中国本土 AI 芯片品牌出货超过 5 万张,占比整个市场 10%左右的份额。当前禁运持续升级,但是国内人工智能发展的趋势和力度并不会因此而发生变化,相反我们更需要重视人工智能的发展,美国对于中国先进芯片的限制升级可能将进一步推动我国高水平科技自立自强的步伐。
预计未来国产化比例将大幅提升,短期由于国内算力芯片供需的缺口,包括 H20 等在内的海外芯片也预计对国内算力行业进一步形成补充。H20 芯片在单卡性能上不具备突出优势,但利用 NVLINK 技术集群性能提升。

2.3 当前国产芯片性能或已接近 A100,或优于 H20
目前华为海思、寒武纪、平头哥、壁仞科技、百度昆仑芯、燧原科技、海光等国内 GPU 厂商均已推出用于训练、推理场景的算力芯片,并且持续迭代升级,性能在不断提升。而生态方面,国内 GPU 厂商也推出软件开发包,支持 TensorFlow、Pytorch 等主流框架,并且基于自身的软件建立了开发平台,吸引更多的开发者建立完善生态体系。
国产头部芯片单芯片算力或已接近 A100,或优于 H20。以 FP16 精度为例,国产芯片中华为昇腾 910 算力为 256TFLOPS,略低于 A100 的 312TFLOPS,相较于 H100 的 1513TFLOPS 有较大差距,但强于 H20 的148TFLOPS。此外,平头哥含光 800 在 INT8 精度,壁仞科技 BR100 在 FP32 精度均超过 A100。在单颗芯片峰值算力上,国产芯片已经满足大规模使用条件。随着国产芯片能力的提升,国内算力产业发展将进一步提速。

三、国产算力产业链环节梳理
3.1 服务器:AI 高增,国产算力芯片发展或带来格局生变
通用服务器相对疲软,AI 服务器高增。受经济持续疲软、高通胀、企业资本支出缩减、去库存等影响,2023年服务器市场整体出货量不及预期。IDC 数据显示,2023 年第三季度,全球服务器销售额为 315.6 亿美元,同比增长 0.5%;出货量为 306.6 万台,同比下降 22.8%;预计 2023 年全球服务器市场规模微幅增长至 1284.71 亿美元,增长率 4.26%;预计未来四年的年增长率预计分别为 11.8%、10.2%、9.7%和 8.9%。到 2027 年,市场规模预计将达到 1891.39 亿美元。Trendforce 数据显示,预计 2023 年中国服务器需求将同比下降 9.7%。通用服务器受 AI 需求暴涨、全球整机支出向 AI 倾斜影响,通用服务器市场被进一步压缩。IDC 数据,2023 年上半年全球通用服务器市场和 CPU 市场规模均出现下滑,其中二季度 CPU 市场同比下滑 13.4%。AI 服务器高增。IDC预计,全球人工智能硬件市场(服务器)规模将从 2022 年的 195 亿美元增长到 2026 年的 347 亿美元,年复合增长率达 17.3%。IDC 预计,2023 年中国人工智能服务器市场规模将达到 91 亿美元,同比增长 82.5%,2027年将达到 134 亿美元,五年年复合增长率达 21.8%。

AI 服务器占比提升和国产化率提升,国内服务器厂商竞争格局或存变数。此前服务器竞争格局中,浪潮、新华三等厂商份额较高。2022 年中国服务器市场份额来看,浪潮、新华三、超聚变、宁畅、中兴位列前五,份额分别为 28%、17%、10%、6%、5%。2022 年我国 AI 服务器市场份额来看,浪潮、新华三、宁畅、安擎、坤前、华为位列前六,份额分别为 47%、11%、9%、7%、6%、6%。随着国产 AI 芯片占比的提升,AI 服务器供应商格局或存在变化。当前昇腾在国产 GPU 中性能较为领先,国内深度参与华为昇腾算力服务器供应的厂商有望更为受益,具体可参考中国电信、中国移动等中标候选人情况。未来随着国内其他厂商 GPU 新产品的推出以及推理等场景的丰富,国内 GPU 生态也有望更加丰富,进一步可能存在新的变化。
国产化的大趋势下,通用服务器市场格局或同样产生变化。国产化 CPU 服务器中,X86 解决方案目前有海光、兆芯、澜起,并以海光为主;ARM 解决方案有华为鲲鹏、飞腾等。中国移动 2021-2022 年 PC 服务器集采中,采用海光芯片的服务器 59982 台占比 20.90%,采用鲲鹏芯片的服务器 58901 台,占比 20.53%,合计整体国产服务器占比高达 41.43%。近期中国移动 2024 年 PC 服务器产品集采项目中,ARM 服务器对比 X86 服务器的招投标数量达 1.71:1,ARM 服务器份额超越 X86。





3.2 交换机:以太网高速产品逐步成熟,高端产品预计实现快速增长
AI 部署需要更大的网络容量,数据中心交换带宽当前处于每两年翻一番的速度快速增长。2022 年 8 月,博通发布 Tomahawk 5,交换带宽提升至 51.2T,serdes 速率达到 100Gb/sec,单通道速率最高达到 800G,可以支持 800G、1.6T 网络部署。下一代交换机带宽将向 102.4T 升级,进一步为 1.6T、3.2T 网络奠定基础。
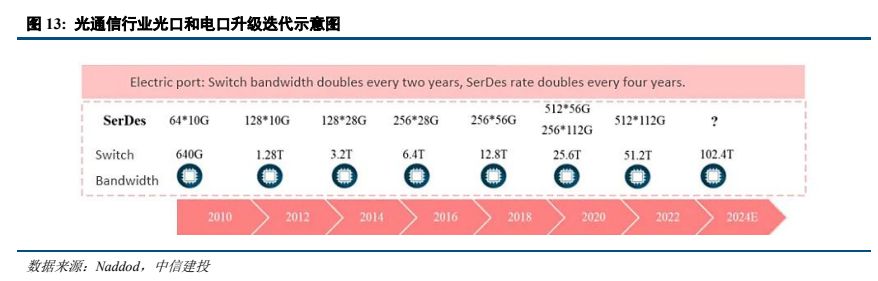
受益于 AI 发展的带动,高端交换机需求快速增长。根据 IDC 数据,2023 年全球以太网交换机收入达到 442亿美元,同比增长 20.1%,其中数据中心部分的市场收入同比增长 13.6%,占整个市场收入的 41.5%,2023 年全年,数据中心部分 200/400 GbE 交换机的收入同比增长 68.9%。工业富联 2023 年年报显示,800G 高速交换机已进行 NPI,预计 2024 年将开始上量并贡献营业收入,预计 2024 年将是 800 Gbps 端口部署的重要一年,预计到 2027 年 400 Gbps/800 Gbps 的端口数量渗透率将达到 40%以上。国内由于政企等需求较弱、高端 AI 算力芯片供应短缺等影响,IDC 数据,2023 年中国以太网交换机收入同比下降 4%(2022 年规模近 50 亿美元),但2023 年四季度同比增长了 9.1%,随着国内算力建设,预计国内高端交换机渗透提升将加速,拉动整体需求。

Infiniband 当前份额提升。AI 高性能计算场景对于网络性能要求进一步提升。InfiniBand 最重要的一个特点是采用 RDMA 协议(远程直接内存访问),从而实现低时延。相较于传统 TCP/IP 网络协议, RDMA 可以让应用与网卡之间直接进行数据读写,无需操作系统内核的介入,从而使得数据传输时延显著降低。InfiniBand技术以端到端流量控制为网络数据包收发的基础,能够确保无拥塞发出报文,从而大幅降低规避丢包所导致的网络性能下降的风险。并且 InfiniBand 引入 SHARP 技术(可扩展分层聚合和归约协议),使得系统能够在转发数据的同时在交换机内进行计算,以降低计算节点间进行数据传输的次数,从而大幅提升计算效率。InfiniBand作为一个用于高性能计算的网络通信标准,其优势在于高吞吐和低延迟,可以用于计算机和计算机、计算机和存储以及存储之间的高速交换互连,InfiniBand 目前传输速度达到 400Gb/s。根据技术发展路线图,2024 年 IBTA计划推出 XDR 产品 ,四通道对应速率 800Gb/s,八通道对应速率是 1600Gb/s,并将于 2 年后发布 GDR 产品,四通道速率达 1600Gb/s。当前在 IB 市场上,主要是 Nvidia(收购的 Mellanox 公司)和 Intel(收购的 Qlogic 公司)两大玩家。得益于更优秀的性能以及英伟达的一体化销售战略,目前 Infiniband 在 AI 市场处于领先地位。
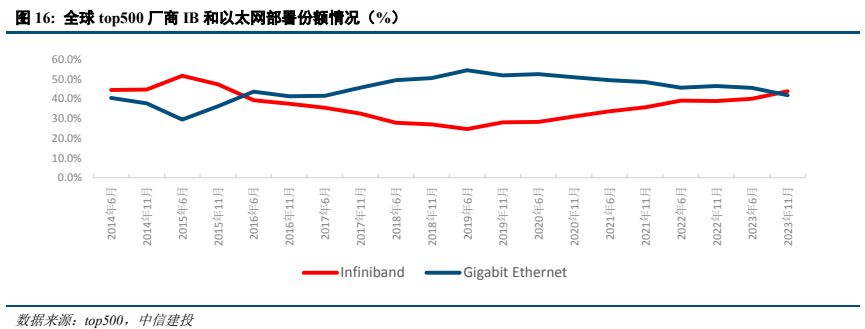
以太网也持续提升性能支撑高性能计算场景。以太网也有相关 RDMA 技术标准,尤其是 RoCE(RDMA over Converged Ethernet)的出现和成熟,RDMA 在基于以太网的数据中心得到规模应用。IBTA 在 2010 年发布了RoCE 协议技术标准,在 2014 年发布了 RoCEv2 协议技术标准,经过多年的发展,RoCE 已经具备路由能力,且在性能表现提升明显。2022 年 11 月,Broadcom 和 Arista 宣布了针对基于融合以太网 (RoCE) 的远程直接内存访问(RDMA)优化的开放式端到端网络解决方案。2023 年 5 月,英伟达推出 NVIDIA Spectrum-X,交换带宽 51.2T,通过 RoCE 扩展提升 NVIDIA 集体通信库性能。但 RDMA 原本设计用于连接较小规模的节点,其设计本身是为了高性能低延时,这使得它对网络有很高的要求,特别是网络不能丢包,否则性能下降会很大,这对底层网络硬件提出了更大的挑战,同时也限制了 RDMA 的网络规模。另外 RDMA 通过硬件实现高带宽低时延,对 CPU 的负载很小,硬件的使用和管理较为复杂。面对 AI 高性能计算场景,全球成立超以太网联盟 UEC、中国移动推动全调度以太网 GSE,进一步提升以太网传输性能。2023 年 7 月,硬件设备厂商博通、AMD、思科、英特尔、Arista、Eviden、HP 和超大规模云厂商 Meta、微软共同创立 UEC(Ultra Ethernet Consortium,超以太网联盟),在物理层、链路层、传输层和软件方面致力于开发开放的“Ultra Ethernet”解决方案,打造高性能以太网,以新形式进行传输层处理,在非无损网络的情况下也可实现以太网性能提升,较 RDMA 更灵活。
2023 年 8 月,中国移动研究院携手 30 余家合作伙伴启动“全调度以太网(GSE)推进计划”,基于逐包的以太网转发和全局调度机制,突破传统无损以太性能瓶颈,2023 年 9 月,中国移动研究院携手合作伙伴发布业界首款“全调度以太网(GSE)”样机。综合来看,以太网支撑高性能计算场景已经逐步得到验证。

CPO、硅光等技术将在高端交换机中使用。共封装光学(CPO)是业界公认的未来更高速率光通信的主流产品形态之一,可显著降低交换机的功耗和成本。随着交换机带宽从最初的 640G 升级到 51.2T,Serdes 速率不断升级叠加数量的持续增加,交换机总功耗大幅提升约 22 倍,而 CPO 技术能够有效降低 Serdes 的功耗,因此在 51.2T 及以上带宽交换机时代,CPO 有望实现突破。硅光芯片是 CPO 交换机中光引擎的最佳产品形态,有望在未来得到广泛应用。海外博通、英特尔、Meta 等厂商在 CPO 交换机产品均有布局。新华三 2023 年 6 月首发51.2T 800G CPO 硅光数据中心交换机,融合 CPO 硅光技术、液冷散热设计、智能无损等技术,满足智算网络对高吞吐、低时延、绿色节能的需求,其基于数据中心 RoCE 全业务场景的解决方案也已经逐步商用落地。锐捷网络也已经推出 51.2T 硅光 NPO 交换机和 25.6T 硅光 NPO 交换机等产品。

国内 AI 服务器部署规模的增加、国内 GPU 芯片的持续迭代、以太网高速交换机方案的成熟,将利好国内交换机厂商参与国内算力建设,国内交换机厂商 400G、800G 相关订单预计将实现高速增长。交换机具备技术壁垒,国内厂商已推出高端产品应对 AI 需求。全球来看,全球以太网交换机领域,思科份额第一,此外 Arista、华为、HPE 等份额居前。国内市场来看,参考 IDC 数据,2023 年一季度,新华三(34.5%)、华为(30.9%)、锐捷(14.9%)位列国内前三。目前国内多家交换机厂商均推出了 51.2T 交换机,锐捷在 2022 年 3 月推出了 51.2T硅光 NPO 冷板式液冷交换机,新华三在 2023 年 6 月推出了 51.2T 800G CPO 硅光数据中心交换机(H3C S9827系列),浪潮在 2023 年 11 月推出了旗舰级 51.2T 高性能交换机(SC8670EL-128QH)。
互联网厂商加大自研,或引起格局新的变化。阿里、腾讯、字节在 2023 年均发布了自研的 51.2T 白盒交换机并宣布规模商用,分别是阿里的“白虎”、腾讯的 TCS9500 和字节跳动的 B5020。互联网厂商的强势入局或带来市场份额新的变化。

以太网交换设备由以太网交换芯片、CPU、PHY、PCB、接口/端口子系统等组成,高速交换机需求也将直接拉动高速交换芯片需求。全球以太网交换芯片主要以博通、美满、高通、华为、瑞昱、英伟达、英特尔等厂商为主,其中思科、华为以自用芯片为主。国内交换机市场以博通、美满、瑞昱、华为、盛科通信等厂商参与为主,参考盛科通信招股书,2020 年中国商用以太网交换芯片市场以销售额口径统计,份额排名前三的供应商合计占据了 97.8%的市场份额,其中博通、美满和瑞昱分别以 61.7%、20.0%和 16.1%的市占率排名前三位,盛科通信的销售额排名第四,占据 1.6%的市场份额。国内厂商在高速交换芯片领域与海外仍有差距,国产化趋势下,国内厂商也正在加速追赶,盛科通信在招股说明书中提到,公司拟于 2024 年推出 Arctic 系列,交换容量最高达到 25.6Tbps,支持最大端口速率 800G,面向超大规模数据中心,交换容量基本达到头部竞争对手水平。

--- 报告摘录结束 更多内容请阅读报告原文 ---
报告合集专题一览 X 由【报告派】定期整理更新
(特别说明:本文来源于公开资料,摘录内容仅供参考,不构成任何投资建议,如需使用请参阅报告原文。)
精选报告来源:报告派科技 / 电子 / 半导体 /
人工智能 | Ai产业 | Ai芯片 | 智能家居 | 智能音箱 | 智能语音 | 智能家电 | 智能照明 | 智能马桶 | 智能终端 | 智能门锁 | 智能手机 | 可穿戴设备 |半导体 | 芯片产业 | 第三代半导体 | 蓝牙 | 晶圆 | 功率半导体 | 5G | GA射频 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圆 | 封装封测 | 显示器 | LED | OLED | LED封装 | LED芯片 | LED照明 | 柔性折叠屏 | 电子元器件 | 光电子 | 消费电子 | 电子FPC | 电路板 | 集成电路 | 元宇宙 | 区块链 | NFT数字藏品 | 虚拟货币 | 比特币 | 数字货币 | 资产管理 | 保险行业 | 保险科技 | 财产保险 |

